La alta disponibilidad es un requisito para muchos sistemas, independientemente de la tecnología que utilice. Esto es especialmente importante para las bases de datos, ya que almacenan datos en los que se basan las aplicaciones. Dependiendo de los requisitos, existen diferentes formas de implementar un entorno de Alta Disponibilidad para PostgreSQL, pero siempre es necesario utilizar una herramienta complementaria ya que las características nativas de PostgreSQL no son suficientes.
En este blog, veremos cómo implementar Percona Distribution para PostgreSQL para alta disponibilidad y qué tipo de herramientas son necesarias para hacerlo.
Distribución Percona para PostgreSQL
Es una colección de herramientas para ayudarlo a administrar su sistema de base de datos PostgreSQL. Instala PostgreSQL y lo complementa con una selección de extensiones que permiten resolver tareas prácticas esenciales de manera eficiente, incluyendo:
- pg_repack :Reconstruye los objetos de la base de datos PostgreSQL.
- pgaudit :proporciona un registro detallado de auditoría de objetos o sesiones a través de la función de registro estándar de PostgreSQL.
- pgBackRest :Es una solución de copia de seguridad y restauración para PostgreSQL.
- Patronos :Es una solución de Alta Disponibilidad para PostgreSQL.
- pg_stat_monitor :recopila y agrega estadísticas para PostgreSQL y proporciona información de histograma.
- Una colección de extensiones adicionales de contribución de PostgreSQL.
Alta disponibilidad en PostgreSQL
Existen diferentes arquitecturas para la alta disponibilidad de PostgreSQL, pero la más común es tener una topología Master-Slave (Primary-Standby). Se basa en una base de datos primaria con uno o más nodos en espera. Estas bases de datos en espera permanecerán sincronizadas (o casi sincronizadas) con la principal, dependiendo de si la replicación es síncrona o asíncrona. Si el servidor principal falla, el standby contiene casi todos los datos del servidor principal y puede convertirse rápidamente en el nuevo servidor de base de datos principal.
Pero una configuración maestro-esclavo no es suficiente para garantizar de manera efectiva una alta disponibilidad, ya que también debe manejar las fallas. Una vez que se detecta una falla, debería poder seleccionar un nodo en espera y conmutar por error a él con el menor retraso posible. PostgreSQL en sí mismo no incluye un mecanismo de conmutación por error automático, por lo que requerirá algunas secuencias de comandos personalizadas o herramientas de terceros para esta automatización.
Después de que ocurra una conmutación por error, las aplicaciones deben recibir una notificación en consecuencia, para que puedan comenzar a usar el nuevo nodo principal. Además, debe evaluar el estado de nuestra arquitectura después de una conmutación por error, ya que puede ejecutarse en una situación en la que solo tiene el nuevo principal en ejecución (es decir, tenía un nodo principal y solo uno en espera antes del problema). En ese caso, deberá agregar un nuevo nodo en espera de alguna manera para volver a crear la configuración maestro-esclavo que tenía originalmente para alta disponibilidad.
Para que funcione, necesitará tener diferentes herramientas/servicios que lo ayuden con esta tarea.
Equilibradores de carga
Los balanceadores de carga son herramientas que se pueden usar para administrar el tráfico de su aplicación para aprovechar al máximo la arquitectura de su base de datos.
No solo es útil para equilibrar la carga de nuestras bases de datos, sino que también ayuda a que las aplicaciones se redirijan a los nodos disponibles/en buen estado e incluso a especificar puertos con diferentes roles.
HAProxy es un balanceador de carga que distribuye el tráfico desde un origen a uno o más destinos y puede definir reglas y/o protocolos específicos para esta tarea. Si alguno de los destinos deja de responder, se marca como desconectado y el tráfico se envía al resto de destinos disponibles.
Keepalived es un servicio que le permite configurar una IP virtual dentro de un grupo de servidores activo/pasivo. Esta IP virtual está asignada a un servidor activo. Si este servidor falla, la IP se migra automáticamente al servidor pasivo “Secundario”, lo que le permite seguir trabajando con la misma IP de forma transparente para los sistemas.
Para implementar todas estas cosas, puede hacerlo manualmente, lo que significará trabajo adicional y tareas que consumirán mucho tiempo, o puede hacerlo desde un solo sistema usando ClusterControl.
Veamos cómo importar su distribución Percona existente para PostgreSQL a ClusterControl y luego cómo configurar un entorno de alta disponibilidad usando HAProxy y Keepalived en torno a esta configuración desde una interfaz amigable y fácil de usar.
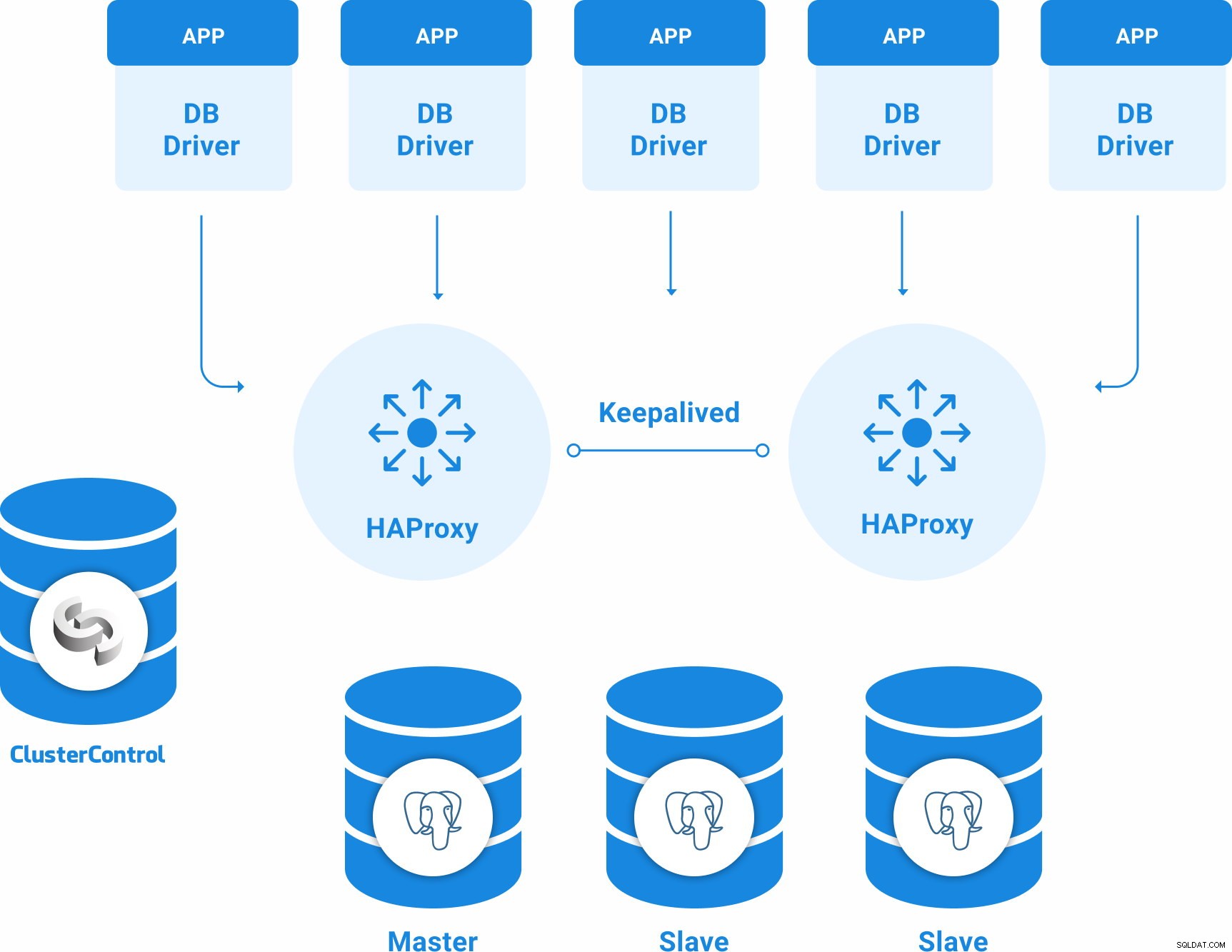
Topología de PostgreSQL para alta disponibilidad
Una topología básica de alta disponibilidad para PostgreSQL puede ser:
- 3 servidores PostgreSQL 12 (uno principal y dos en espera).
- 2 balanceadores de carga HAProxy.
- Keepalived configurado entre los servidores del balanceador de carga.
- 1 servidor ClusterControl
Entonces, tendrá la siguiente topología:
Cómo instalar Percona Distribution para PostgreSQL
Empecemos instalando Percona Distribution para PostgreSQL. Para este ejemplo, usaremos CentOS 7 y PostgreSQL 12.
Si tiene su clúster instalado, vaya a la siguiente sección para importar su base de datos existente a ClusterControl.
Instalar epel-release y percona-release
$ yum install epel-release
$ yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpmHabilitar el repositorio de PostgreSQL 12
$ percona-release setup ppg-12
* Disabling all Percona Repositories
* Enabling the Percona Distribution for PostgreSQL 12 repository
<*> All done!Instalar el paquete del servidor
$ yum install percona-postgresql12-serverTenga en cuenta que este paquete no instalará todos los componentes de Percona Distribution. Para instalar estos componentes, use los paquetes opcionales apropiados como se muestra a continuación:
$ yum install percona-pg_repack12
$ yum install percona-pgaudit
$ yum install percona-pgbackrest
$ yum install percona-patroni
$ yum install percona-pg-stat-monitor12
$ yum install percona-postgresql12-contribInicializar la base de datos
$ /usr/pgsql-12/bin/postgresql-12-setup initdb
Initializing database ... OKAsegúrese de tener la configuración correcta para poder configurar una replicación de PostgreSQL, similar a:
$ vi /var/lib/pgsql/12/data/postgresql.conf
listen_addresses = '*'
wal_level=logical
max_wal_senders = 16
wal_keep_segments = 32
hot_standby = onLuego, inicie el servicio de base de datos
$ systemctl start postgresql-12Ahora, si desea agregar nodos en espera, repita los pasos 1, 2 y 3 en todos los nodos que desea agregar al clúster. Para esos nodos, no necesita configurar nada más ya que ClusterControl creará la configuración correspondiente.
Importación de distribución de Percona para PostgreSQL en ClusterControl
Con ClusterControl puede implementar o importar diferentes motores de base de datos de código abierto desde el mismo sistema, y solo se requiere acceso SSH y un usuario privilegiado para usarlo.
Vaya a la sección “Importar” y complete la información requerida de su servidor PostgreSQL.
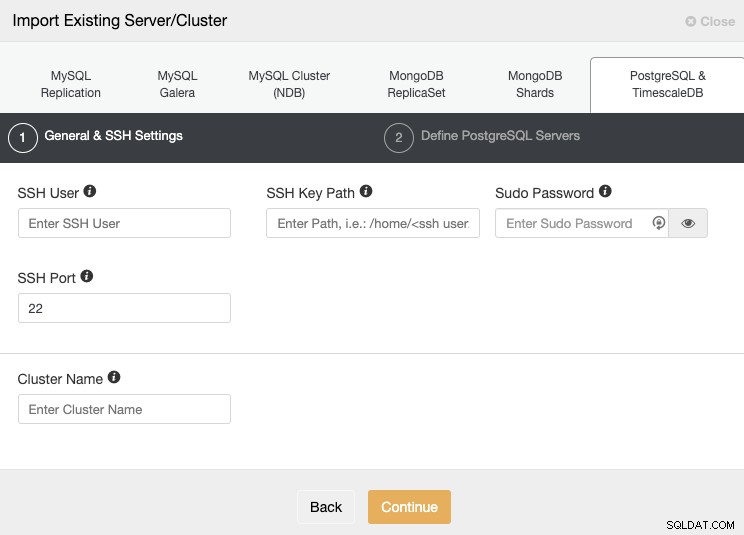
Debe especificar Usuario, Clave o Contraseña y puerto para conectarse por SSH a sus servidores. También necesita un nombre para su nuevo clúster; de lo contrario, ClusterControl le asignará uno genérico.
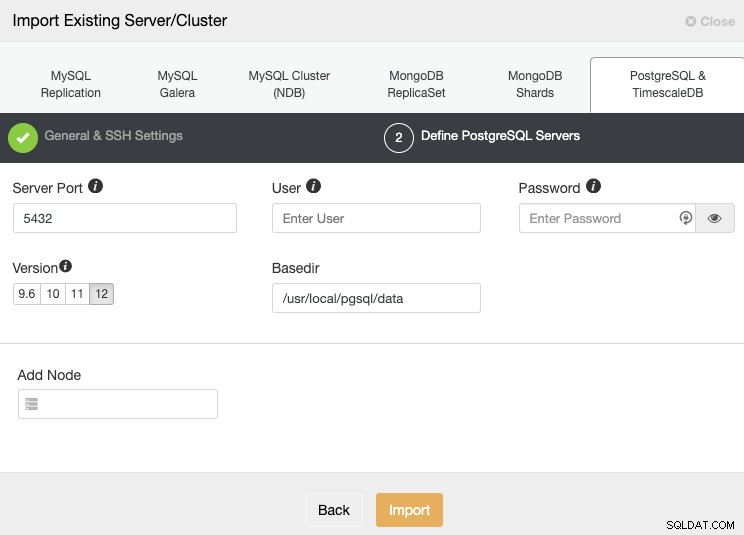
Después de configurar la información de acceso SSH, debe definir las credenciales de la base de datos, versión, directorio base y dirección IP o nombre de host para cada nodo de la base de datos.
Si aún no tiene configurada la replicación, solo necesita agregar la dirección IP o el nombre de host para el nodo principal, ya que le mostraremos cómo agregar el resto de los nodos más adelante.
Asegúrese de obtener la marca verde al ingresar el nombre de host o la dirección IP, lo que indica que ClusterControl puede comunicarse con el nodo. Luego, haga clic en el botón Importar y espere hasta que ClusterControl termine su trabajo. Puede monitorear el proceso en la Sección de actividad de ClusterControl. Cuando haya terminado, verá el nuevo clúster en la pantalla principal de ClusterControl. Para agregar una nueva réplica, vaya a las acciones del clúster y seleccione la opción "Agregar esclavo de replicación".
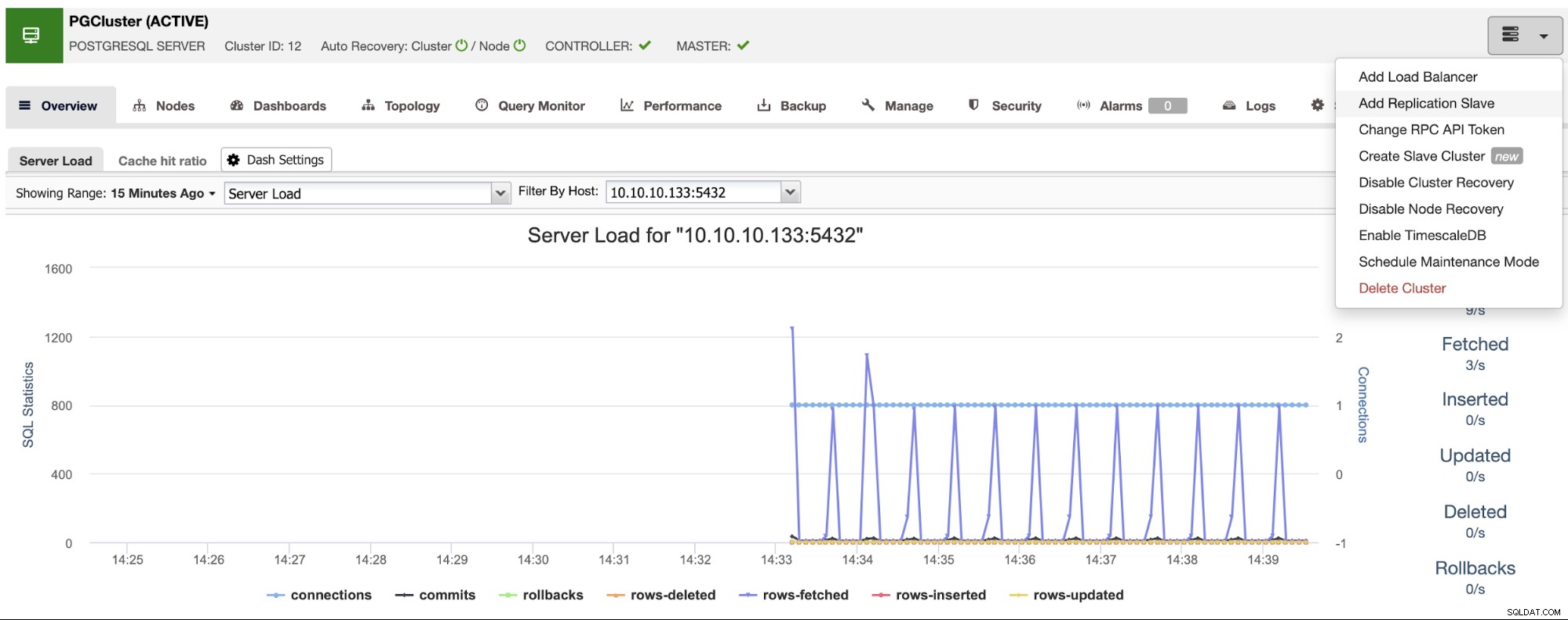
Si siguió los pasos anteriores, tendrá instalado Percona Distribution for PostgreSQL en todos los nodos en espera, por lo que debe deshabilitar "Instalar el software PostgreSQL" en esta sección.
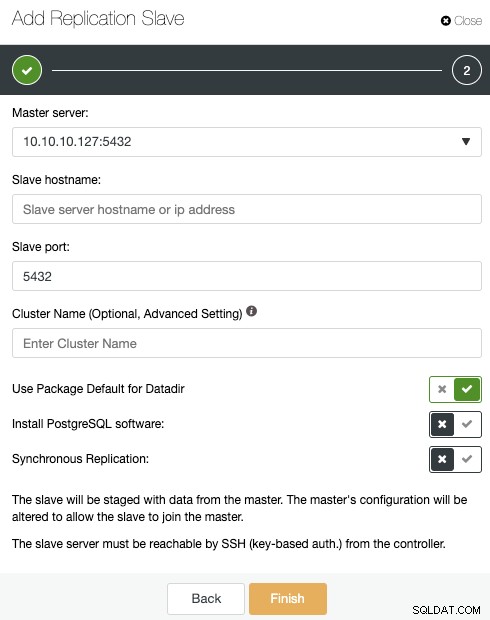
De esta manera, ClusterControl utilizará los paquetes Percona Distribution for PostgreSQL instalados en su lugar de instalar los paquetes oficiales de PostgreSQL.
Cuando termine esto, verá todos los nodos en el clúster y el estado de todos ellos en la sección de descripción general.
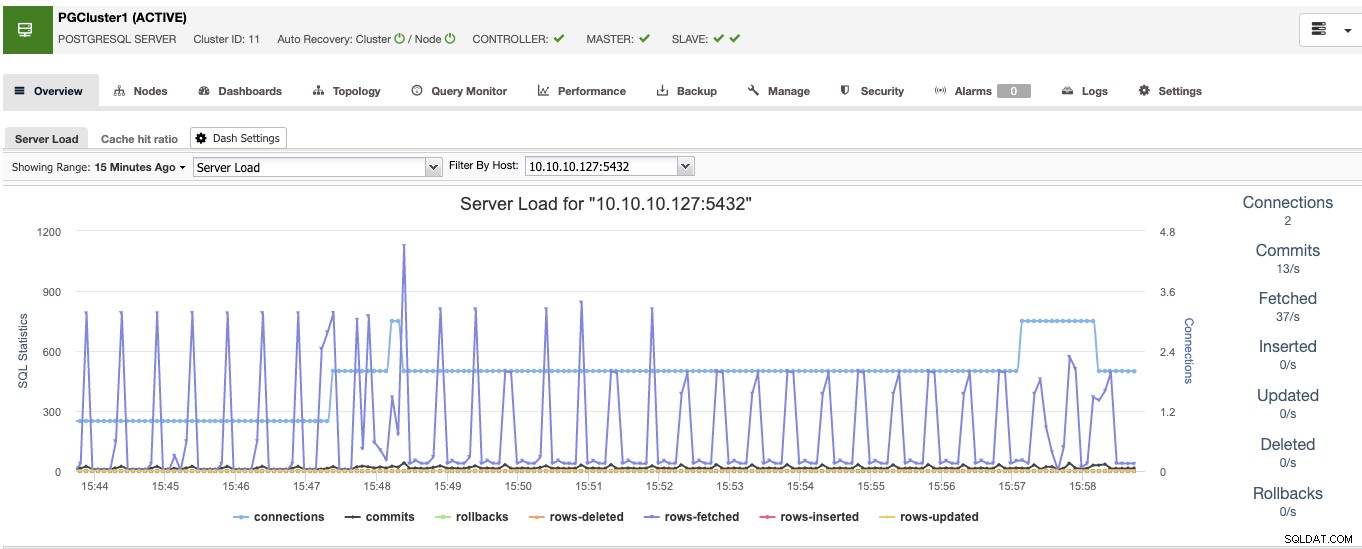
Ahora que tiene el lado de la base de datos listo, veamos cómo completar el High Entorno de disponibilidad añadiendo el resto de herramientas mediante ClusterControl.
Implementación del equilibrador de carga
Para realizar una implementación del balanceador de carga, seleccione la opción "Agregar balanceador de carga" en las acciones del clúster y complete la información solicitada. 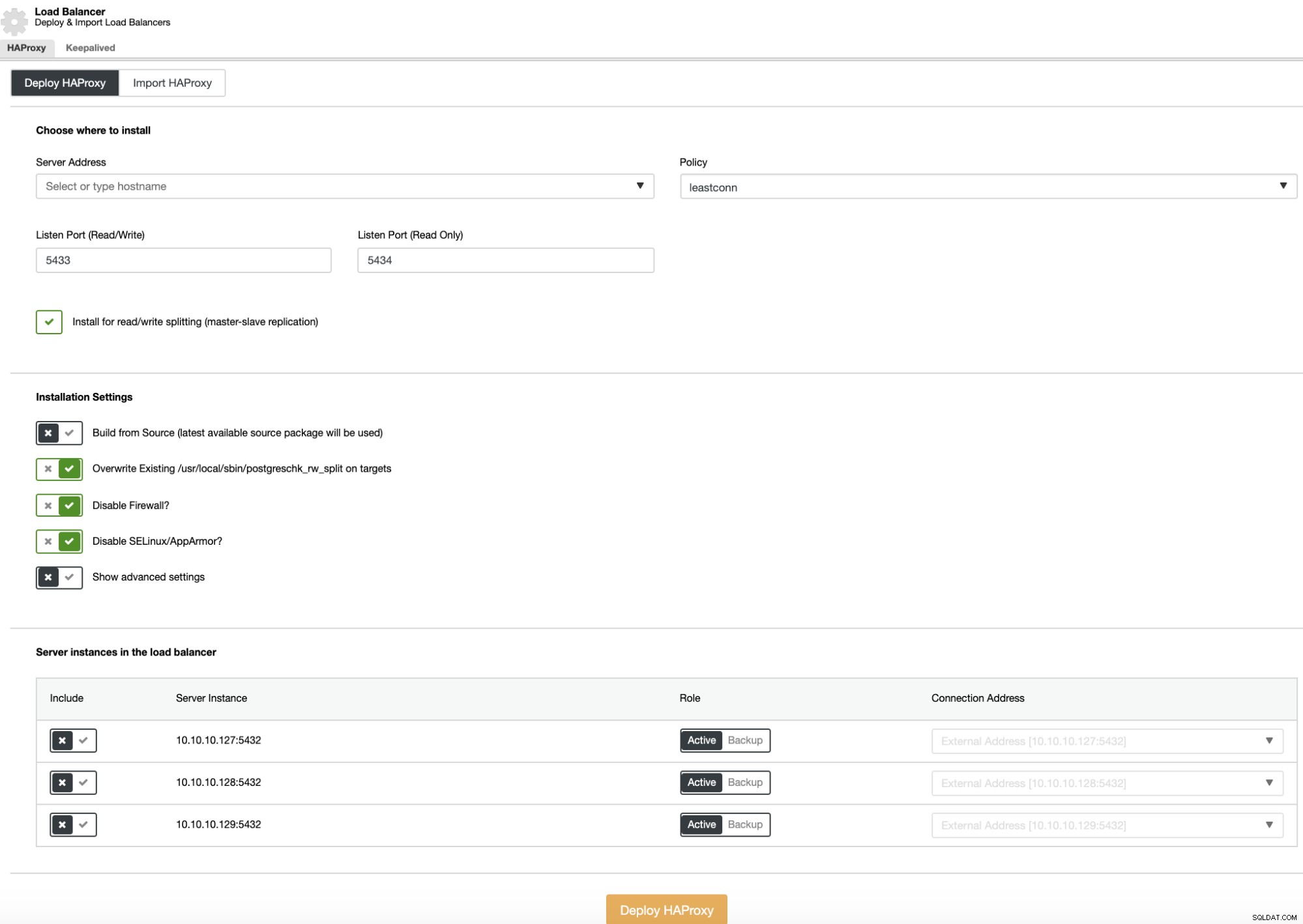
Solo necesita agregar la dirección IP o el nombre de host, el puerto, la política y los nodos que va a agregar a la configuración del balanceador de carga.
Implementación mantenida
Para realizar una implementación de Keepalived, seleccione el clúster, vaya a las acciones del clúster, seleccione "Agregar equilibrador de carga" y luego vaya a la sección "Keepalived".
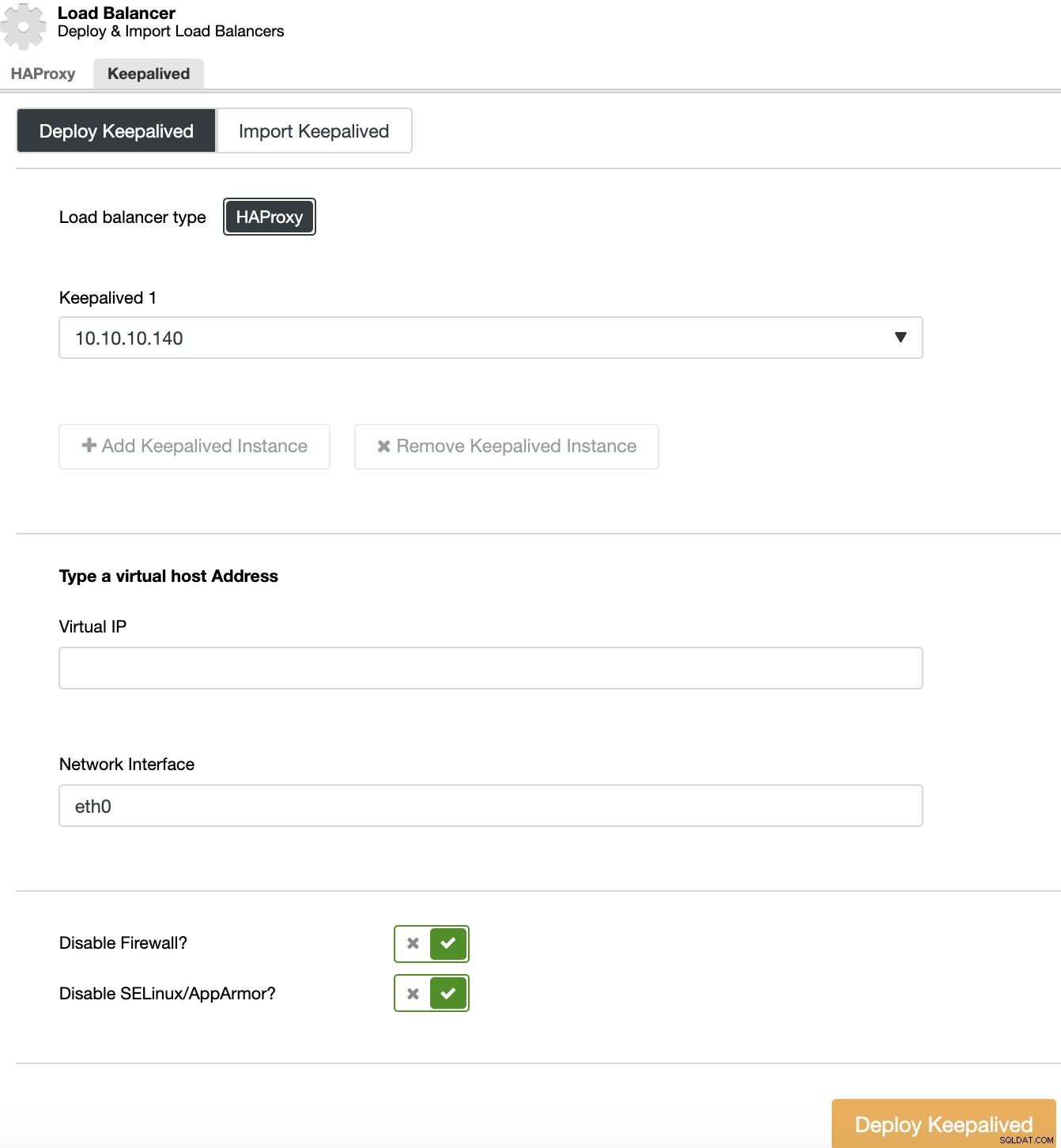
Para su entorno de alta disponibilidad, debe seleccionar los servidores del balanceador de carga y la dirección IP virtual, que deberá usar para acceder a su clúster. Keepalived configura esta IP virtual en el balanceador de carga activo y la migra de un balanceador de carga a otro en caso de falla, para que su configuración pueda continuar funcionando normalmente.
Conclusión
Como aún no puede implementar Percona Distribution para PostgreSQL directamente desde ClusterControl, en este blog le mostramos cómo poder administrarlo usando ClusterControl y cómo agregar diferentes herramientas como HAProxy y Keepalived para tener un entorno de alta disponibilidad. de una manera fácil.