Tuve el placer de asistir a PGDay UK la semana pasada, un evento muy agradable, espero tener la oportunidad de volver el año que viene. Hubo muchas charlas interesantes, pero la que me llamó la atención en particular fue Performace para consultas con agrupación de Alexey Bashtanov.
He dado una buena cantidad de charlas similares orientadas al rendimiento en el pasado, por lo que sé lo difícil que es presentar los resultados de referencia de una manera comprensible e interesante, y creo que Alexey hizo un trabajo bastante bueno. Entonces, si se ocupa de la agregación de datos (es decir, BI, análisis o cargas de trabajo similares), le recomiendo que revise las diapositivas y, si tiene la oportunidad de asistir a la charla en alguna otra conferencia, le recomiendo que lo haga.
Pero hay un punto en el que no estoy de acuerdo con la charla. En varios lugares, la charla sugirió que, en general, debería preferir HashAggregate, porque las clasificaciones son lentas.
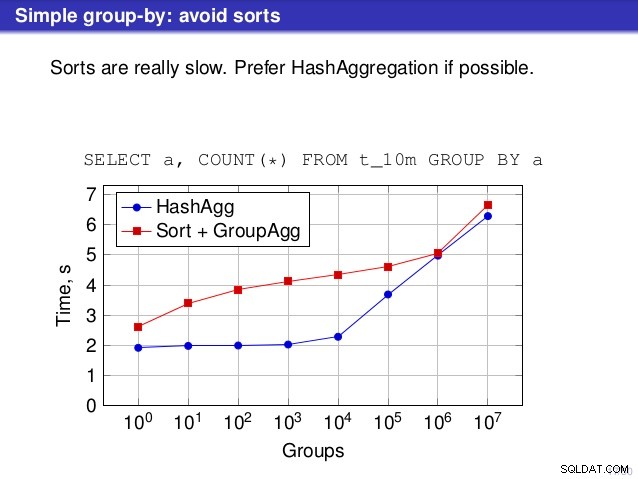
Considero que esto es un poco engañoso, porque una alternativa a HashAggregate es GroupAggregate, no Sort. Entonces, la recomendación asume que cada GroupAggregate tiene una ordenación anidada, pero eso no es del todo cierto. GroupAggregate requiere entrada ordenada, y una Ordenación explícita no es la única forma de hacerlo:también tenemos nodos IndexScan e IndexOnlyScan, que eliminan los costos de ordenación y mantienen los otros beneficios asociados con las rutas ordenadas (especialmente IndexOnlyScan).
Permítanme demostrar cómo funciona (IndexOnlyScan+GroupAggregate) en comparación con HashAggregate y (Sort+GroupAggregate):el script que he usado para las mediciones está aquí. Construye cuatro tablas simples, cada una con 100 millones de filas y un número diferente de grupos en la columna "branch_id" (que determina el tamaño de la tabla hash). El más pequeño tiene 10k grupos
-- table with 10k groups create table t_10000 (branch_id bigint, amount numeric); insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
y tres mesas adicionales tienen grupos de 100k, 1M y 5M. Ejecutemos esta consulta simple agregando los datos:
SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1
y luego convenza a la base de datos para que use tres planes diferentes:
1) Hash Agregado
SET enable_sort = off;
SET enable_hashagg = on;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
----------------------------------------------------------------------------
HashAggregate (cost=2136943.00..2137067.99 rows=9999 width=40)
Group Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 width=19)
(3 rows) 2) Agregado de grupo (con ordenación)
SET enable_sort = on;
SET enable_hashagg = off;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
-------------------------------------------------------------------------------
GroupAggregate (cost=16975438.38..17725563.37 rows=9999 width=40)
Group Key: branch_id
-> Sort (cost=16975438.38..17225438.38 rows=100000000 width=19)
Sort Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 ...)
(5 rows) 3) GroupAgregate (con IndexOnlyScan)
SET enable_sort = on;
SET enable_hashagg = off;
CREATE INDEX ON t_10000 (branch_id, amount);
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
--------------------------------------------------------------------------
GroupAggregate (cost=0.57..3983129.56 rows=9999 width=40)
Group Key: branch_id
-> Index Only Scan using t_10000_branch_id_amount_idx on t_10000
(cost=0.57..3483004.57 rows=100000000 width=19)
(3 rows) Resultados
Después de medir los tiempos para cada plan en todas las tablas, los resultados se ven así:
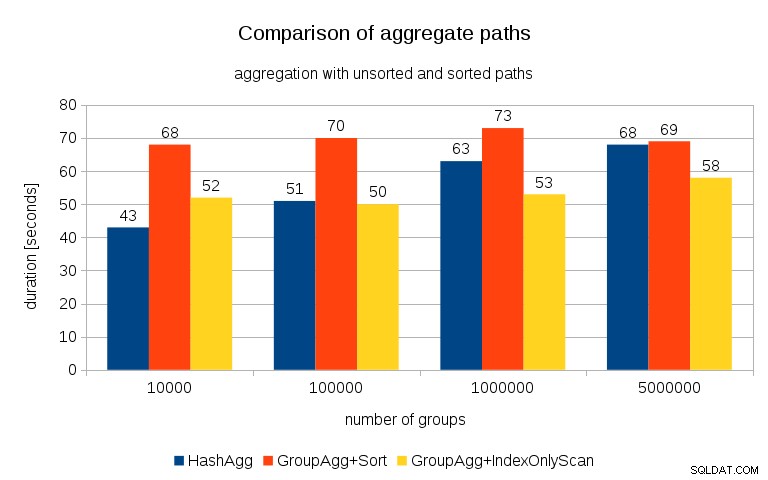
Para tablas hash pequeñas (que se ajustan a la memoria caché L3, que en este caso es de 16 MB), la ruta HashAggregate es claramente más rápida que ambas rutas ordenadas. Pero muy pronto, GroupAgg+IndexOnlyScan se vuelve igual o incluso más rápido; esto se debe a la eficiencia de la memoria caché, la principal ventaja de GroupAggregate. Mientras que HashAggregate necesita mantener toda la tabla hash en la memoria a la vez, GroupAggregate solo necesita mantener el último grupo. Y cuanto menos memoria utilice, más probable es que quepa en la memoria caché L3, que es aproximadamente un orden de magnitud más rápida en comparación con la RAM normal (para las memorias caché L1/L2, la diferencia es aún mayor).
Entonces, aunque hay una sobrecarga considerable asociada con IndexOnlyScan (para el caso de 10k, es aproximadamente un 20 % más lento que la ruta HashAggregate), a medida que la tabla hash crece, la tasa de aciertos de caché L3 cae rápidamente y la diferencia finalmente hace que GroupAggregate sea más rápido. Y finalmente, incluso GroupAggregate+Sort se pone a la par con la ruta HashAggregate.
Puede argumentar que sus datos generalmente tienen un número bastante bajo de grupos y, por lo tanto, la tabla hash siempre encajará en el caché L3. Pero considere que el caché L3 es compartido por todos los procesos que se ejecutan en la CPU y también por todas las partes del plan de consulta. Entonces, aunque actualmente tenemos ~20 MB de caché L3 por socket, su consulta solo obtendrá una parte de eso, y todos los nodos compartirán esa parte en su consulta (posiblemente bastante compleja).
Actualización 2016/07/26 :Como se señaló en los comentarios de Peter Geoghegan, la forma en que se generaron los datos probablemente dé como resultado una correlación, no los valores (o más bien hash de los valores), sino las asignaciones de memoria. Repetí las consultas con datos correctamente aleatorios, es decir, haciendo
insert into t_10000 select (10000*random())::bigint, random() from generate_series(1,100000000) s(i);
en lugar de
insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
y los resultados se ven así:
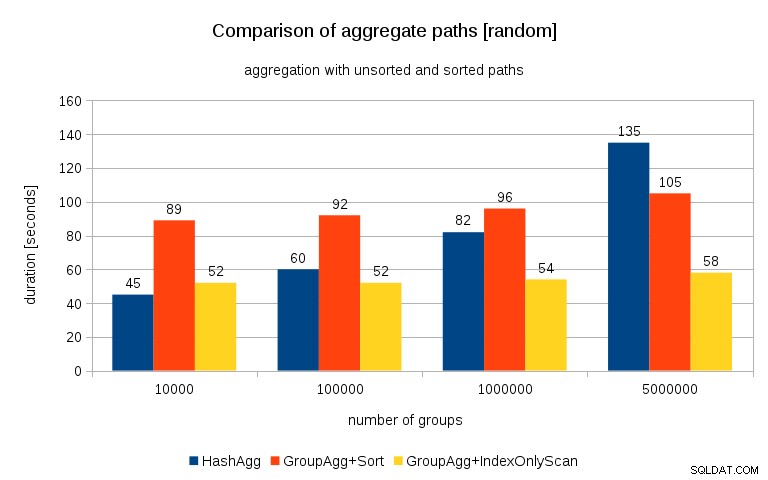
Comparando esto con el gráfico anterior, creo que está bastante claro que los resultados están aún más a favor de las rutas ordenadas, particularmente para el conjunto de datos con grupos de 5M. El conjunto de datos de 5M también muestra que GroupAgg con una ordenación explícita puede ser más rápido que HashAgg.
Resumen
Si bien HashAggregate es probablemente más rápido que GroupAggregate con una ordenación explícita (aunque dudo en decir que siempre es el caso), usar GroupAggregate con IndexOnlyScan más rápido puede hacerlo mucho más rápido que HashAggregate.
Por supuesto, no puede elegir el plan exacto directamente; el planificador debe hacerlo por usted. Pero afecta el proceso de selección (a) creando índices y (b) configurando work_mem . Es por eso que a veces baja work_mem (y maintenance_work_mem ) dan como resultado un mejor rendimiento.
Sin embargo, los índices adicionales no son gratuitos:cuestan tiempo de CPU (al insertar datos nuevos) y espacio en disco. Para IndexOnlyScans, los requisitos de espacio en disco pueden ser bastante significativos porque el índice debe incluir todas las columnas a las que hace referencia la consulta, y el IndexScan normal no ofrecería el mismo rendimiento, ya que genera muchas E/S aleatorias en la tabla (eliminando todas las ganancias potenciales).
Otra buena característica es la estabilidad del rendimiento:observe cómo los tiempos de HashAggregate cambian según la cantidad de grupos, mientras que las rutas de GroupAggregate funcionan casi igual.



