En un mundo perfecto, no importaría qué sintaxis particular de T-SQL elegimos para expresar una consulta. Cualquier construcción semánticamente idéntica conduciría exactamente al mismo plan de ejecución física, con exactamente las mismas características de rendimiento.
Para lograrlo, el optimizador de consultas de SQL Server necesitaría conocer todas las equivalencias lógicas posibles (suponiendo que podamos conocerlas todas) y contar con el tiempo y los recursos para explorar todas las opciones. Dada la enorme cantidad de formas posibles en que podemos expresar el mismo requisito en T-SQL y la gran cantidad de transformaciones posibles, las combinaciones se vuelven rápidamente inmanejables para todos los casos, excepto para los más simples.
Un "mundo perfecto" con total independencia de sintaxis puede no parecer tan perfecto para los usuarios que tienen que esperar días, semanas o incluso años para compilar una consulta modestamente compleja. Por lo tanto, el optimizador de consultas se compromete:explora algunas equivalencias comunes y se esfuerza por evitar dedicar más tiempo a la compilación y optimización del que ahorra en tiempo de ejecución. Su objetivo se puede resumir en tratar de encontrar un plan de ejecución razonable en un tiempo razonable, mientras se consumen recursos razonables.
Un resultado de todo esto es que los planes de ejecución suelen ser sensibles a la forma escrita de la consulta. El optimizador tiene cierta lógica para transformar rápidamente algunas construcciones equivalentes ampliamente utilizadas en una forma común, pero estas habilidades no están bien documentadas ni (en absoluto) completas.
Ciertamente, podemos maximizar nuestras posibilidades de obtener un buen plan de ejecución escribiendo consultas más simples, brindando índices útiles, manteniendo buenas estadísticas y limitándonos a conceptos más relacionales (por ejemplo, evitando cursores, bucles explícitos y funciones no en línea), pero esto es no es una solución completa. Tampoco es posible decir que una construcción T-SQL siempre producir un mejor plan de ejecución que una alternativa semánticamente idéntica.
Mi consejo habitual es comenzar con el formulario de consulta relacional más simple que satisfaga sus necesidades, utilizando cualquier sintaxis de T-SQL que considere preferible. Si la consulta no cumple con los requisitos después de la optimización física (por ejemplo, la indexación), puede valer la pena tratar de expresar la consulta de una manera ligeramente diferente, manteniendo la semántica original. Esta es la parte difícil. ¿Qué parte de la consulta debería intentar reescribir? ¿Qué reescritura deberías probar? No existe una respuesta única y única para estas preguntas. Parte de esto se reduce a la experiencia, aunque saber un poco sobre la optimización de consultas y las funciones internas del motor de ejecución también puede ser una guía útil.
Ejemplo
Este ejemplo usa la tabla AdventureWorks TransactionHistory. El siguiente script hace una copia de la tabla y crea un índice agrupado y no agrupado. No modificaremos los datos en absoluto; este paso es solo para aclarar la indexación (y darle a la tabla un nombre más corto):
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
La tarea es generar una lista de identificaciones de productos e historial para seis productos en particular. Una forma de expresar la consulta es:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360);
Esta consulta devuelve 764 filas utilizando el siguiente plan de ejecución (que se muestra en SentryOne Plan Explorer):

Esta simple consulta califica para la compilación del plan TRIVIAL. El plan de ejecución presenta seis operaciones de búsqueda de índice separadas en una:
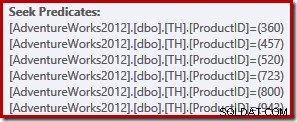
Los lectores con ojo de águila habrán notado que las seis búsquedas se enumeran en ascendente orden de ID de producto, no en el orden (arbitrario) especificado en la lista IN de la consulta original. De hecho, si ejecuta la consulta usted mismo, es muy probable que observe que los resultados se devuelven en orden ascendente de ID de producto. La consulta no está garantizada para devolver los resultados en ese orden, por supuesto, porque no especificamos una cláusula ORDER BY de nivel superior. Sin embargo, podemos agregar tal cláusula ORDER BY, sin cambiar el plan de ejecución producido en este caso:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID;
No repetiré el gráfico del plan de ejecución, porque es exactamente el mismo:la consulta aún califica para un plan trivial, las operaciones de búsqueda son exactamente las mismas y los dos planes tienen exactamente el mismo costo estimado. Agregar la cláusula ORDER BY no nos costó nada, pero nos dio una garantía de ordenación del conjunto de resultados.
Ahora tenemos una garantía de que los resultados se devolverán en orden de ID de producto, pero nuestra consulta actualmente no especifica cómo las filas con el igual se ordenará la identificación del producto. Al observar los resultados, es posible que observe que las filas para el mismo ID de producto parecen estar ordenadas por ID de transacción, de forma ascendente.
Sin un ORDER BY explícito, esta es solo otra observación (es decir, no podemos confiar en este orden), pero podemos modificar la consulta para garantizar que las filas estén ordenadas por ID de transacción dentro de cada ID de producto:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Nuevamente, el plan de ejecución para esta consulta es exactamente el mismo que antes; se produce el mismo plan trivial con el mismo costo estimado. La diferencia es que los resultados ahora están garantizados para ordenarse primero por ID de producto y luego por ID de transacción.
Algunas personas podrían verse tentadas a concluir que las dos consultas anteriores también devolverían filas en este orden, porque los planes de ejecución son los mismos. Esta no es una implicación segura, porque no todos los detalles del motor de ejecución están expuestos en los planes de ejecución (incluso en formato XML). Sin una cláusula order by explícita, SQL Server es libre de devolver las filas en cualquier orden, incluso si el plan nos parece el mismo (podría, por ejemplo, realizar las búsquedas en el orden especificado en el texto de la consulta). El punto es que el optimizador de consultas conoce y puede aplicar ciertos comportamientos dentro del motor que no son visibles para los usuarios.
En caso de que se pregunte cómo nuestro índice no único no agrupado en el ID del producto puede devolver filas en el Producto y Orden de ID de transacción, la respuesta es que la clave de índice no agrupada incorpora la ID de transacción (la clave de índice agrupada única). De hecho, el físico estructura de nuestro índice no agrupado es exactamente lo mismo, en todos los niveles, como si hubiéramos creado el índice con la siguiente definición:
CREATE UNIQUE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID, TransactionID);
Incluso podemos escribir la consulta con DISTINCT o GROUP BY explícito y obtener exactamente el mismo plan de ejecución:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Para ser claros, esto no requiere cambiar el índice no agrupado original de ninguna manera. Como ejemplo final, tenga en cuenta que también podemos solicitar resultados en orden descendente:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID DESC, TransactionID DESC;
Las propiedades del plan de ejecución ahora muestran que el índice se escanea hacia atrás:

Aparte de eso, el plan es el mismo:se produjo en la etapa de optimización del plan trivial y todavía tiene el mismo costo estimado.
Reescribiendo la consulta
No hay nada malo con la consulta anterior o el plan de ejecución, pero podríamos haber optado por expresar la consulta de manera diferente:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 OR ProductID = 723 OR ProductID = 457 OR ProductID = 800 OR ProductID = 943 OR ProductID = 360;
Claramente, este formulario especifica exactamente los mismos resultados que el original y, de hecho, la nueva consulta produce el mismo plan de ejecución (plan trivial, búsqueda múltiple en uno, mismo costo estimado). El formulario OR tal vez aclare un poco que el resultado es una combinación de los resultados de los seis ID de productos individuales, lo que podría llevarnos a probar otra variación que hace que esta idea sea aún más explícita:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 723 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 457 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 800 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 943 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 360;
El plan de ejecución para la consulta UNION ALL es bastante diferente:
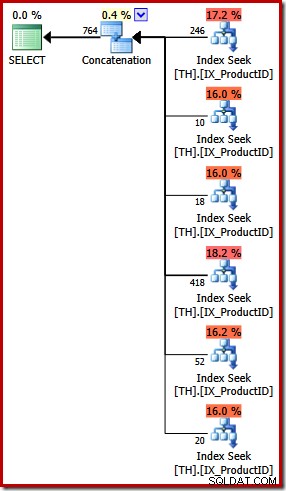
Aparte de las diferencias visuales obvias, este plan requería una optimización basada en costos (COMPLETA) (no calificaba para un plan trivial), y el costo estimado es (en términos relativos) bastante más alto, alrededor de 0.02 unidades versus alrededor de 0.005 unidades antes.
Esto se remonta a mis comentarios iniciales:el optimizador de consultas no conoce todas las equivalencias lógicas y no siempre puede reconocer consultas alternativas que especifican los mismos resultados. El punto que quiero señalar en esta etapa es que expresar esta consulta en particular usando UNION ALL en lugar de IN resultó en un plan de ejecución menos óptimo.
Segundo ejemplo
Este ejemplo elige un conjunto diferente de seis ID de productos y solicita resultados en orden de ID de transacción:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Nuestro índice no agrupado no puede proporcionar filas en el orden solicitado, por lo que el optimizador de consultas tiene la opción de elegir entre buscar en el índice no agrupado y ordenar, o escanear el índice agrupado (que se ingresa solo en el ID de la transacción) y aplicar los predicados del ID del producto como un residuo Los ID de productos enumerados tienen una selectividad más baja que el conjunto anterior, por lo que el optimizador elige un análisis de índice agrupado en este caso:
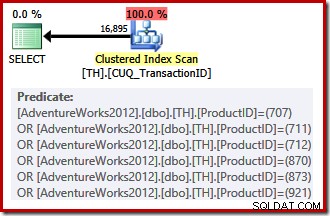
Debido a que hay que tomar una decisión basada en el costo, este plan de ejecución no calificó para un plan trivial. El coste estimado del plan final es de unos 0,714 unidades. Escanear el índice agrupado requiere 797 lecturas lógicas en tiempo de ejecución.
Quizá nos sorprenda que la consulta no haya utilizado el índice del producto. Podríamos intentar forzar una búsqueda del índice no agrupado mediante una sugerencia de índice o especificando FORCESEEK:
SELECT ProductID, TransactionID FROM dbo.TH WITH (FORCESEEK) WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
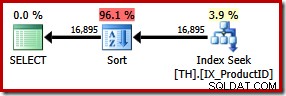
Esto da como resultado una ordenación explícita por ID de transacción. Se estima que el nuevo tipo representa el 96 % del nuevo plan 1.15 costo unitario Este costo estimado más alto explica por qué el optimizador eligió el escaneo de índice agrupado aparentemente más barato cuando se lo dejó en sus propios dispositivos. Sin embargo, el costo de E/S de la nueva consulta es menor:cuando se ejecuta, la búsqueda de índice consume solo 49 lecturas lógicas (por debajo de 797).
También podríamos haber optado por expresar esta consulta utilizando la idea UNION ALL (que anteriormente no tuvo éxito):
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
Produce el siguiente plan de ejecución (haga clic en la imagen para ampliarla en una nueva ventana):

Este plan puede parecer más complejo, pero tiene un coste estimado de tan solo 0,099 unidades, que es mucho más bajo que el escaneo de índice agrupado (0.714 unidades) o buscar más ordenar (1.15 unidades). Además, el nuevo plan consume solo 49 lecturas lógicas en el momento de la ejecución:lo mismo que el plan de búsqueda + clasificación y mucho más bajo que el 797 necesario para el escaneo de índice agrupado.
Esta vez, expresar la consulta mediante UNION ALL produjo un plan mucho mejor, tanto en términos de costo estimado como de lecturas lógicas. El conjunto de datos de origen es un poco demasiado pequeño para hacer una comparación realmente significativa entre la duración de las consultas o el uso de la CPU, pero el análisis del índice agrupado tarda el doble (26 ms) que los otros dos en mi sistema.
El tipo adicional en el plan sugerido es probablemente inofensivo en este ejemplo simple porque es poco probable que se derrame en el disco, pero muchas personas preferirán el plan UNION ALL de todos modos porque no bloquea, evita una concesión de memoria y no requiere un sugerencia de consulta.
Conclusión
Hemos visto que la sintaxis de consulta puede afectar el plan de ejecución elegido por el optimizador, aunque las consultas especifican lógicamente exactamente el mismo conjunto de resultados. La misma reescritura (por ejemplo, UNION ALL) a veces dará como resultado una mejora y, a veces, hará que se seleccione un plan peor.
Reescribir las consultas y probar una sintaxis alternativa es una técnica de ajuste válida, pero se necesita algo de cuidado. Un riesgo es que los cambios futuros en el producto puedan hacer que el formulario de consulta diferente deje de producir repentinamente el mejor plan, pero se podría argumentar que siempre es un riesgo y se mitiga con pruebas previas a la actualización o el uso de guías de planes.
También existe el riesgo de dejarse llevar por esta técnica:el uso de construcciones de consulta "extrañas" o "inusuales" para obtener un plan de mejor rendimiento suele ser una señal de que se ha cruzado una línea. Exactamente dónde se encuentra la distinción entre sintaxis alternativa válida y 'inusual/raro' es probablemente bastante subjetivo; mi propia guía personal es trabajar con formularios de consulta relacionales equivalentes y mantener las cosas lo más simples posible.