Los problemas de retraso en la replicación en PostgreSQL no son un problema generalizado para la mayoría de las configuraciones. Aunque puede ocurrir y, cuando ocurre, puede afectar sus configuraciones de producción. PostgreSQL está diseñado para manejar varios subprocesos, como el paralelismo de consultas o la implementación de subprocesos de trabajo para manejar tareas específicas en función de los valores asignados en la configuración. PostgreSQL está diseñado para manejar cargas pesadas y estresantes, pero a veces (debido a una mala configuración) su servidor aún puede fallar.
Identificar el retraso de la replicación en PostgreSQL no es una tarea complicada, pero existen algunos enfoques diferentes para analizar el problema. En este blog, veremos qué cosas mirar cuando su replicación de PostgreSQL está retrasada.
Tipos de replicación en PostgreSQL
Antes de profundizar en el tema, veamos primero cómo evoluciona la replicación en PostgreSQL, ya que existen diversos conjuntos de enfoques y soluciones cuando se trata de la replicación.
Warm standby para PostgreSQL se implementó en la versión 8.2 (en 2006) y se basó en el método de trasvase de registros. Esto significa que los registros WAL se mueven directamente de un servidor de base de datos a otro para ser aplicados, o simplemente un enfoque análogo a PITR, o muy parecido a lo que está haciendo con rsync.
Este enfoque, incluso antiguo, todavía se usa hoy en día y algunas instituciones prefieren este enfoque más antiguo. Este enfoque implementa un envío de registros basado en archivos mediante la transferencia de registros WAL de un archivo (segmento WAL) a la vez. Aunque tiene un inconveniente; Una falla importante en los servidores primarios, las transacciones que aún no se hayan enviado se perderán. Hay una ventana para la pérdida de datos (puede ajustar esto usando el parámetro archive_timeout, que se puede establecer en tan solo unos segundos, pero una configuración tan baja aumentará sustancialmente el ancho de banda requerido para el envío de archivos).
En PostgreSQL versión 9.0, se introdujo Streaming Replication. Esta función nos permitió mantenernos más actualizados en comparación con el envío de registros basado en archivos. Su enfoque consiste en transferir registros WAL (un archivo WAL se compone de registros WAL) sobre la marcha (simplemente un envío de registros basado en registros), entre un servidor maestro y uno o varios servidores en espera. Este protocolo no necesita esperar a que se llene el archivo WAL, a diferencia del envío de registros basado en archivos. En la práctica, un proceso denominado receptor WAL, que se ejecuta en el servidor de reserva, se conectará al servidor principal mediante una conexión TCP/IP. En el servidor primario, existe otro proceso llamado remitente WAL. Su función está a cargo de enviar los registros WAL a los servidores en espera a medida que ocurren.
Las configuraciones de replicación asíncrona en la replicación de transmisión pueden provocar problemas como la pérdida de datos o el retraso del esclavo, por lo que la versión 9.1 introduce la replicación síncrona. En la replicación síncrona, cada confirmación de una transacción de escritura esperará hasta que se reciba la confirmación de que la confirmación se ha escrito en el registro de escritura anticipada en el disco del servidor primario y en espera. Este método minimiza la posibilidad de pérdida de datos, ya que para que eso suceda necesitaremos que tanto el maestro como el standby fallen al mismo tiempo.
La desventaja obvia de esta configuración es que aumenta el tiempo de respuesta para cada transacción de escritura, ya que debemos esperar hasta que todas las partes hayan respondido. A diferencia de MySQL, no hay soporte, como en un entorno semi-síncrono de MySQL, volverá a ser asíncrono si se agota el tiempo de espera. Entonces, en Con PostgreSQL, el tiempo para una confirmación es (como mínimo) el viaje de ida y vuelta entre el primario y el de reserva. Las transacciones de solo lectura no se verán afectadas por eso.
A medida que evoluciona, PostgreSQL mejora continuamente y, sin embargo, su replicación es diversa. Por ejemplo, puede usar la replicación asíncrona de transmisión física o la replicación de transmisión lógica. Ambos se monitorean de manera diferente, aunque usan el mismo enfoque al enviar datos a través de la replicación, que sigue siendo replicación de transmisión. Para obtener más detalles, consulte el manual para conocer los diferentes tipos de soluciones en PostgreSQL cuando se trata de la replicación.
Causas del retraso en la replicación de PostgreSQL
Como se definió en nuestro blog anterior, un retraso de replicación es el costo del retraso de las transacciones u operaciones calculado por su diferencia de tiempo de ejecución entre el primario/maestro contra el standby/esclavo nodo.
Dado que PostgreSQL utiliza la replicación de transmisión, está diseñado para ser rápido, ya que los cambios se registran como un conjunto de secuencias de registros (byte por byte) interceptados por el receptor WAL y luego escribe estos registros. al archivo WAL. Luego, el proceso de inicio de PostgreSQL reproduce los datos de ese segmento WAL y comienza la replicación de transmisión. En PostgreSQL, un retraso en la replicación puede ocurrir por estos factores:
- Problemas de red
- No se pudo encontrar el segmento WAL del primario. Por lo general, esto se debe al comportamiento de los puntos de control donde los segmentos WAL se rotan o reciclan
- Nodos ocupados (principal y en espera(s)). Puede ser causado por procesos externos o algunas consultas incorrectas provocadas por un uso intensivo de recursos
- Hardware defectuoso o problemas de hardware que provocan cierto retraso
- Configuración deficiente en PostgreSQL, como la configuración de un pequeño número de max_wal_senders mientras se procesan toneladas de solicitudes de transacciones (o un gran volumen de cambios).
Qué buscar con el retraso de replicación de PostgreSQL
La replicación de PostgreSQL aún es diversa, pero monitorear el estado de la replicación es sutil pero no complicado. En este enfoque que mostraremos, se basa en una configuración primaria-en espera con replicación de transmisión asíncrona. La replicación lógica no puede beneficiar la mayoría de los casos que estamos discutiendo aquí, pero la vista pg_stat_subscription puede ayudarlo a recopilar información. Sin embargo, no nos centraremos en eso en este blog.
Uso de la vista pg_stat_replication
El enfoque más común es ejecutar una consulta que haga referencia a esta vista en el nodo principal. Recuerde, solo puede recopilar información del nodo principal utilizando esta vista. Esta vista contiene la siguiente definición de tabla basada en PostgreSQL 11 como se muestra a continuación:
postgres=# \d pg_stat_replication
View "pg_catalog.pg_stat_replication"
Column | Type | Collation | Nullable | Default
------------------+--------------------------+-----------+----------+---------
pid | integer | | |
usesysid | oid | | |
usename | name | | |
application_name | text | | |
client_addr | inet | | |
client_hostname | text | | |
client_port | integer | | |
backend_start | timestamp with time zone | | |
backend_xmin | xid | | |
state | text | | |
sent_lsn | pg_lsn | | |
write_lsn | pg_lsn | | |
flush_lsn | pg_lsn | | |
replay_lsn | pg_lsn | | |
write_lag | interval | | |
flush_lag | interval | | |
replay_lag | interval | | |
sync_priority | integer | | |
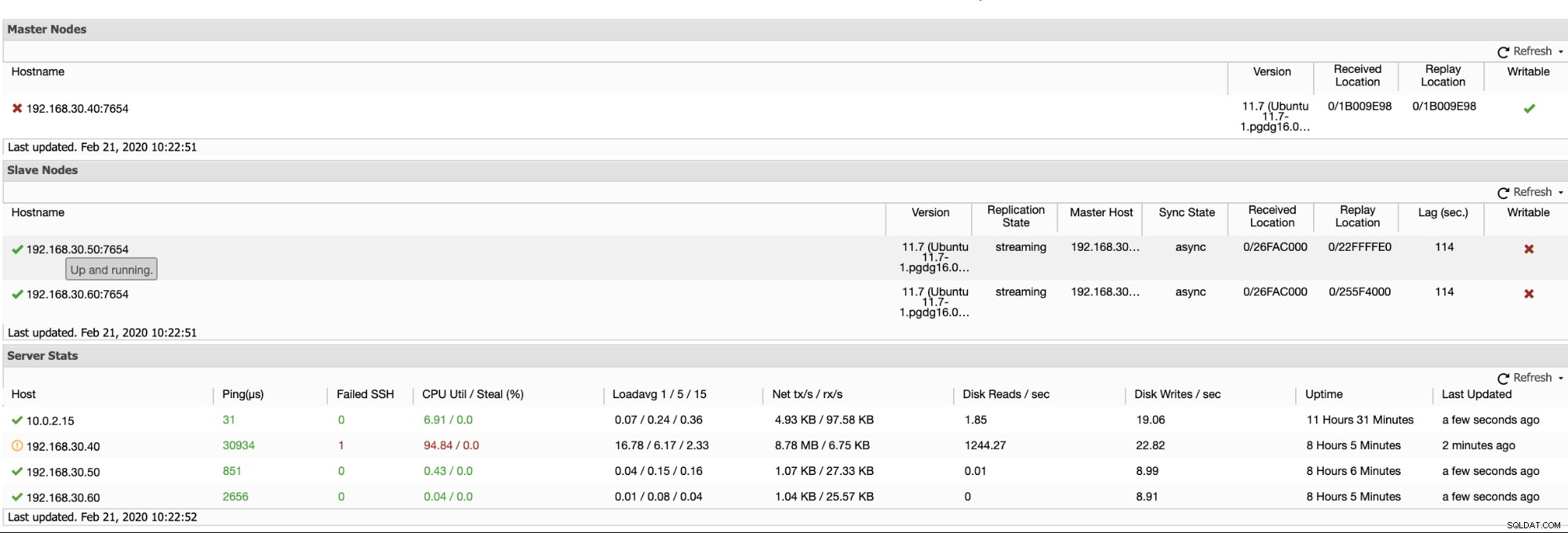
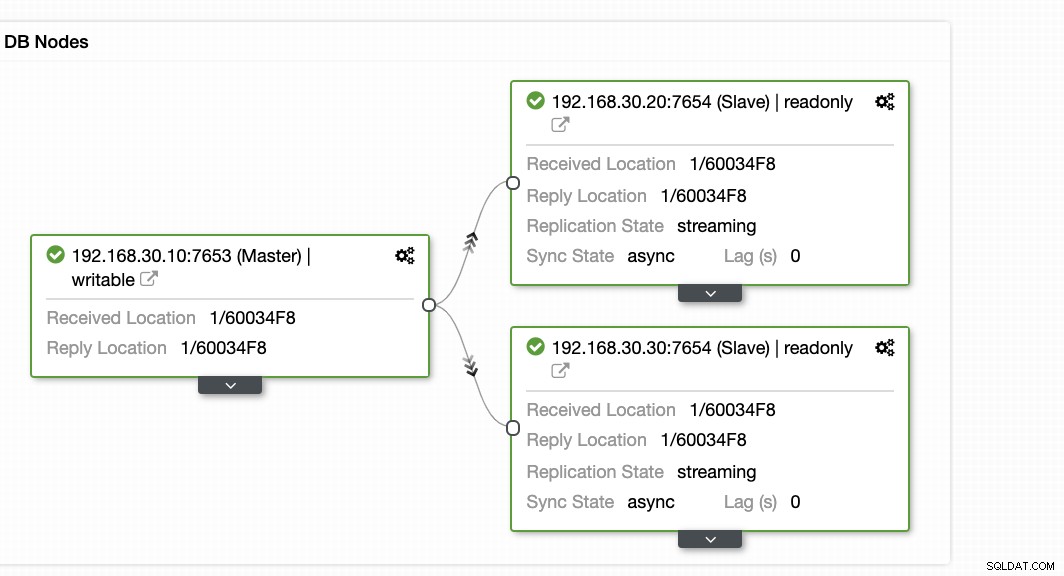
sync_state | text | | | Donde los campos se definen como (incluye PG Una consulta de muestra se vería de la siguiente manera en PostgreSQL 9.6, Esto básicamente le dice qué bloques de ubicación en los segmentos WAL se han escrito, vaciado o aplicado. Le proporciona una visión granular del estado de la replicación. En el nodo en espera, hay funciones compatibles con las que puede mitigar esto en una consulta y brindarle una descripción general del estado de su replicación en espera. Para hacer esto, puede ejecutar la siguiente consulta a continuación (la consulta se basa en la versión PG> 10), En versiones anteriores, puede usar la siguiente consulta: ¿Qué dice la consulta? Las funciones se definen en consecuencia aquí, Usando algunas matemáticas básicas, puede combinar estas funciones. Las funciones más utilizadas por los administradores de bases de datos son, o en versiones PG <10, Aunque esta consulta se ha practicado y es utilizada por DBA. Aún así, no le proporciona una visión precisa del retraso. ¿Por qué? Analicemos esto en la siguiente sección. Los nodos en espera de PostgreSQL, que están en modo de recuperación, no le informan el estado exacto de lo que sucede con su replicación. No, a menos que vea el registro de PG, puede recopilar información de lo que está sucediendo. No hay ninguna consulta que pueda ejecutar para determinar esto. En la mayoría de los casos, las organizaciones e incluso las pequeñas instituciones crean software de terceros para recibir alertas cuando se activa una alarma. Uno de estos es ClusterControl, que le ofrece observabilidad, envía alertas cuando se activan alarmas o recupera su nodo en caso de que ocurra un desastre o una catástrofe. Tomemos este escenario, mi clúster de replicación de transmisión asincrónica primario-en espera ha fallado. ¿Cómo sabrías si algo anda mal? Combinemos lo siguiente: Para versiones anteriores de PG <10, use pg_current_xlog_location. Parece que se ve mal. Ahora, mezclemos la fórmula del paso n.º 1 y del paso n.º 2 y obtengamos la diferencia. Cómo hacer esto, PostgreSQL tiene una función llamada pg_wal_lsn_diff que se define como, pg_wal_lsn_diff(lsn pg_lsn, lsn pg_lsn) / pg_xlog_location_diff (ubicación pg_lsn, ubicación pg_lsn): (numérico) Calcular la diferencia entre dos ubicaciones de registro de escritura anticipada Ahora, usémoslo para determinar el retraso. Puede ejecutarlo en cualquier nodo PG, ya que solo proporcionaremos los valores estáticos: Estimemos cuánto es 1800913104, que parece ser alrededor de 1,6 GiB que podrían haber estado ausentes en el nodo en espera, Por último, puede continuar o incluso antes de la consulta mirar los registros como usar tail -5f para seguir y verificar qué está pasando. Haga esto para los nodos principal/en espera. En este ejemplo, veremos que tiene un problema, Cuando se encuentre con este problema, es mejor reconstruir sus nodos en espera. En ClusterControl, es tan fácil como un clic. Simplemente vaya a la sección Nodos/Topología y reconstruya el nodo como se muestra a continuación: Puede usar el mismo enfoque en nuestro blog anterior (en MySQL), usando herramientas del sistema como ps, top, iostat, combinación de netstat. Por ejemplo, también puede obtener el segmento WAL recuperado actual del nodo en espera, ClusterControl ofrece una manera eficiente de monitorear los nodos de su base de datos desde los nodos primarios hasta los esclavos. Al ir a la pestaña Resumen, ya tiene la vista de su estado de replicación: Básicamente, las dos capturas de pantalla anteriores muestran el estado de la replicación y cuál es el estado actual segmentos WAL. Eso no es en absoluto. ClusterControl también muestra la actividad actual de lo que está pasando con su clúster.
Monitorear el estado de la replicación en PostgreSQL puede terminar con un enfoque diferente siempre que pueda satisfacer sus necesidades. El uso de herramientas de terceros con observabilidad que pueda notificarle en caso de catástrofe es la ruta perfecta, ya sea de código abierto o empresarial. Lo más importante es que tenga su plan de recuperación ante desastres y la continuidad del negocio planeados antes de que surjan tales problemas.
paultest=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 7174
usesysid | 16385
usename | cmon_replication
application_name | pgsql_1_node_1
client_addr | 192.168.30.30
client_hostname |
client_port | 10580
backend_start | 2020-02-20 18:45:52.892062+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | async
-[ RECORD 2 ]----+------------------------------
pid | 7175
usesysid | 16385
usename | cmon_replication
application_name | pgsql_80_node_2
client_addr | 192.168.30.20
client_hostname |
client_port | 60686
backend_start | 2020-02-20 18:45:52.899446+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | asyncConsultas para usar en el nodo en espera
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00postgres=# select pg_is_in_recovery(),pg_last_xlog_receive_location(), pg_last_xlog_replay_location(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_last_xlog_receive_location | 1/9FD6490
pg_last_xlog_replay_location | 1/9FD6490
pg_last_xact_replay_timestamp | 2020-02-21 08:32:40.485958-06
SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
SELECT CASE WHEN pg_last_xlog_receive_location() = pg_last_xlog_replay_location()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;Identificación del retraso causado por la ausencia del segmento WAL
Paso 1:determinar si hay un retraso
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
-[ RECORD 1 ]
log_delay | 0Paso 2:determinar los segmentos WAL recibidos del nodo principal y compararlos con el nodo en espera
## Get the master's current LSN. Run the query below in the master
postgres=# SELECT pg_current_wal_lsn();
-[ RECORD 1 ]------+-----------
pg_current_wal_lsn | 0/925D7E70## Get the current WAL segments received (flushed or applied/replayed)
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Paso 3:Determine qué tan malo podría ser
postgres=# select pg_wal_lsn_diff('0/925D7E70','0/2705BDA0'); -[ RECORD 1 ]---+-----------
pg_wal_lsn_diff | 1800913104postgres=# select round(1800913104/pow(1024,3.0),2) missing_lsn_GiB;
-[ RECORD 1 ]---+-----
missing_lsn_gib | 1.68## Primary
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_033512.log
2020-02-21 16:44:33.574 UTC [25023] ERROR: requested WAL segment 000000030000000000000027 has already been removed
...
## Standby
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_014137.log
2020-02-21 16:45:23.599 UTC [26976] LOG: started streaming WAL from primary at 0/27000000 on timeline 3
2020-02-21 16:45:23.599 UTC [26976] FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000030000000000000027 has already been removed
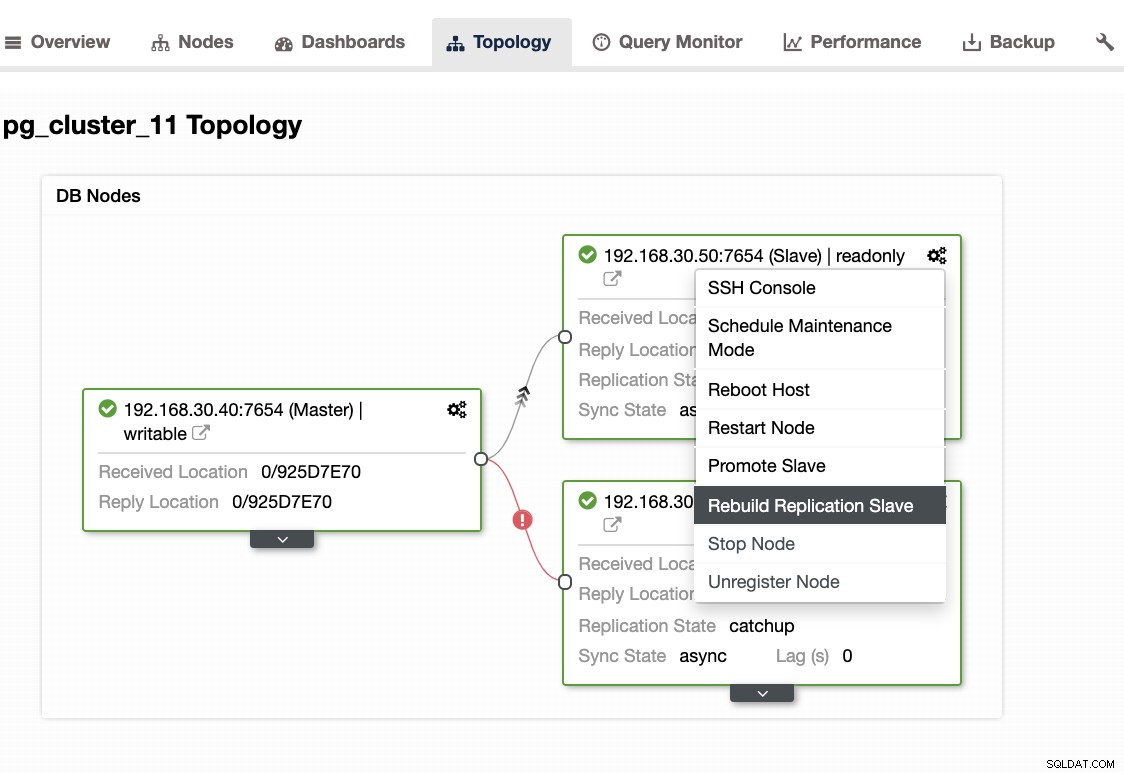
...
Otras cosas para comprobar
example@sqldat.com:/var/lib/postgresql/11/main# ps axufwww|egrep "postgre[s].*startup"
postgres 8065 0.0 8.3 715820 170872 ? Ss 01:41 0:03 \_ postgres: 11/main: startup recovering 000000030000000000000027¿Cómo puede ayudar ClusterControl?
Conclusión



