PostgreSQL Streaming Replication es una excelente manera de escalar clústeres de PostgreSQL y hacerlo les agrega alta disponibilidad. Como con cada replicación, la idea es que el esclavo sea una copia del maestro y que el esclavo se actualice constantemente con los cambios que ocurrieron en el maestro usando algún tipo de mecanismo de replicación.
Puede suceder que el esclavo, por alguna razón, no esté sincronizado con el maestro. ¿Cómo puedo traerlo de vuelta a la cadena de replicación? ¿Cómo puedo asegurarme de que el esclavo vuelva a estar sincronizado con el maestro? Echemos un vistazo a esta breve publicación de blog.
Lo que es muy útil, no hay forma de escribir en un esclavo si está en el modo de recuperación. Puedes probarlo así:
postgres=# SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
postgres=# CREATE DATABASE mydb;
ERROR: cannot execute CREATE DATABASE in a read-only transactionTodavía puede suceder que el esclavo no esté sincronizado con el maestro. Corrupción de datos:ni el hardware ni el software están libres de errores y problemas. Algunos problemas con la unidad de disco pueden provocar la corrupción de datos en el esclavo. Algunos problemas con el proceso de "vacío" pueden provocar la alteración de los datos. ¿Cómo recuperarse de ese estado?
Reconstruyendo el esclavo usando pg_basebackup
El paso principal es aprovisionar el esclavo utilizando los datos del maestro. Dado que usaremos la replicación de transmisión, no podemos usar la copia de seguridad lógica. Afortunadamente, hay una herramienta lista que se puede usar para configurar las cosas:pg_basebackup. Veamos cuáles serían los pasos que debemos seguir para aprovisionar un servidor esclavo. Para que quede claro, estamos usando PostgreSQL 12 para el propósito de esta publicación de blog.
El estado inicial es simple. Nuestro esclavo no se replica de su amo. Los datos que contiene están dañados y no se pueden usar ni confiar. Por lo tanto, el primer paso que haremos será detener PostgreSQL en nuestro esclavo y eliminar los datos que contiene:
example@sqldat.com:~# systemctl stop postgresqlO incluso:
example@sqldat.com:~# killall -9 postgresAhora, revisemos el contenido del archivo postgresql.auto.conf, podemos usar las credenciales de replicación almacenadas en ese archivo más adelante, para pg_basebackup:
example@sqldat.com:~# cat /var/lib/postgresql/12/main/postgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
promote_trigger_file='/tmp/failover_5432.trigger'
recovery_target_timeline=latest
primary_conninfo='application_name=pgsql_0_node_1 host=10.0.0.126 port=5432 user=cmon_replication password=qZnVoV7LV97CFX9F'Estamos interesados en el usuario y la contraseña utilizados para configurar la replicación.
Finalmente, podemos eliminar los datos:
example@sqldat.com:~# rm -rf /var/lib/postgresql/12/main/*Una vez que se eliminan los datos, necesitamos usar pg_basebackup para obtener los datos del maestro:
example@sqldat.com:~# pg_basebackup -h 10.0.0.126 -U cmon_replication -Xs -P -R -D /var/lib/postgresql/12/main/
Password:
waiting for checkpointLas banderas que usamos tienen el siguiente significado:
- -Xs: nos gustaría transmitir WAL mientras se crea la copia de seguridad. Esto ayuda a evitar problemas con la eliminación de archivos WAL cuando tiene un conjunto de datos grande.
- -P: nos gustaría ver el progreso de la copia de seguridad.
- -R: queremos que pg_basebackup cree el archivo standby.signal y prepare el archivo postgresql.auto.conf con la configuración de conexión.
pg_basebackup esperará el punto de control antes de iniciar la copia de seguridad. Si tarda demasiado, puede utilizar dos opciones. Primero, es posible establecer el modo de punto de control en rápido en pg_basebackup usando la opción '-c rápido'. Alternativamente, puede forzar la creación de puntos de control ejecutando:
postgres=# CHECKPOINT;
CHECKPOINTDe una forma u otra, se iniciará pg_basebackup. Con el indicador -P podemos seguir el progreso:
416906/1588478 kB (26%), 0/1 tablespaceceaceUna vez que la copia de seguridad esté lista, todo lo que tenemos que hacer es asegurarnos de que el contenido del directorio de datos tenga asignado el usuario y el grupo correctos. Ejecutamos pg_basebackup como 'raíz', por lo tanto, queremos cambiarlo a 'postgres ':
example@sqldat.com:~# chown -R postgres.postgres /var/lib/postgresql/12/main/Eso es todo, podemos iniciar el esclavo y debería comenzar a replicarse desde el maestro.
example@sqldat.com:~# systemctl start postgresqlPuede volver a verificar el progreso de la replicación ejecutando la siguiente consulta en el maestro:
postgres=# SELECT * FROM pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+------------------+------------------+-------------+-----------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------+-----------+------------+---------------+------------+-------------------------------
23565 | 16385 | cmon_replication | pgsql_0_node_1 | 10.0.0.128 | | 51554 | 2020-02-27 15:25:00.002734+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:32.594213+00
11914 | 16385 | cmon_replication | 12/main | 10.0.0.127 | | 25058 | 2020-02-28 13:42:09.160576+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:42.41722+00
(2 rows)Como puede ver, ambos esclavos se replican correctamente.
Reconstruyendo el esclavo usando ClusterControl
Si es un usuario de ClusterControl, puede lograr fácilmente exactamente lo mismo simplemente eligiendo una opción de la interfaz de usuario.
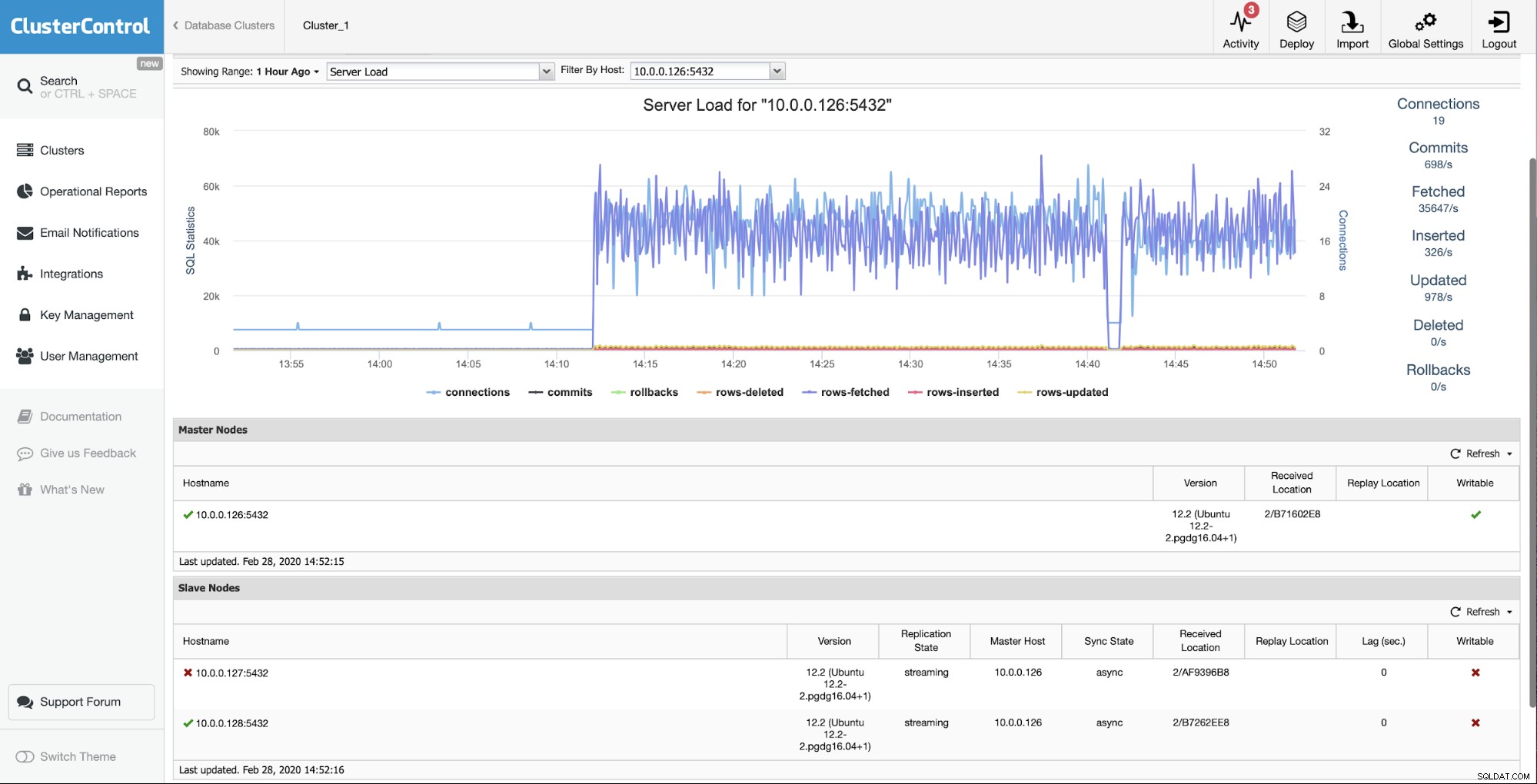
La situación inicial es que uno de los esclavos (10.0.0.127) es no funciona y no se replica. Consideramos que la reconstrucción es la mejor opción para nosotros.
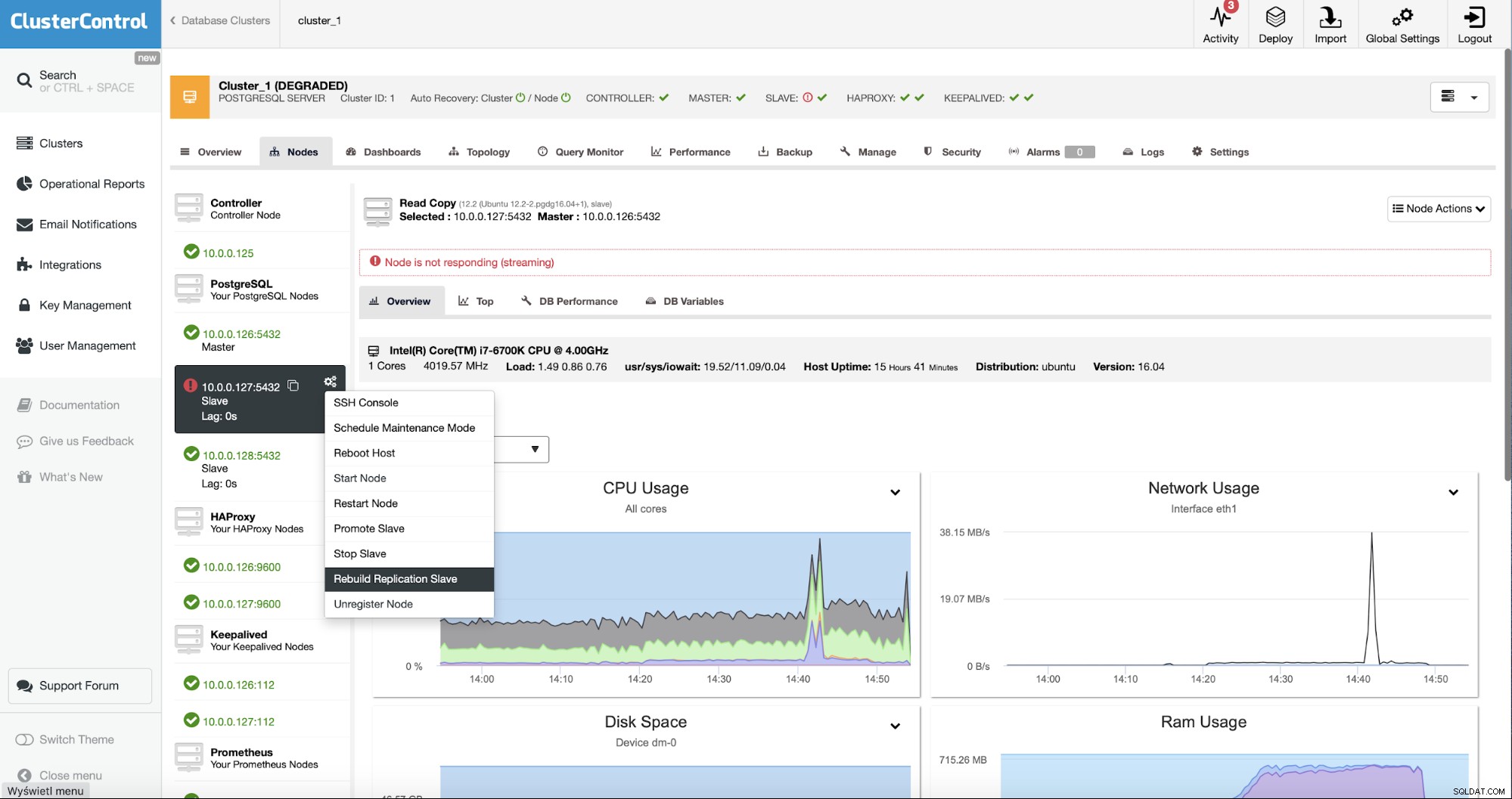
Como usuarios de ClusterControl todo lo que tenemos que hacer es ir a la sección “Nodos ” y ejecute el trabajo “Reconstruir esclavo de replicación”.
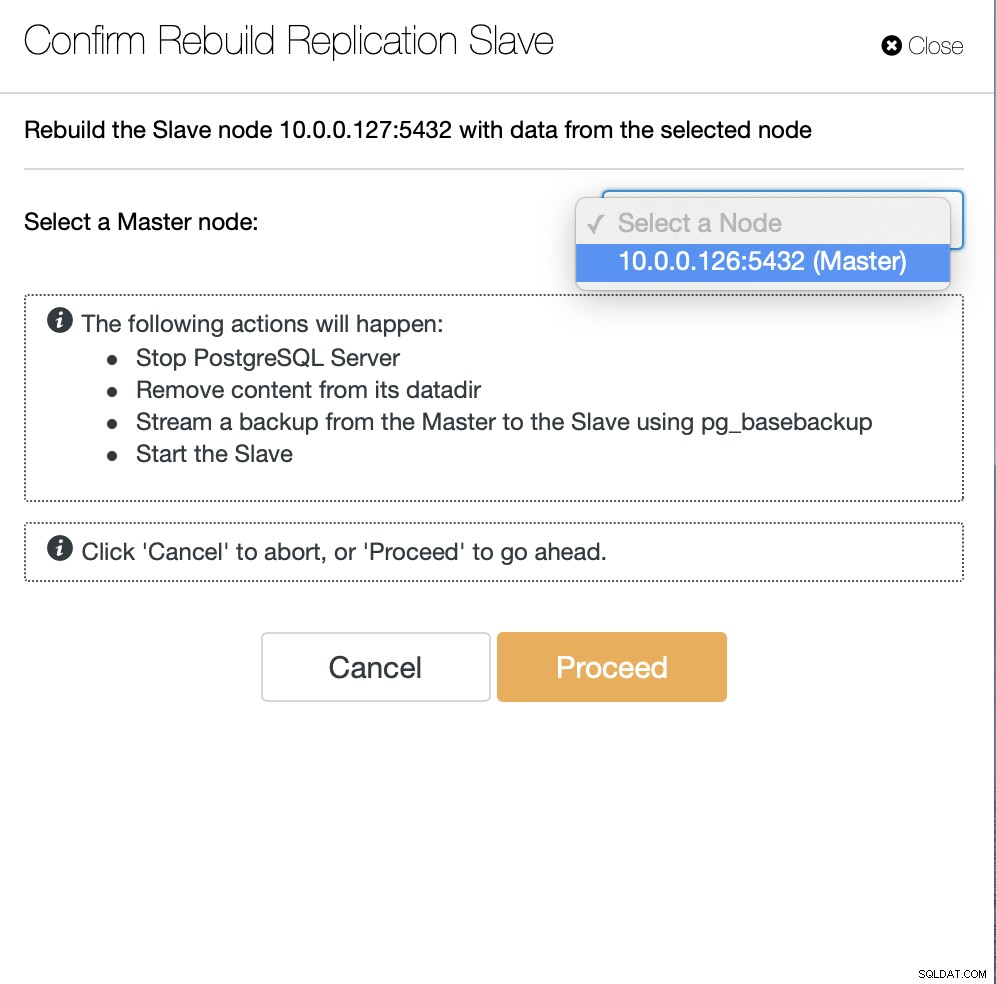
A continuación, tenemos que elegir el nodo desde el que reconstruir el esclavo y eso es todos. ClusterControl utilizará pg_basebackup para configurar el esclavo de replicación y configurar la replicación tan pronto como se transfieran los datos.
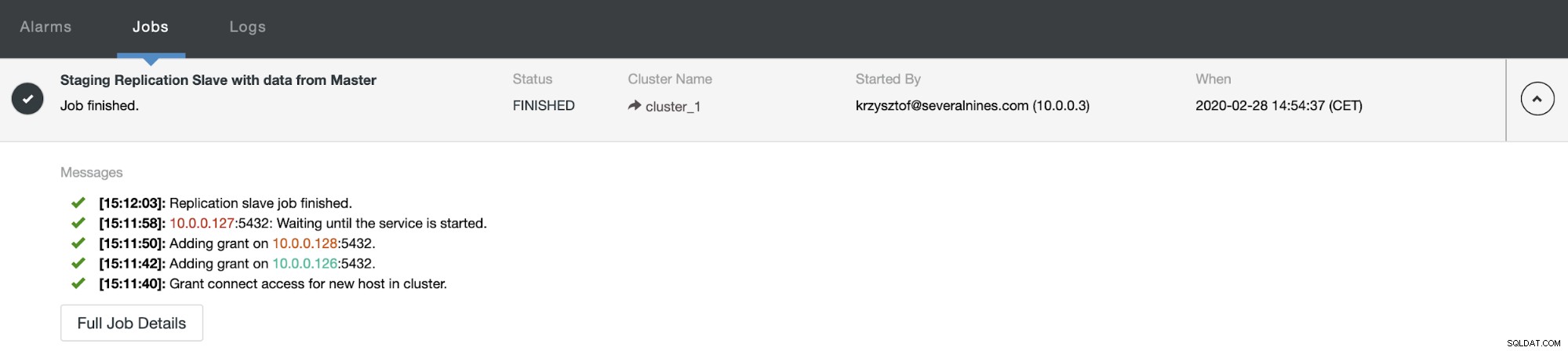
Después de un tiempo, el trabajo se completa y el esclavo vuelve a la cadena de replicación:
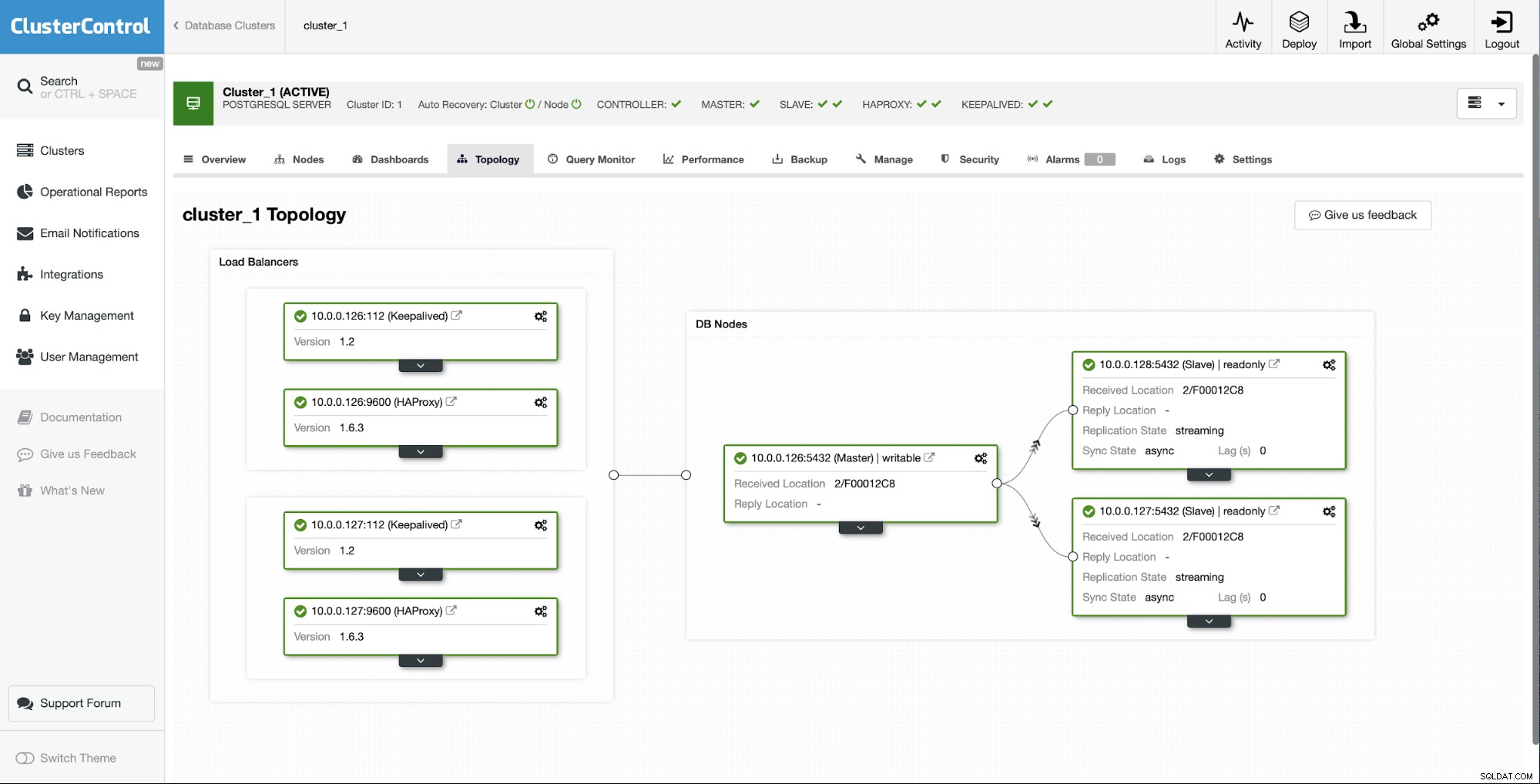
Como puede ver, con solo un par de clics, gracias a ClusterControl, logramos reconstruir nuestro esclavo fallido y devolverlo al clúster.