PostgreSQL es un proyecto impresionante y evoluciona a un ritmo asombroso. Nos centraremos en la evolución de las capacidades de tolerancia a fallas en PostgreSQL a lo largo de sus versiones con una serie de publicaciones de blog. Esta es la tercera publicación de la serie y hablaremos sobre los problemas de la línea de tiempo y sus efectos en la tolerancia a fallas y la confiabilidad de PostgreSQL.
Si desea presenciar el progreso de la evolución desde el principio, consulte las dos primeras publicaciones de blog de la serie:
- Evolución de la tolerancia a fallos en PostgreSQL
- Evolución de la tolerancia a fallos en PostgreSQL:Fase de replicación

Cronologías
La capacidad de restaurar la base de datos a un momento anterior crea algunas complejidades que cubriremos en algunos de los casos explicando failover (Fig. 1), conmutación (Fig. 2) y pg_rewind (Fig. 3) casos más adelante en este tema.
Por ejemplo, en el historial original de la base de datos, suponga que eliminó una tabla crítica a las 5:15 p. m. del martes por la noche, pero no se dio cuenta de su error hasta el miércoles al mediodía. Sin inmutarse, obtiene su copia de seguridad, restaura al punto en el tiempo a las 5:14 p. m. del martes por la noche y está en funcionamiento. En esta historia del universo de la base de datos, nunca dejó caer la tabla. Pero supongamos que luego se da cuenta de que no fue una gran idea y le gustaría volver a algún momento del miércoles por la mañana en la historia original. No podrá hacerlo si, mientras su base de datos estaba en funcionamiento, sobrescribió algunos de los archivos del segmento WAL que condujeron al momento al que ahora desea volver.
Por lo tanto, para evitar esto, debe distinguir la serie de registros WAL generados después de haber realizado una recuperación puntual de aquellos que se generaron en el historial de la base de datos original.
Para lidiar con este problema, PostgreSQL tiene una noción de líneas de tiempo. Cada vez que se completa la recuperación de un archivo, se crea una nueva línea de tiempo para identificar la serie de registros WAL generados después de esa recuperación. El número de identificación de la línea de tiempo es parte de los nombres de los archivos del segmento WAL, por lo que una nueva línea de tiempo no sobrescribe los datos de WAL generados por las líneas de tiempo anteriores. De hecho, es posible archivar muchas líneas de tiempo diferentes.
Considere la situación en la que no está muy seguro de a qué punto en el tiempo recuperarse y, por lo tanto, tiene que hacer varias recuperaciones en un punto en el tiempo mediante prueba y error hasta que encuentre el mejor lugar para separarse del historial anterior. Sin plazos, este proceso pronto generaría un desorden inmanejable. Con las líneas de tiempo, puede recuperar cualquier estado anterior, incluidos los estados en las ramas de la línea de tiempo que abandonó anteriormente.
Cada vez que se crea una nueva línea de tiempo, PostgreSQL crea un archivo de "historial de línea de tiempo" que muestra de qué línea de tiempo se separó y cuándo. Estos archivos de historial son necesarios para permitir que el sistema elija los archivos de segmento WAL correctos cuando se recupera de un archivo que contiene varias líneas de tiempo. Por lo tanto, se archivan en el área de archivo de WAL al igual que los archivos de segmento de WAL. Los archivos de historial son solo pequeños archivos de texto, por lo que es económico y apropiado mantenerlos indefinidamente (a diferencia de los archivos de segmento que son grandes). Si lo desea, puede agregar comentarios a un archivo de historial para registrar sus propias notas sobre cómo y por qué se creó esta línea de tiempo en particular. Dichos comentarios serán especialmente valiosos cuando tenga una gran cantidad de líneas de tiempo diferentes como resultado de la experimentación.
El comportamiento predeterminado de la recuperación es recuperar a lo largo de la misma línea de tiempo que estaba vigente cuando se realizó la copia de seguridad base. Si desea recuperarse en alguna línea de tiempo secundaria (es decir, desea volver a algún estado que se generó después de un intento de recuperación), debe especificar la ID de la línea de tiempo de destino en recovery.conf. No puede recuperar en líneas de tiempo que se bifurcaron antes que la copia de seguridad base.
Para simplificar el concepto de líneas de tiempo en PostgreSQL, problemas relacionados con la línea de tiempo en caso de conmutación por error , conmutación y pg_rewind se resumen y explican con Fig.1, Fig.2 y Fig.3.
Escenario de conmutación por error:
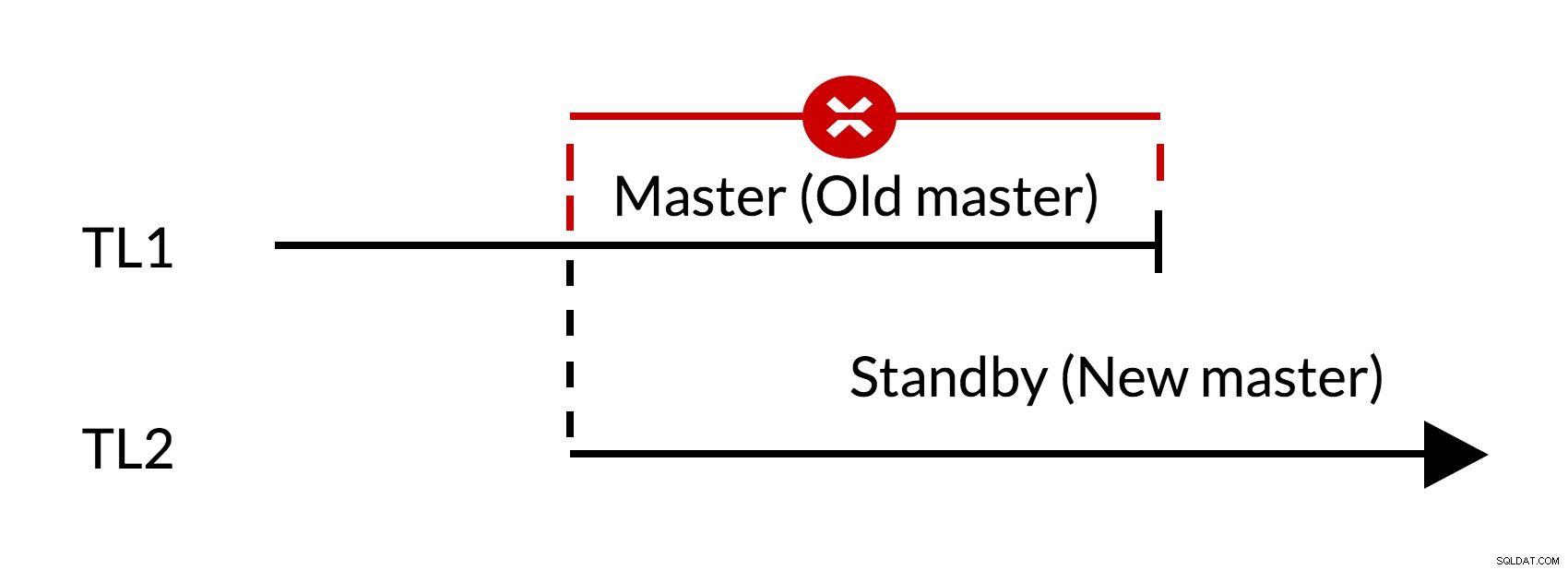
Fig. 1 Conmutación por error
- Hay cambios destacados en el antiguo maestro (TL1)
- El aumento de la línea de tiempo representa un nuevo historial de cambios (TL2)
- Los cambios de la línea de tiempo anterior no se pueden reproducir en los servidores que cambiaron a la nueva línea de tiempo
- El viejo maestro no puede seguir al nuevo maestro
Escenario de cambio:
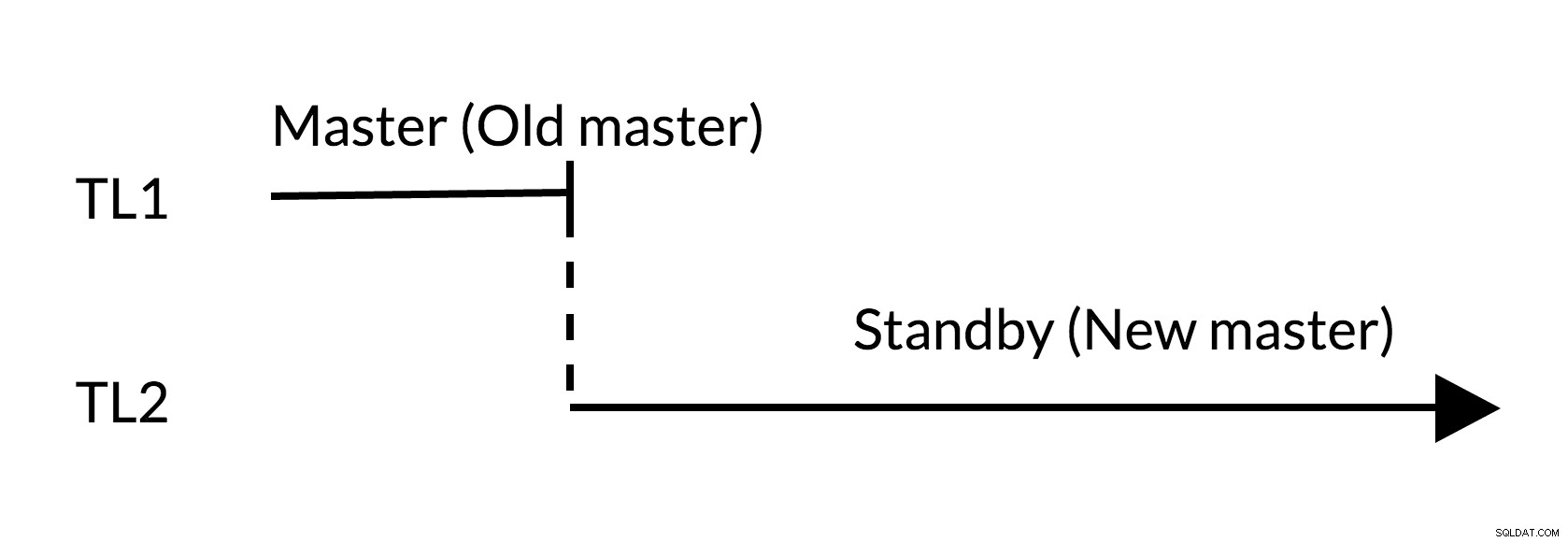 Fig.2 Conmutación
Fig.2 Conmutación
- No hay cambios destacados en el antiguo maestro (TL1)
- El aumento de la línea de tiempo representa un nuevo historial de cambios (TL2)
- El antiguo maestro puede convertirse en standby para el nuevo maestro
escenario pg_rewind:
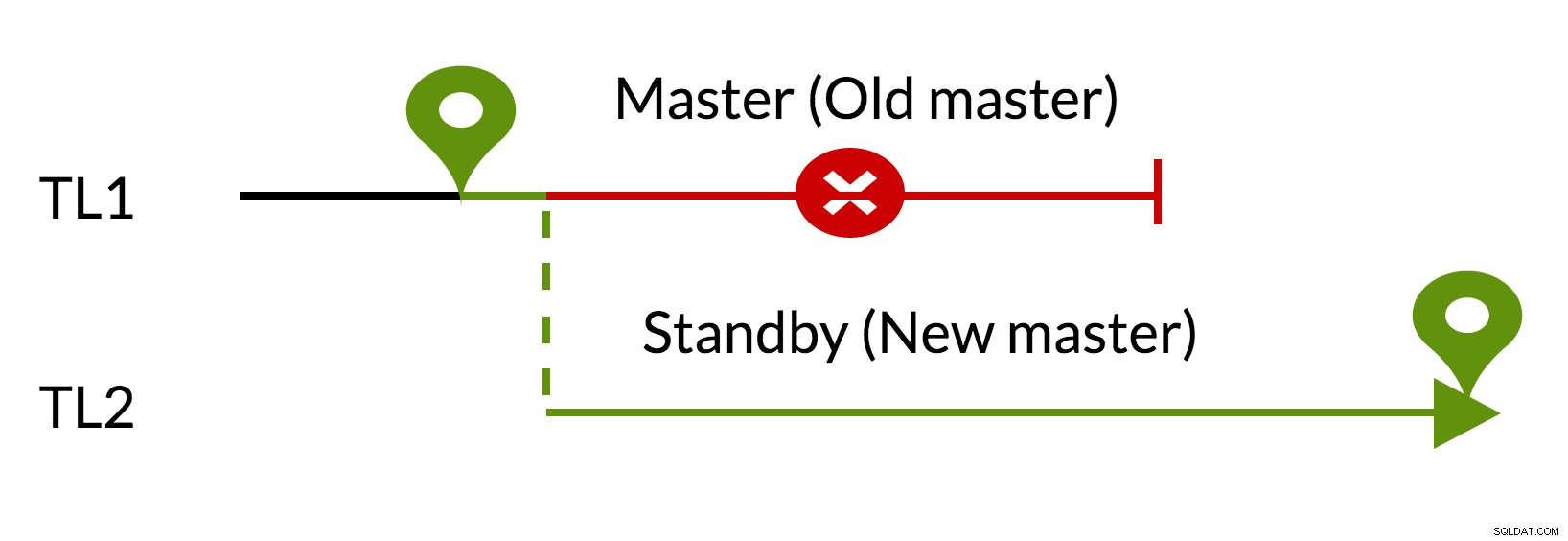 Fig.3 pg_rewind
Fig.3 pg_rewind
- Los cambios pendientes se eliminan utilizando datos del nuevo maestro (TL1)
- El antiguo maestro puede seguir al nuevo maestro (TL2)
pg_rebobinar
pg_rewind es una herramienta para sincronizar un clúster de PostgreSQL con otra copia del mismo clúster, después de que las líneas de tiempo de los clústeres hayan divergido. Un escenario típico es volver a poner en línea un servidor maestro antiguo después de la conmutación por error, como un servidor de reserva que sigue al nuevo maestro.
El resultado es equivalente a reemplazar el directorio de datos de destino con el de origen. Se copian todos los archivos, incluidos los archivos de configuración. La ventaja de pg_rewind sobre la realización de una nueva copia de seguridad base, o herramientas como rsync, es que pg_rewind no requiere leer todos los archivos sin cambios en el clúster. Eso lo hace mucho más rápido cuando la base de datos es grande y solo una pequeña parte difiere entre los clústeres.
¿Cómo funciona?
La idea básica es copiar todo, desde el nuevo clúster al antiguo, excepto los bloques que sabemos que son iguales.
- Escanee el registro de WAL del clúster anterior, comenzando desde el último punto de control antes del punto en el que el historial de la línea de tiempo del nuevo clúster se separó del clúster anterior. Para cada registro WAL, tome nota de los bloques de datos que se tocaron. Esto produce una lista de todos los bloques de datos que se cambiaron en el clúster anterior, después de que se bifurcó el nuevo clúster.
- Copie todos esos bloques modificados del nuevo clúster al antiguo.
- Copie todos los demás archivos, como los archivos de configuración y de obstrucción, del nuevo clúster al antiguo, todo excepto los archivos de relación.
- Aplique el WAL del nuevo clúster, comenzando desde el punto de control creado en la conmutación por error. (Estrictamente hablando, pg_rewind no aplica el WAL, solo crea un archivo de etiqueta de respaldo que indica que cuando se inicia PostgreSQL, comenzará la reproducción desde ese punto de control y aplicará todos los WAL requeridos).
Conclusión
En esta publicación de blog, discutimos los plazos en Postgres y cómo manejamos los casos de conmutación por error y conmutación. También hablamos sobre cómo funciona pg_rewind y sus beneficios para la tolerancia a fallas y la confiabilidad de Postgres. Continuaremos con la confirmación sincrónica en la próxima entrada del blog.
Referencias
Documentación de PostgreSQL
Recetario de administración de PostgreSQL 9:segunda edición
pg_rewind Presentación de Nordic PGDay por Heikki Linnakangas