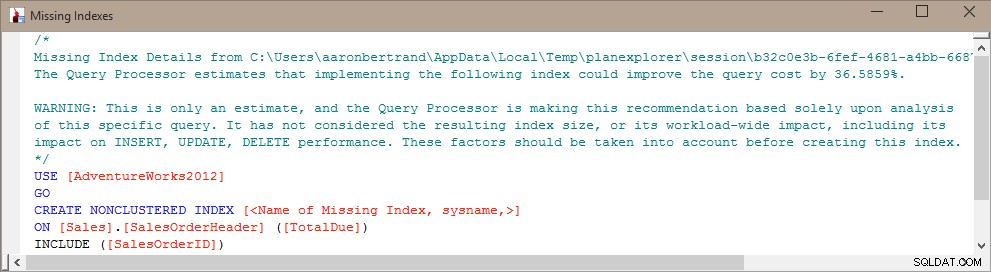
Kevin Kline (@kekline) y yo recientemente llevamos a cabo un seminario web de ajuste de consultas (bueno, uno en una serie, en realidad), y una de las cosas que surgieron es la tendencia de la gente a crear cualquier índice faltante que SQL Server les dice que será algo bueno™ . Pueden obtener información sobre estos índices faltantes del Asesor de ajuste del motor de base de datos (DTA), los DMV de índices faltantes o un plan de ejecución que se muestra en Management Studio o Plan Explorer (todos los cuales solo transmiten información desde exactamente el mismo lugar):
El problema de crear este índice a ciegas es que SQL Server ha decidido que es útil para una consulta en particular (o un puñado de consultas), pero ignora total y unilateralmente el resto de la carga de trabajo. Como todos sabemos, los índices no son "gratuitos":usted paga por los índices tanto en el almacenamiento sin procesar como en el mantenimiento requerido en las operaciones DML. Tiene poco sentido, en una carga de trabajo de escritura intensa, agregar un índice que ayude a que una sola consulta sea un poco más eficiente, especialmente si esa consulta no se ejecuta con frecuencia. Puede ser muy importante en estos casos comprender su carga de trabajo general y lograr un buen equilibrio entre hacer que sus consultas sean eficientes y no pagar demasiado por eso en términos de mantenimiento del índice.
Entonces, una idea que tuve fue "mezclar" la información de los DMV de índice faltantes, las estadísticas de uso del índice DMV e información sobre los planes de consulta, para determinar qué tipo de saldo existe actualmente y cómo agregar el índice podría funcionar en general.
Índices faltantes
Primero, podemos echar un vistazo a los índices faltantes que actualmente sugiere SQL Server:
SELECT d.[object_id], s = OBJECT_SCHEMA_NAME(d.[object_id]), o = OBJECT_NAME(d.[object_id]), d.equality_columns, d.inequality_columns, d.included_columns, s.unique_compiles, s.user_seeks, s.last_user_seek, s.user_scans, s.last_user_scan INTO #candidates FROM sys.dm_db_missing_index_details AS d INNER JOIN sys.dm_db_missing_index_groups AS g ON d.index_handle = g.index_handle INNER JOIN sys.dm_db_missing_index_group_stats AS s ON g.index_group_handle = s.group_handle WHERE d.database_id = DB_ID() AND OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0;
Esto muestra la(s) tabla(s) y la(s) columna(s) que habrían sido útiles en un índice, cuántas compilaciones/búsquedas/escaneos se habrían utilizado y cuándo ocurrió el último evento de este tipo para cada índice potencial. También puede incluir columnas como s.avg_total_user_cost y s.avg_user_impact si quieres usar esas cifras para priorizar.
Planificar operaciones
A continuación, echemos un vistazo a las operaciones utilizadas en todos los planes que hemos almacenado en caché contra los objetos que han sido identificados por nuestros índices faltantes.
CREATE TABLE #planops
(
o INT,
i INT,
h VARBINARY(64),
uc INT,
Scan_Ops INT,
Seek_Ops INT,
Update_Ops INT
);
DECLARE @sql NVARCHAR(MAX) = N'';
SELECT @sql += N'
UNION ALL SELECT o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
FROM
(
SELECT o = ' + RTRIM([object_id]) + ',
i = ' + RTRIM(index_id) +',
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Scan'''''
+ ' or @LogicalOp = ''''Clustered Index Scan'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Seek_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Seek'''''
+ ' or @LogicalOp = ''''Clustered Index Seek'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Update_Ops = p.query_plan.value(''count(//Update/Object[@Index='''''
+ QUOTENAME(name) + '''''])'', ''int'')
FROM sys.dm_exec_cached_plans AS pl
CROSS APPLY sys.dm_exec_query_plan(pl.plan_handle) AS p
WHERE p.dbid = DB_ID()
AND p.query_plan IS NOT NULL
) AS x
WHERE Scan_Ops + Seek_Ops + Update_Ops > 0'
FROM sys.indexes AS i
WHERE i.index_id > 0
AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = i.[object_id]);
SET @sql = ';WITH xmlnamespaces (DEFAULT '
+ 'N''https://schemas.microsoft.com/sqlserver/2004/07/showplan'')
' + STUFF(@sql, 1, 16, '');
INSERT #planops EXEC sp_executesql @sql; Un amigo en dba.SE, Mikael Eriksson, sugirió las siguientes dos consultas que, en un sistema más grande, funcionarán mucho mejor que la consulta XML / UNION que armé anteriormente, por lo que podría experimentar con esas primero. Su comentario final fue que "no es sorprendente que descubriera que menos XML es algo bueno para el rendimiento. :)". De hecho.
-- alternative #1
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
from
(
select o = i.object_id,
i = i.index_id,
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Scan", "Clustered Index Scan")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Seek_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Seek", "Clustered Index Seek")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Update_Ops = p.query_plan.value('count(//Update/Object[@Index = sql:column("i2.name")])', 'int')
from sys.indexes as i
cross apply (select quotename(i.name) as name) as i2
cross apply sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
where exists (select 1 from #candidates as c where c.[object_id] = i.[object_id])
and p.query_plan.exist('//Object[@Index = sql:column("i2.name")]') = 1
and p.[dbid] = db_id()
and i.index_id > 0
) as T
where Scan_Ops + Seek_Ops + Update_Ops > 0;
-- alternative #2
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o = coalesce(T1.o, T2.o),
i = coalesce(T1.i, T2.i),
h = coalesce(T1.h, T2.h),
uc = coalesce(T1.uc, T2.uc),
Scan_Ops = isnull(T1.Scan_Ops, 0),
Seek_Ops = isnull(T1.Seek_Ops, 0),
Update_Ops = isnull(T2.Update_Ops, 0)
from
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Scan_Ops = sum(case when t.LogicalOp in ('Index Scan', 'Clustered Index Scan') then 1 else 0 end),
Seek_Ops = sum(case when t.LogicalOp in ('Index Seek', 'Clustered Index Seek') then 1 else 0 end)
from (
select
r.n.value('@LogicalOp', 'varchar(100)') as LogicalOp,
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//RelOp') as r(n)
cross apply r.n.nodes('*/Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where t.LogicalOp in ('Index Scan', 'Clustered Index Scan', 'Index Seek', 'Clustered Index Seek')
and exists (select 1 from #candidates as c where c.object_id = i.object_id)
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T1
full outer join
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Update_Ops = count(*)
from (
select
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//Update') as r(n)
cross apply r.n.nodes('Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where exists
(
select 1 from #candidates as c where c.[object_id] = i.[object_id]
)
and i.index_id > 0
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T2
on T1.o = T2.o and
T1.i = T2.i and
T1.h = T2.h and
T1.uc = T2.uc;
Ahora en el #planops tabla tiene un montón de valores para plan_handle para que puedas ir e investigar cada uno de los planes individuales en juego contra los objetos que han sido identificados como carentes de algún índice útil. No lo vamos a usar para eso en este momento, pero puede cruzarlo fácilmente con:
SELECT OBJECT_SCHEMA_NAME(po.o), OBJECT_NAME(po.o), po.uc,po.Scan_Ops,po.Seek_Ops,po.Update_Ops, p.query_plan FROM #planops AS po CROSS APPLY sys.dm_exec_query_plan(po.h) AS p;
Ahora puede hacer clic en cualquiera de los planes de salida para ver qué están haciendo actualmente con sus objetos. Tenga en cuenta que algunos de los planes se repetirán, ya que un plan puede tener varios operadores que hacen referencia a diferentes índices en la misma tabla.
Estadísticas de uso del índice
A continuación, echemos un vistazo a las estadísticas de uso del índice, para que podamos ver cuánta actividad real se está ejecutando actualmente en nuestras tablas candidatas (y, en particular, las actualizaciones).
SELECT [object_id], index_id, user_seeks, user_scans, user_lookups, user_updates INTO #indexusage FROM sys.dm_db_index_usage_stats AS s WHERE database_id = DB_ID() AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = s.[object_id]);
No se alarme si muy pocos o ningún plan en el caché muestra actualizaciones para un índice en particular, aunque las estadísticas de uso del índice muestren que esos índices se han actualizado. Esto solo significa que los planes de actualización no están actualmente en caché, lo que podría deberse a una variedad de razones, por ejemplo, podría ser una carga de trabajo de lectura muy pesada y han caducado, o todos son únicos. usar y optimize for ad hoc workloads está habilitado.
Poniéndolo todo junto
La siguiente consulta le mostrará, para cada índice faltante sugerido, la cantidad de lecturas que un índice podría haber asistido, la cantidad de escrituras y lecturas que se han capturado actualmente en comparación con los índices existentes, la proporción de ellas, la cantidad de planes asociados con ese objeto y el número total de usos para esos planes:
;WITH x AS
(
SELECT
c.[object_id],
potential_read_ops = SUM(c.user_seeks + c.user_scans),
[write_ops] = SUM(iu.user_updates),
[read_ops] = SUM(iu.user_scans + iu.user_seeks + iu.user_lookups),
[write:read ratio] = CONVERT(DECIMAL(18,2), SUM(iu.user_updates)*1.0 /
SUM(iu.user_scans + iu.user_seeks + iu.user_lookups)),
current_plan_count = po.h,
current_plan_use_count = po.uc
FROM
#candidates AS c
LEFT OUTER JOIN
#indexusage AS iu
ON c.[object_id] = iu.[object_id]
LEFT OUTER JOIN
(
SELECT o, h = COUNT(h), uc = SUM(uc)
FROM #planops GROUP BY o
) AS po
ON c.[object_id] = po.o
GROUP BY c.[object_id], po.h, po.uc
)
SELECT [object] = QUOTENAME(c.s) + '.' + QUOTENAME(c.o),
c.equality_columns,
c.inequality_columns,
c.included_columns,
x.potential_read_ops,
x.write_ops,
x.read_ops,
x.[write:read ratio],
x.current_plan_count,
x.current_plan_use_count
FROM #candidates AS c
INNER JOIN x
ON c.[object_id] = x.[object_id]
ORDER BY x.[write:read ratio];
Si su proporción de escritura:lectura para estos índices ya es> 1 (¡o> 10!), Creo que da razón para hacer una pausa antes de crear ciegamente un índice que solo podría aumentar esta proporción. El número de potential_read_ops que se muestra, sin embargo, puede compensar eso a medida que el número aumenta. Si las potential_read_ops es muy pequeño, probablemente desee ignorar la recomendación por completo antes de siquiera molestarse en investigar las otras métricas, por lo que podría agregar un WHERE cláusula para filtrar algunas de esas recomendaciones.
Un par de notas:
- Estas son operaciones de lectura y escritura, no lecturas y escrituras medidas individualmente de páginas de 8K.
- La proporción y las comparaciones son en gran parte educativas; muy bien podría darse el caso de que 10 000 000 de operaciones de escritura afectaran a una sola fila, mientras que 10 operaciones de lectura podrían haber tenido un impacto sustancialmente mayor. Esto solo pretende ser una guía aproximada y asume que las operaciones de lectura y escritura se ponderan aproximadamente de la misma manera.
- También puede usar ligeras variaciones en algunas de estas consultas para averiguar, además de los índices faltantes que recomienda SQL Server, cuántos de sus índices actuales son un desperdicio. Hay muchas ideas sobre esto en línea, incluida esta publicación de Paul Randal (@PaulRandal).
Espero que eso le dé algunas ideas para obtener más información sobre el comportamiento de su sistema antes de que decida agregar un índice que alguna herramienta le indicó que creara. Podría haber creado esto como una consulta masiva, pero creo que las partes individuales le darán algunos agujeros de conejo para investigar, si así lo desea.
Otras notas
También es posible que desee ampliar esto para capturar las métricas de tamaño actual, el ancho de la tabla y la cantidad de filas actuales (así como cualquier predicción sobre el crecimiento futuro); esto puede darle una buena idea de cuánto espacio ocupará un nuevo índice, lo que puede ser una preocupación dependiendo de su entorno. Puedo tratar esto en una publicación futura.
Por supuesto, debe tener en cuenta que estas métricas son tan útiles como lo dicta su tiempo de actividad. Los DMV se borran después de un reinicio (y, a veces, en otros escenarios menos disruptivos), por lo que si cree que esta información será útil durante un período de tiempo más largo, puede que desee considerar tomar instantáneas periódicas.