Nota:esta publicación se publicó originalmente solo en nuestro libro electrónico, Técnicas de alto rendimiento para SQL Server, Volumen 2. Puede encontrar información sobre nuestros libros electrónicos aquí.
Resumen:este artículo examina algunos comportamientos sorprendentes de los disparadores INSTEAD OF y revela un error grave de estimación de cardinalidad en SQL Server 2014.
Disparadores y control de versiones de filas
Solo los disparadores DML AFTER usan el control de versiones de fila (en SQL Server 2005 en adelante) para proporcionar el insertado y borrado pseudo-tablas dentro de un procedimiento disparador. Este punto no está claramente establecido en gran parte de la documentación oficial. En la mayoría de los lugares, la documentación simplemente dice que el control de versiones de filas se usa para construir el insertado y borrado tablas en disparadores sin calificación (ejemplos a continuación):
Uso de recursos de control de versiones de filas
Comprensión de los niveles de aislamiento basados en el control de versiones de filas
Control de la ejecución de activadores al importar datos de forma masiva
Presumiblemente, las versiones originales de estas entradas se escribieron antes de que se agregaran al producto los activadores INSTEAD OF y nunca se actualizaron. O eso, o es un simple (pero repetido) descuido.
De todos modos, la forma en que funciona el control de versiones de filas con disparadores AFTER es bastante intuitiva. Estos activadores se activan después las modificaciones en cuestión se han realizado, por lo que es fácil ver cómo el mantenimiento de las versiones de las filas modificadas permite que el motor de la base de datos proporcione los insertados y borrado pseudo-tablas. Los borrados la pseudotabla se construye a partir de versiones de las filas afectadas antes de que se realizaran las modificaciones; el insertado la pseudotabla se forma a partir de las versiones de las filas afectadas en el momento en que se inició el procedimiento de activación.
En lugar de disparadores
Los disparadores INSTEAD OF son diferentes porque este tipo de disparador DML reemplaza por completo la acción desencadenada. Los insertados y borrado las pseudotablas ahora representan cambios que habrían se ha hecho, si la declaración desencadenante realmente se hubiera ejecutado. El control de versiones de filas no se puede usar para estos disparadores porque, por definición, no se han producido modificaciones. Entonces, si no usa versiones de fila, ¿cómo lo hace SQL Server?
La respuesta es que SQL Server modifica el plan de ejecución para la declaración DML de activación cuando existe un activador INSTEAD OF. En lugar de modificar directamente las tablas afectadas, el plan de ejecución escribe información sobre los cambios en una tabla de trabajo oculta. Esta tabla de trabajo contiene todos los datos necesarios para realizar los cambios originales, el tipo de modificación a realizar en cada fila (eliminar o insertar), así como cualquier información necesaria en el activador de una cláusula OUTPUT.
Plan de ejecución sin disparador
Para ver todo esto en acción, primero ejecutaremos una prueba simple sin un activador INSTEAD OF presente:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; El plan de ejecución para la eliminación es muy sencillo:
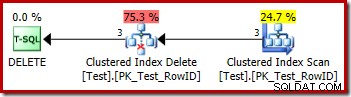
Cada fila que califica se pasa directamente a un operador de eliminación de índice agrupado, que la elimina. Fácil.
Plan de ejecución con un disparador INSTEAD OF
Ahora modifiquemos la prueba para incluir un disparador INSTEAD OF DELETE (uno que solo realiza la misma acción de eliminación por simplicidad):
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; El plan de ejecución para DELETE ahora es bastante diferente:
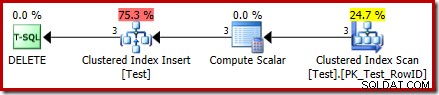
El operador de eliminación de índice agrupado ha sido reemplazado por un índice agrupado Insertar . Esta es la inserción en la tabla de trabajo oculta, que se renombra (en la representación del plan de ejecución pública) al nombre de la tabla base afectada por la eliminación. El cambio de nombre se produce cuando el plan de presentación XML se genera a partir de la representación del plan de ejecución interno, por lo que no existe una forma documentada de ver la tabla de trabajo oculta.
Como resultado de este cambio, el plan parece realizar una inserción a la tabla base para eliminar filas de él. Esto es confuso, pero al menos revela la presencia de un activador INSTEAD OF. Reemplazar el operador Insertar con Delete puede ser aún más confuso. ¿Quizás lo ideal sería un nuevo icono gráfico para una mesa de trabajo de gatillo INSTEAD OF? De todos modos, es lo que es.
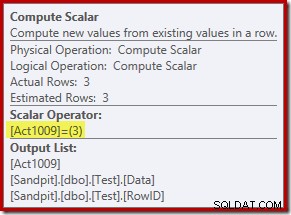
El nuevo operador Compute Scalar define el tipo de acción realizada en cada fila. Este código de acción es un número entero, con los siguientes significados:
- 3 =ELIMINAR
- 4 =INSERTAR
- 259 =ELIMINAR en un plan MERGE
- 260 =INSERTAR en un plan MERGE
Para esta consulta, la acción es una constante 3, lo que significa que cada fila debe eliminarse :
Acciones de actualización
Por otro lado, un plan de ejecución EN LUGAR DE ACTUALIZAR reemplaza un solo operador Actualizar con dos Inserciones de índice agrupado en la misma mesa de trabajo oculta:una para el insertado filas de pseudo-tabla y una para las eliminadas Filas de pseudo-tabla. Un ejemplo de plan de ejecución:

Una FUSIÓN que realiza una ACTUALIZACIÓN también produce un plan de ejecución con dos inserciones en la misma tabla base por razones similares:

El Plan de Ejecución Activador
El plan de ejecución del cuerpo del gatillo también tiene algunas características interesantes:
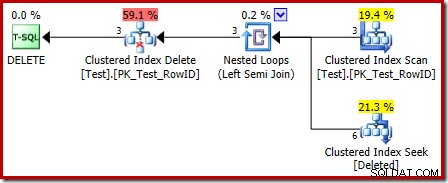
Lo primero que debe notar es que el icono gráfico utilizado para la tabla eliminada no es el mismo que el icono utilizado en los planes de activación DESPUÉS:
La representación en el plan de activación INSTEAD OF es una búsqueda de índice agrupado. El objeto subyacente es la misma mesa de trabajo interna que vimos anteriormente, aunque aquí se llama eliminado en lugar de recibir el nombre de la tabla base, presumiblemente por algún tipo de coherencia con los disparadores AFTER.
La operación de búsqueda en el eliminado la tabla podría no ser lo que esperaba (si esperaba una búsqueda en RowID):
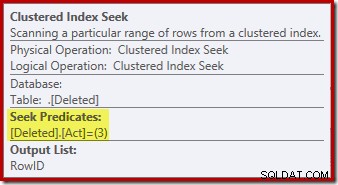
Esta 'búsqueda' devuelve todas las filas de la tabla de trabajo que tienen un código de acción de 3 (eliminar), lo que lo hace exactamente equivalente al Escaneo eliminado operador visto en DESPUÉS de los planes de activación. La misma mesa de trabajo interna se usa para contener filas para ambos insertados y borrado pseudo-tablas en INSTEAD OF disparadores. El equivalente de un escaneo insertado es una búsqueda en el código de acción 4 (que es posible en un eliminar disparador, pero el resultado siempre estará vacío). No hay índices en la mesa de trabajo interna además del índice agrupado no único en la acción columna sola. Además, no hay estadísticas asociadas con este índice interno.
El análisis realizado hasta ahora podría dejarlo preguntándose dónde se realiza la unión entre las columnas RowID. Esta comparación se produce en el operador de semiunión izquierda de bucles anidados como un predicado residual:
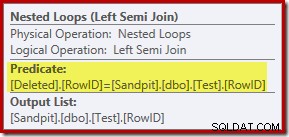
Ahora que sabemos que la 'búsqueda' es efectivamente un escaneo completo de los eliminados table, el plan de ejecución elegido por el optimizador de consultas parece bastante ineficiente. El flujo general del plan de ejecución es que cada fila de la tabla Prueba se compara potencialmente con el conjunto completo de elementos eliminados. filas, que se parece mucho a un producto cartesiano.
La gracia salvadora es que la combinación es una semicombinación, lo que significa que el proceso de comparación se detiene para una fila de Prueba dada tan pronto como la primera eliminada fila satisface el predicado residual. Sin embargo, la estrategia parece curiosa. ¿Quizás el plan de ejecución sería mejor si la tabla Prueba contuviera más filas?
Prueba de activación con 1000 filas
El siguiente script se puede usar para probar el activador con una mayor cantidad de filas. Comenzaremos con 1000:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 1000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; El plan de ejecución para el cuerpo del activador ahora es:
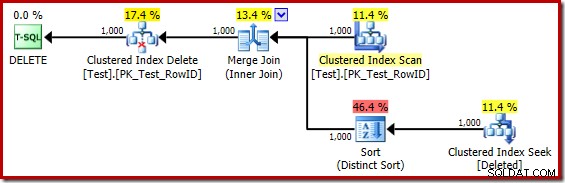
Reemplazando mentalmente la búsqueda de índice agrupado (engañosa) con un escaneo eliminado, el plan en general se ve bastante bien. El optimizador ha elegido una Unión de combinación de uno a muchos en lugar de una Unión semi de bucles anidados, lo que parece razonable. Sin embargo, Distinct Sort es una adición curiosa:
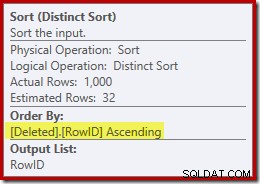
Este tipo está realizando dos funciones. En primer lugar, proporciona la combinación de combinación con la entrada ordenada que necesita, lo cual es justo porque no hay un índice en la mesa de trabajo interna para proporcionar el orden necesario. Lo segundo que está haciendo la ordenación es distinguir en RowID. Esto puede parecer extraño, porque RowID es la clave principal de la tabla base.
El problema es que las filas en el eliminado son simplemente filas candidatas que identificó la consulta DELETE original. A diferencia de un activador DESPUÉS, estas filas aún no se han verificado en busca de restricciones o infracciones de claves, por lo que el procesador de consultas no tiene garantía de que, de hecho, sean únicas.
En general, este es un punto muy importante a tener en cuenta con los activadores INSTEAD OF:no hay garantía de que las filas proporcionadas cumplan con alguna de las restricciones de la tabla base (incluido NOT NULL). Esto no solo es importante que el autor desencadenante lo recuerde; también limita las simplificaciones y transformaciones que puede realizar el optimizador de consultas.
Un segundo problema que se muestra en las propiedades Ordenar anteriores, pero que no se destaca, es que la estimación de salida es solo de 32 filas. La mesa de trabajo interna no tiene estadísticas asociadas, por lo que el optimizador supone al efecto de la operación Distinto. 'Sabemos' que los valores de RowID son únicos, pero sin ninguna información sólida para continuar, el optimizador hace una mala suposición. Este problema volverá a atormentarnos en la próxima prueba.
Prueba de activación con 5000 filas
Ahora modifique el script de prueba para generar 5000 filas:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 5000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; El plan de ejecución del disparador es:
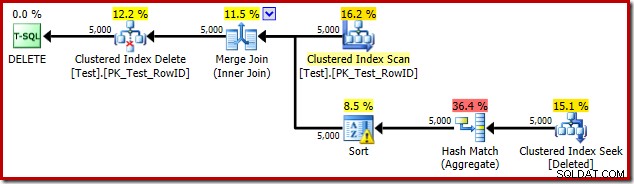
Esta vez, el optimizador ha decidido dividir las operaciones de distinción y clasificación. La distinción en RowID se realiza mediante el operador Hash Match (Agregado):
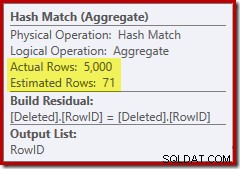
Observe que la estimación del optimizador para la salida es de 71 filas. De hecho, las 5000 filas sobreviven a la distinción porque RowID es único. La estimación inexacta significa que una fracción inadecuada de la asignación de memoria de consulta se asigna a Sort, lo que termina derramándose a tempdb :
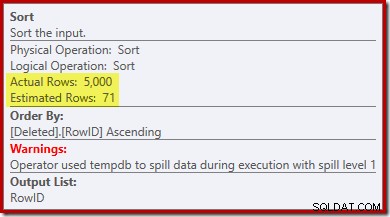
Esta prueba debe realizarse en SQL Server 2012 o superior para ver la advertencia de clasificación en el plan de ejecución. En versiones anteriores, el plan no contiene información sobre derrames:se necesitaría un seguimiento de Profiler en el evento Ordenar advertencias para revelarlo (y tendría que correlacionarlo con la consulta de origen de alguna manera).
Prueba de activación con 5000 filas en SQL Server 2014
Si la prueba anterior se repite en SQL Server 2014, en una base de datos establecida en el nivel de compatibilidad 120, por lo que se utiliza el nuevo estimador de cardinalidad (CE), el plan de ejecución del activador vuelve a ser diferente:
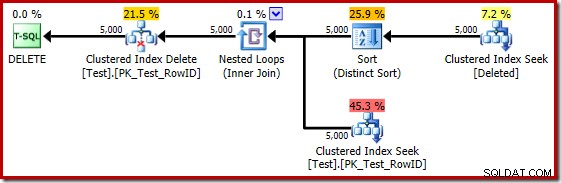
En cierto modo, este plan de ejecución parece una mejora. El (innecesario) Distinct Sort todavía está allí, pero la estrategia general parece más natural:para cada candidato distinto RowID en el eliminado únase a la tabla base (para verificar que la fila candidata realmente existe) y luego elimínela.
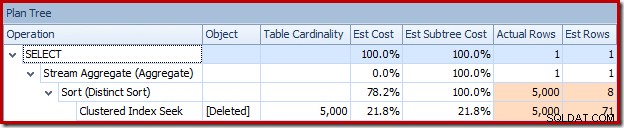
Desafortunadamente, el plan de 2014 se basa en estimaciones de cardinalidad peores que las que vimos en SQL Server 2012. Cambiar SQL Sentry Plan Explorer para mostrar el estimado el recuento de filas muestra claramente el problema:
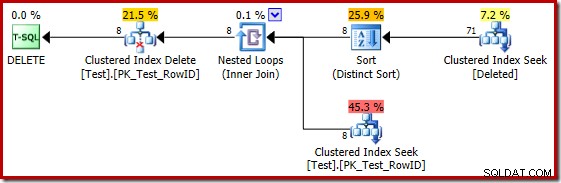
El optimizador eligió una estrategia de bucles anidados para la combinación porque esperaba una cantidad muy pequeña de filas en su entrada principal. El primer problema ocurre en la búsqueda de índice agrupado. El optimizador sabe que la tabla eliminada contiene 5000 filas en este punto, como podemos ver si cambiamos a la vista de árbol del plan y agregamos la columna opcional Cardinalidad de la tabla (que desearía que se incluyera de manera predeterminada):
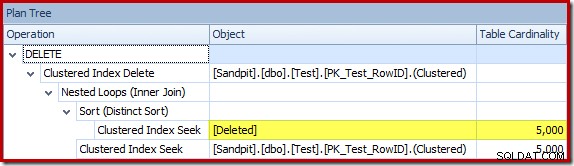
El estimador de cardinalidad "antiguo" en SQL Server 2012 y versiones anteriores es lo suficientemente inteligente como para saber que la "búsqueda" en la mesa de trabajo interna devolvería las 5000 filas (por lo que eligió una combinación de combinación). El nuevo CE no es tan inteligente. Ve la mesa de trabajo como una 'caja negra' y adivina el efecto de la búsqueda en el código de acción =3:
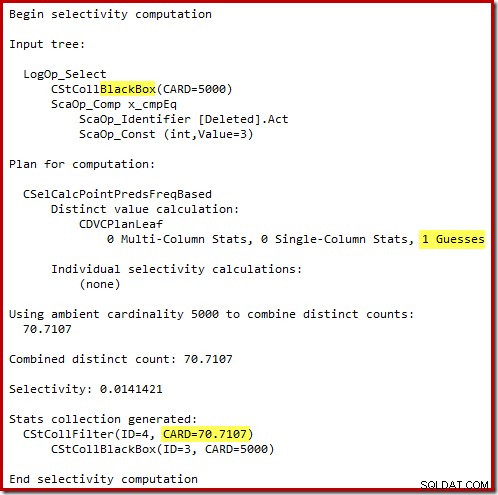
La suposición de 71 filas (redondeadas hacia arriba) es un resultado bastante miserable, pero el error se agrava cuando el nuevo CE estima las filas para la operación distinta en esas 71 filas:
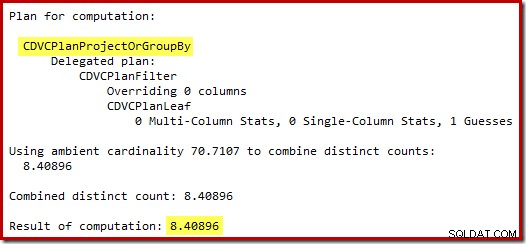
Según las 8 filas esperadas, el optimizador elige la estrategia de bucles anidados. Otra forma de ver estos errores de estimación es agregar la siguiente declaración al cuerpo del activador (solo con fines de prueba):
SELECT COUNT_BIG(DISTINCT RowID) FROM Deleted;
El plan estimado muestra claramente los errores de estimación:
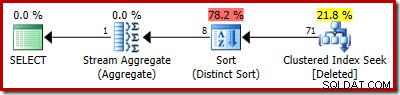
El plan real aún muestra 5000 filas, por supuesto:
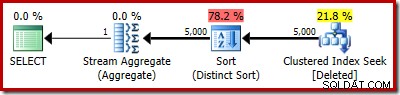
O puede comparar la estimación con la real al mismo tiempo en la vista de árbol del plan:
Un millón de filas...
Las estimaciones deficientes cuando se usa el estimador de cardinalidad de 2014 hacen que el optimizador seleccione una estrategia de bucles anidados incluso cuando la tabla de prueba contiene un millón de filas. El nuevo CE de 2014 estimado el plan para esa prueba es:
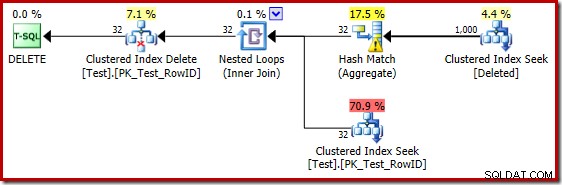
La 'búsqueda' estima 1.000 filas a partir de la cardinalidad conocida de 1.000.000 y la estimación distinta es de 32 filas. El plan posterior a la ejecución revela el efecto en la memoria reservada para el Hash Match:
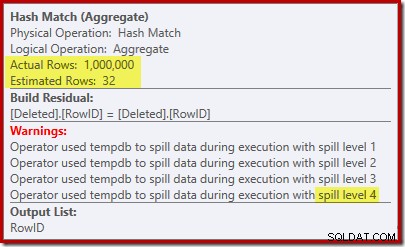
Esperando solo 32 filas, Hash Match se mete en un verdadero problema, derramando recursivamente su tabla hash antes de completarse finalmente.
Reflexiones finales
Si bien es cierto que nunca se debe escribir un disparador para hacer algo que se puede lograr con integridad referencial declarativa, también es cierto que un bien escrito disparador que utiliza un eficiente el plan de ejecución puede ser comparable en rendimiento al costo de mantener un índice adicional no agrupado.
Hay dos problemas prácticos con la declaración anterior. Primero (y con la mejor voluntad del mundo) la gente no siempre escribe un buen código de disparo. En segundo lugar, obtener un buen plan de ejecución del optimizador de consultas en todas las circunstancias puede ser difícil. La naturaleza de los disparadores es que se llaman con una amplia gama de cardinalidades de entrada y distribuciones de datos.
Incluso para los disparadores AFTER, la falta de índices y estadísticas sobre los eliminados y insertado las pseudotablas significan que la selección del plan a menudo se basa en conjeturas o información errónea. Incluso cuando inicialmente se selecciona un buen plan, las ejecuciones posteriores pueden reutilizar el mismo plan cuando una recompilación hubiera sido una mejor opción. Hay formas de evitar las limitaciones, principalmente mediante el uso de tablas temporales e índices/estadísticas explícitos, pero incluso allí se requiere mucho cuidado (ya que los disparadores son una forma de procedimiento almacenado).
Con los disparadores INSTEAD OF, los riesgos pueden ser aún mayores debido a que el contenido del insertado y borrado las tablas son candidatas no verificadas:el optimizador de consultas no puede usar restricciones en la tabla base para simplificar y refinar su plan de ejecución. El nuevo estimador de cardinalidad en SQL Server 2014 también representa un verdadero paso atrás cuando se trata de planes de activación INSTEAD OF. Adivinar el efecto de una operación de búsqueda que introdujo el motor es un descuido sorprendente y desagradable.