Este artículo utiliza una consulta simple para explorar algunos aspectos internos profundos relacionados con las consultas de actualización.
Datos de muestra y configuración
El siguiente script de creación de datos de muestra requiere una tabla de números. Si aún no tiene uno de estos, puede usar el siguiente script para crear uno de manera eficiente. La tabla de números resultante contendrá una sola columna de enteros con números del uno al millón:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); La siguiente secuencia de comandos crea una tabla de datos de muestra agrupada con 10 000 ID, con alrededor de 100 fechas de inicio diferentes por ID. La columna de fecha de finalización se establece inicialmente en el valor fijo '99991231'.
CREATE TABLE dbo.Example
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
EndDate date NOT NULL
);
GO
INSERT dbo.Example WITH (TABLOCKX)
(SomeID, StartDate, EndDate)
SELECT DISTINCT
1 + (N.n % 10000),
DATEADD(DAY, 50000 * RAND(CHECKSUM(NEWID())), '20010101'),
CONVERT(date, '99991231', 112)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
CREATE CLUSTERED INDEX
CX_Example_SomeID_StartDate
ON dbo.Example
(SomeID, StartDate)
WITH (MAXDOP = 1, SORT_IN_TEMPDB = ON); Si bien los puntos señalados en este artículo se aplican de manera bastante general a todas las versiones actuales de SQL Server, la información de configuración a continuación se puede usar para garantizar que vea planes de ejecución y efectos de rendimiento similares:
- SQL Server 2012 Service Pack 3 Edición para desarrolladores x64
- Memoria máxima del servidor establecida en 2048 MB
- Cuatro procesadores lógicos disponibles para la instancia
- Sin marcas de rastreo habilitadas
- Nivel de aislamiento confirmado de lectura predeterminado
- Opciones de base de datos RCSI y SI deshabilitadas
Derrames de agregados de hachís
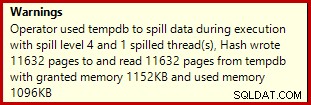
Si ejecuta el script de creación de datos anterior con los planes de ejecución reales habilitados, el agregado de hash puede pasar a tempdb, generando un icono de advertencia:

Cuando se ejecuta en SQL Server 2012 Service Pack 3, se muestra información adicional sobre el derrame en la información sobre herramientas:
Este derrame puede ser sorprendente, dado que las estimaciones de la fila de entrada para Hash Match son exactamente correctas:
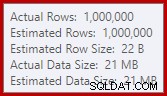
Estamos acostumbrados a comparar estimaciones sobre la entrada para clasificaciones y uniones hash (solo entrada de compilación), pero los agregados hash ansiosos son diferentes. Un agregado hash funciona acumulando filas de resultados agrupadas en la tabla hash, por lo que es el número de salida filas que es importante:
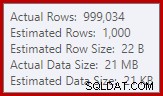
El estimador de cardinalidad en SQL Server 2012 hace una estimación bastante pobre de la cantidad de valores distintos esperados (1000 frente a 999 034 reales); como consecuencia, el agregado de hash se derrama recursivamente al nivel 4 en tiempo de ejecución. El 'nuevo' estimador de cardinalidad disponible en SQL Server 2014 en adelante produce una estimación más precisa para la salida de hash en esta consulta, por lo que no verá un derrame de hash en ese caso:

El número de filas reales puede ser ligeramente diferente para usted, dado el uso de un generador de números pseudoaleatorios en la secuencia de comandos. El punto importante es que los derrames de Hash Aggregate dependen de la cantidad de valores únicos de salida, no del tamaño de entrada.
La especificación de actualización
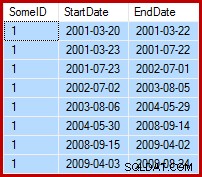
La tarea en cuestión es actualizar los datos de ejemplo de modo que las fechas de finalización se establezcan en el día anterior a la siguiente fecha de inicio (por SomeID). Por ejemplo, las primeras filas de los datos de muestra podrían tener este aspecto antes de la actualización (todas las fechas de finalización establecidas en 9999-12-31):

Luego así después de la actualización:
1. Consulta de actualización de línea base
Una forma razonablemente natural de expresar la actualización requerida en T-SQL es la siguiente:
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate =
ISNULL
(
(
SELECT TOP (1)
DATEADD(DAY, -1, E2.StartDate)
FROM dbo.Example AS E2 WITH (TABLOCK)
WHERE
E2.SomeID = dbo.Example.SomeID
AND E2.StartDate > dbo.Example.StartDate
ORDER BY
E2.StartDate ASC
),
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); El plan de ejecución posterior a la ejecución (real) es:
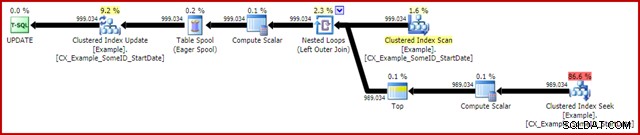
La característica más notable es el uso de un Eager Table Spool para brindar protección de Halloween. Esto es necesario para el correcto funcionamiento aquí debido a la autounión de la tabla de destino de actualización. El efecto es que todo a la derecha del spool se ejecuta hasta el final, almacenando toda la información necesaria para realizar cambios en una tabla de trabajo de tempdb. Una vez que se completa la operación de lectura, los contenidos de la tabla de trabajo se reproducen para aplicar los cambios en el iterador de actualización del índice agrupado.
Rendimiento
Para centrarnos en el potencial de rendimiento máximo de este plan de ejecución, podemos ejecutar la misma consulta de actualización varias veces. Claramente, solo la primera ejecución generará cambios en los datos, pero esto resulta ser una consideración menor. Si esto le molesta, siéntase libre de restablecer la columna de fecha de finalización antes de cada ejecución usando el siguiente código. Los puntos generales que haré no dependen de la cantidad de cambios de datos que se hayan hecho realmente.
UPDATE dbo.Example WITH (TABLOCKX) SET EndDate = CONVERT(date, '99991231', 112);
Con la recopilación del plan de ejecución deshabilitada, todas las páginas requeridas en el grupo de búfer y sin restablecer los valores de fecha de finalización entre ejecuciones, esta consulta generalmente se ejecuta en alrededor de 5700 ms en mi portátil. La salida de E/S de estadísticas es la siguiente:(las lecturas anticipadas y los contadores LOB eran cero y se omiten por razones de espacio)
Table 'Example'. Scan count 999035, logical reads 6186219, physical reads 0 Table 'Worktable'. Scan count 1, logical reads 2895875, physical reads 0
El conteo de escaneo representa el número de veces que se inició una operación de escaneo. Para la tabla de ejemplo, esto es 1 para el escaneo de índice agrupado y 999,034 para cada vez que se rebota la búsqueda de índice agrupado correlacionada. La mesa de trabajo utilizada por Eager Spool tiene una operación de escaneo iniciada solo una vez.
Lecturas lógicas
La información más interesante en la salida de E/S es el número de lecturas lógicas:más de 6 millones para la tabla Ejemplo, y casi 3 millones para la mesa de trabajo.
Las lecturas lógicas de la tabla de ejemplo se asocian principalmente con la búsqueda y la actualización. Seek incurre en 3 lecturas lógicas para cada iteración:1 para cada uno de los niveles raíz, intermedio y hoja del índice. La actualización también cuesta 3 lecturas cada vez que una fila se actualiza, a medida que el motor navega hacia abajo en el árbol b para ubicar la fila de destino. El escaneo de índice agrupado es responsable de solo unos pocos miles de lecturas, una por página leer.
La mesa de trabajo Spool también está estructurada internamente como un árbol b y cuenta múltiples lecturas a medida que el spool ubica la posición de inserción mientras consume su entrada. Tal vez contrariamente a la intuición, el spool no cuenta lecturas lógicas mientras se lee para impulsar la actualización del índice agrupado. Esto es simplemente una consecuencia de la implementación:se cuenta una lectura lógica cada vez que el código ejecuta BPool::Get método. Escribir en el spool llama a este método en cada nivel del índice; la lectura del spool sigue una ruta de código diferente que no llama a BPool::Get en absoluto.
Observe también que la salida de E/S de estadísticas informa un único total para la tabla Ejemplo, a pesar de que tres iteradores diferentes acceden a él en el plan de ejecución (Explorar, Buscar y Actualizar). Este último hecho dificulta la correlación de las lecturas lógicas con el iterador que las provocó. Espero que esta limitación se resuelva en una versión futura del producto.
2. Actualizar usando números de fila
Otra forma de expresar la consulta de actualización consiste en numerar las filas por ID y unir:
WITH Numbered AS
(
SELECT
E.SomeID,
E.StartDate,
E.EndDate,
rn = ROW_NUMBER() OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate ASC)
FROM dbo.Example AS E
)
UPDATE This WITH (TABLOCKX)
SET EndDate =
ISNULL
(
DATEADD(DAY, -1, NextRow.StartDate),
CONVERT(date, '99991231', 112)
)
FROM Numbered AS This
LEFT JOIN Numbered AS NextRow WITH (TABLOCK)
ON NextRow.SomeID = This.SomeID
AND NextRow.rn = This.rn + 1
OPTION (MAXDOP 1, MERGE JOIN); El plan posterior a la ejecución es el siguiente:
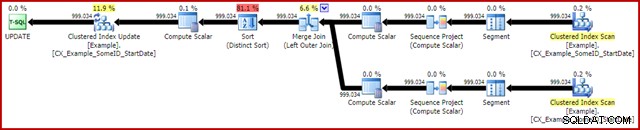
Esta consulta normalmente se ejecuta en 2950 ms en mi computadora portátil, que se compara favorablemente con los 5700ms (en las mismas circunstancias) vistos para la declaración de actualización original. La salida de E/S de estadísticas es:
Table 'Example'. Scan count 2, logical reads 3001808, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Esto muestra dos escaneos iniciados para la tabla Ejemplo (uno para cada iterador de escaneo de índice agrupado). Las lecturas lógicas son nuevamente un agregado sobre todos los iteradores que acceden a esta tabla en el plan de consulta. Como antes, la falta de un desglose hace que sea imposible determinar qué iterador (de los dos análisis y la actualización) fue responsable de los 3 millones de lecturas.
Sin embargo, puedo decirle que los escaneos de índices agrupados cuentan solo unos pocos miles de lecturas lógicas cada uno. La gran mayoría de las lecturas lógicas son causadas por la actualización del índice agrupado que navega hacia abajo en el árbol b del índice para encontrar la posición de actualización para cada fila que procesa. Tendrás que creer en mi palabra por el momento; próximamente habrá más explicaciones.
Las desventajas
Ese es prácticamente el final de las buenas noticias para esta forma de consulta. Funciona mucho mejor que el original, pero es mucho menos satisfactorio por otras razones. El problema principal es causado por una limitación del optimizador, lo que significa que no reconoce que la operación de numeración de filas produce un número único para cada fila dentro de una partición SomeID.
Este simple hecho conduce a una serie de consecuencias indeseables. Por un lado, la combinación de combinación está configurada para ejecutarse en el modo de combinación de muchos a muchos. Esta es la razón de la tabla de trabajo (no utilizada) en las estadísticas IO (la fusión de muchos a muchos requiere una tabla de trabajo para rebobinados de clave de unión duplicada). Esperar una unión de muchos a muchos también significa que la estimación de cardinalidad para la salida de la unión es irremediablemente incorrecta:
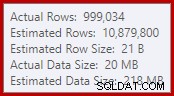
Como consecuencia de eso, Sort solicita demasiada concesión de memoria. Las propiedades del nodo raíz muestran que a Sort le habría gustado tener 812 752 KB de memoria, aunque solo se le otorgaron 379 440 KB debido a la configuración de memoria máxima restringida del servidor (2048 MB). La ordenación usó un máximo de 58 968 KB en tiempo de ejecución:
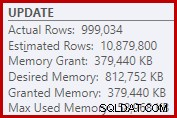
Las concesiones de memoria excesivas roban la memoria de otros usos productivos y pueden generar consultas que esperan hasta que la memoria esté disponible. En muchos aspectos, las concesiones de memoria excesivas pueden ser más problemáticas que las subestimaciones.
La limitación del optimizador también explica por qué era necesaria una sugerencia de combinación de combinación en la consulta para obtener el mejor rendimiento. Sin esta sugerencia, el optimizador evalúa incorrectamente que una combinación hash sería más barata que la combinación de combinación de muchos a muchos. El plan hash join se ejecuta en 3350ms en promedio.
Como consecuencia negativa final, observe que el Tipo en el plan es un Tipo Distinto. Ahora bien, hay un par de razones para ese tipo (sobre todo porque puede proporcionar la protección de Halloween requerida), pero es solo un distinto Ordenar porque el optimizador pierde la información de unicidad. En general, es difícil que me guste mucho este plan de ejecución más allá del rendimiento.
3. Actualizar utilizando la función analítica LEAD
Dado que este artículo se dirige principalmente a SQL Server 2012 y versiones posteriores, podemos expresar la consulta de actualización de forma bastante natural mediante la función analítica LEAD. En un mundo ideal, podríamos usar una sintaxis muy compacta como:
-- Not allowed
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate = LEAD(StartDate) OVER (
PARTITION BY SomeID ORDER BY StartDate); Desafortunadamente, esto no es legal. Da como resultado el mensaje de error 4108, "Las funciones de ventana solo pueden aparecer en las cláusulas SELECT u ORDER BY". Esto es un poco frustrante porque esperábamos un plan de ejecución que pudiera evitar una auto-unión (y la actualización asociada Protección de Halloween).
La buena noticia es que aún podemos evitar la autocombinación mediante una expresión de tabla común o una tabla derivada. La sintaxis es un poco más detallada, pero la idea es más o menos la misma:
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); El plan posterior a la ejecución es:

Esto normalmente se ejecuta en alrededor de 3400ms en mi computadora portátil, que es más lenta que la solución de número de fila (2950 ms) pero mucho más rápida que la original (5700 ms). Una cosa que se destaca del plan de ejecución es el derrame de clasificación (de nuevo, información adicional sobre derrames cortesía de las mejoras en SP3):
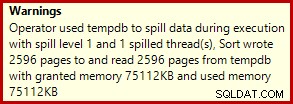
Este es un derrame bastante pequeño, pero aún podría estar afectando el rendimiento hasta cierto punto. Lo extraño de esto es que la estimación de entrada para Sort es exactamente correcta:
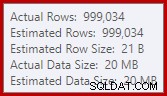
Afortunadamente, hay una "corrección" para esta condición específica en SQL Server 2012 SP2 CU8 (y otras versiones; consulte el artículo de KB para obtener más detalles). Ejecutar la consulta con la corrección y el indicador de rastreo requerido 7470 habilitado significa que Ordenar solicita suficiente memoria para garantizar que nunca se derrame en el disco si no se excede el tamaño de ordenación de entrada estimado.
Consulta de actualización de LEAD sin ordenar el derrame
Para variar, la siguiente consulta habilitada para corrección usa sintaxis de tabla derivada en lugar de una CTE:
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate, CONVERT(date, '99991231', 112)
)
FROM
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
) AS CED
OPTION (MAXDOP 1, QUERYTRACEON 7470); El nuevo plan posterior a la ejecución es:

La eliminación del derrame pequeño mejora el rendimiento de 3400ms a 3250ms . La salida de E/S de estadísticas es:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Si compara esto con las lecturas lógicas de la consulta de filas numeradas, verá que las lecturas lógicas han disminuido de 3 001 808 a 2 999 455, una diferencia de 2 353 lecturas. Esto corresponde exactamente a la eliminación de un solo escaneo de índice agrupado (una lectura por página).
Puede recordar que mencioné que la gran mayoría de las lecturas lógicas para estas consultas de actualización están asociadas con la actualización del índice agrupado y que los escaneos estaban asociados con "solo unos pocos miles de lecturas". Ahora podemos ver esto un poco más directamente al ejecutar una consulta simple de conteo de filas en la tabla Ejemplo:
SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.Example WITH (TABLOCK); SET STATISTICS IO OFF;
La salida de IO muestra exactamente la diferencia de lectura lógica de 2353 entre el número de fila y las actualizaciones de clientes potenciales:
Table 'Example'. Scan count 1, logical reads 2353, physical reads 0
¿Más mejoras?
La consulta de prospectos corregidos por derrame (3250 ms) sigue siendo un poco más lenta que la consulta numerada de doble fila (2950 ms), lo que puede ser un poco sorprendente. Intuitivamente, uno podría esperar que una sola función analítica y de escaneo (Window Spool y Stream Aggregate) sea más rápida que dos escaneos, dos conjuntos de numeración de filas y una unión.
De todos modos, lo que salta a la vista del plan de ejecución de la consulta principal es la clasificación. También estuvo presente en la consulta de filas numeradas, donde contribuyó con la protección de Halloween, así como con un orden de clasificación optimizado para la actualización del índice agrupado (que tiene establecida la propiedad DMLRequestSort).
La cuestión es que este Ordenar es completamente innecesario en el plan de consulta de clientes potenciales. No es necesario para la Protección de Halloween porque la autounión se ha ido. Tampoco es necesario para el orden de clasificación de inserción optimizado:las filas se leen en el orden de la clave agrupada y no hay nada en el plan que altere ese orden. El verdadero problema se puede ver mirando las propiedades de clasificación:

Observe la sección Ordenar por allí. Sort ordena por SomeID y StartDate (las claves de índice agrupadas), pero también por [Uniq1002], que es el uniquificador. Esta es una consecuencia de no declarar el índice agrupado como único, a pesar de que tomamos medidas en la consulta de población de datos para asegurarnos de que la combinación de SomeID y StartDate sería de hecho única. (Esto fue deliberado, así que podría hablar de esto).
Aun así, esto es una limitación. Las filas se leen del índice agrupado en orden y existen las garantías internas necesarias para que el optimizador pueda evitar esta clasificación de forma segura. Es simplemente un descuido que el optimizador no reconozca que el flujo entrante está ordenado por uniquifier, así como por SomeID y StartDate. Reconoce que el orden (SomeID, StartDate) podría conservarse, pero no (SomeID, StartDate, uniquifier). Una vez más, espero que esto se aborde en una versión futura.
Para solucionar esto, podemos hacer lo que deberíamos haber hecho en primer lugar:construir el índice agrupado como único:
CREATE UNIQUE CLUSTERED INDEX CX_Example_SomeID_StartDate ON dbo.Example (SomeID, StartDate) WITH (DROP_EXISTING = ON, MAXDOP = 1);
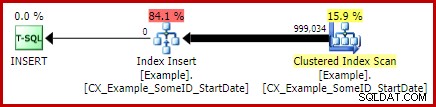
Dejaré como ejercicio para el lector mostrar que las dos primeras consultas (no LEAD) no se benefician de este cambio de indexación (omitido simplemente por razones de espacio, hay mucho que cubrir).
La forma final de la consulta de actualización de prospectos
Con el único índice agrupado en su lugar, exactamente la misma consulta LEAD (CTE o tabla derivada como desee) produce el plan estimado (previo a la ejecución) que esperamos:

Esto parece bastante óptimo. Una única operación de lectura y escritura con un mínimo de operadores intermedios. Ciertamente, parece mucho mejor que la versión anterior con el Sort innecesario, que se ejecutaba en 3250ms una vez que se eliminaba el derrame evitable (a costa de aumentar un poco la concesión de memoria).
El plan posterior a la ejecución (real) es casi exactamente el mismo que el plan previo a la ejecución:

Todas las estimaciones son exactamente correctas, excepto la salida de Window Spool, que está desviada por 2 filas. La información de estadísticas de E/S es exactamente la misma que antes de que se eliminara la ordenación, como era de esperar:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
En resumen, la única diferencia aparente entre este nuevo plan y el inmediatamente anterior es que se ha eliminado el Sort (con una contribución de costes estimada de casi el 80%).
Entonces, puede ser una sorpresa saber que la nueva consulta, sin Ordenar, se ejecuta en 5000ms . Esto es mucho peor que los 3250 ms con Sort, y casi tan largo como la consulta de unión de bucle original de 5700 ms. La solución de numeración de doble fila todavía está muy por delante en 2950ms.
Explicación
La explicación es algo esotérica y se relaciona con la forma en que se manejan los pestillos para la consulta más reciente. Podemos mostrar este efecto de varias maneras, pero la más simple probablemente sea mirar las estadísticas de espera y bloqueo usando DMV:
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
DBCC SQLPERF('sys.dm_os_latch_stats', CLEAR);
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1);
SELECT * FROM sys.dm_os_latch_stats AS DOLS
WHERE DOLS.waiting_requests_count > 0
ORDER BY DOLS.latch_class;
SELECT * FROM sys.dm_os_wait_stats AS DOWS
WHERE DOWS.waiting_tasks_count > 0
ORDER BY DOWS.waiting_tasks_count DESC; Cuando el índice agrupado no es único y hay una Ordenación en el plan, no hay esperas significativas, solo un par de esperas PAGEIOLATCH_UP y los SOS_SCHEDULER_YIELD esperados.
Cuando el índice agrupado es único y se elimina la ordenación, las esperas son:
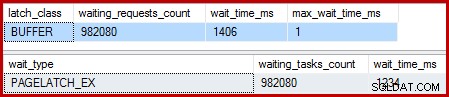
Hay 982.080 pestillos de página exclusivos allí, con un tiempo de espera que explica prácticamente todo el tiempo de ejecución adicional. Para enfatizar, ¡eso es casi una espera de pestillo por fila actualizada! Podríamos esperar un cambio de pestillo por fila, pero no un pestillo esperar , especialmente cuando la consulta de prueba es la única actividad en la instancia. Las esperas de pestillo son cortas, pero hay muchas.
Pestillos perezosos
Tras la ejecución de la consulta con un depurador y un analizador adjuntos, la explicación es la siguiente.
La exploración del índice agrupado utiliza latches perezosos – una optimización que significa que los pestillos solo se liberan cuando otro hilo requiere acceso a la página. Normalmente, los pestillos se liberan inmediatamente después de leer o escribir. Los pestillos perezosos optimizan el caso en el que escanear una página completa adquiriría y liberaría el mismo pestillo de página para cada fila. Cuando se usa el enganche diferido sin contención, solo se toma un enganche único para toda la página.
El problema es que la naturaleza canalizada del plan de ejecución (sin operadores de bloqueo) significa que las lecturas se superponen con las escrituras. Cuando la actualización del índice agrupado intenta adquirir un pestillo EX para modificar una fila, casi siempre encontrará que la página ya está bloqueada SH (el pestillo perezoso tomado por el escaneo del índice agrupado). Esta situación da como resultado una espera de bloqueo.
Como parte de la preparación para esperar y cambiar al siguiente elemento ejecutable en el programador, el código tiene cuidado de liberar los pestillos perezosos. Al soltar el pestillo perezoso, se señala al primer camarero elegible, que resulta ser él mismo. Por lo tanto, tenemos la extraña situación en la que un subproceso se bloquea a sí mismo, libera su pestillo perezoso y luego se señala a sí mismo que se puede ejecutar nuevamente. El hilo se reanuda y continúa, pero solo después de que se haya hecho todo el trabajo de suspensión y cambio, señal y reanudación desperdiciado. Como decía antes, las esperas son cortas, pero hay muchas.
Por lo que sé, esta extraña secuencia de eventos es por diseño y por buenas razones internas. Aun así, no se puede escapar del hecho de que tiene un efecto bastante dramático en el rendimiento aquí. Haré algunas consultas sobre esto y actualizaré el artículo si hay una declaración pública que hacer. Mientras tanto, las esperas excesivas de bloqueo automático pueden ser algo a tener en cuenta con las consultas de actualización canalizadas, aunque no está claro qué se debe hacer al respecto desde el punto de vista del autor de la consulta.
¿Significa esto que el enfoque de doble numeración de filas es lo mejor que podemos hacer para esta consulta? No del todo.
4. Protección manual de Halloween
Esta última opción puede sonar y parecer un poco loca. La idea general es escribir toda la información necesaria para realizar los cambios en una variable de tabla y luego realizar la actualización como un paso separado.
A falta de una mejor descripción, llamo a esto el enfoque de "HP manual" porque es conceptualmente similar a escribir toda la información de cambio en un Eager Table Spool (como se ve en la primera consulta) antes de ejecutar la actualización desde ese Spool.
De todos modos, el código es el siguiente:
DECLARE @U AS table
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
NewEndDate date NULL,
PRIMARY KEY CLUSTERED (SomeID, StartDate)
);
INSERT @U
(SomeID, StartDate, NewEndDate)
SELECT
E.SomeID,
E.StartDate,
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E WITH (TABLOCK)
OPTION (MAXDOP 1);
UPDATE E WITH (TABLOCKX)
SET E.EndDate =
ISNULL
(
U.NewEndDate, CONVERT(date, '99991231', 112)
)
FROM dbo.Example AS E
JOIN @U AS U
ON U.SomeID = E.SomeID
AND U.StartDate = E.StartDate
OPTION (MAXDOP 1, MERGE JOIN); Ese código usa deliberadamente una variable de tabla para evitar el costo de las estadísticas creadas automáticamente en las que incurriría el uso de una tabla temporal. Esto está bien aquí porque sé la forma del plan que quiero y no depende de estimaciones de costos o información estadística.
El único inconveniente de la variable de la tabla (sin un indicador de seguimiento) es que el optimizador normalmente estimará una sola fila y elegirá bucles anidados para la actualización. Para evitar esto, he usado una sugerencia de combinación de combinación. Una vez más, esto se basa en conocer exactamente la forma del plan que se desea lograr.
El plan posterior a la ejecución para la inserción de la variable de la tabla se ve exactamente igual que la consulta que tuvo el problema con las esperas del pestillo:

La ventaja que tiene este plan es que no está cambiando la misma tabla de la que está leyendo. No se requiere protección de Halloween y no hay posibilidad de interferencia del pestillo. Además, hay optimizaciones internas significativas para los objetos tempdb (bloqueo y registro) y también se aplican otras optimizaciones normales de carga masiva. Recuerde que las optimizaciones masivas solo están disponibles para inserciones, no para actualizaciones ni eliminaciones.
El plan posterior a la ejecución de la declaración de actualización es:
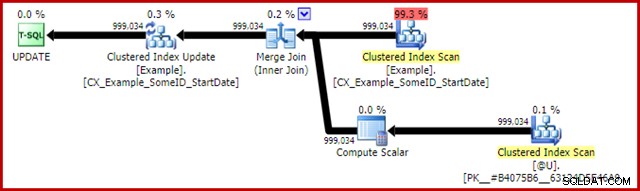
El Merge Join aquí es el tipo eficiente de uno a muchos. Más concretamente, este plan califica para una optimización especial que significa que el análisis del índice agrupado y la actualización del índice agrupado comparten el mismo conjunto de filas. La consecuencia importante es que la actualización ya no tiene que ubicar la fila para actualizar, ya está posicionada correctamente por la lectura. Esto ahorra una gran cantidad de lecturas lógicas (y otra actividad) en la actualización.
No hay nada en los planes de ejecución normales que muestre dónde se aplica esta optimización de conjuntos de filas compartidos, pero habilitar el indicador de seguimiento no documentado 8666 expone propiedades adicionales en la actualización y el análisis que muestran que se está utilizando el uso compartido de conjuntos de filas y que se toman medidas para garantizar que la actualización sea segura del Problema de Halloween.
La salida de E/S de estadísticas para las dos consultas es la siguiente:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0 Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 (999034 row(s) affected) Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 Table '#B9C034B8'. Scan count 1, logical reads 2353, physical reads 0
Ambas lecturas de la tabla de ejemplo implican un solo escaneo y una lectura lógica por página (consulte la consulta simple de recuento de filas anterior). La tabla #B9C034B8 es el nombre del objeto tempdb interno que respalda la variable de la tabla. El total de lecturas lógicas para ambas consultas es 3 * 2353 =7059. La mesa de trabajo es el almacenamiento interno en memoria utilizado por Window Spool.
El tiempo de ejecución típico para esta consulta es 2300ms . Finalmente, tenemos algo que supera la consulta de doble numeración de filas (2950 ms), por improbable que parezca.
Reflexiones finales
Puede haber formas aún mejores de escribir esta actualización que funcionen incluso mejor que la solución "manual HP" anterior. Los resultados de rendimiento pueden incluso ser diferentes en su configuración de hardware y SQL Server, pero ninguno de estos es el punto principal de este artículo. Eso no quiere decir que no esté interesado en ver mejores consultas o comparaciones de rendimiento, lo estoy.
El punto es que suceden muchas más cosas dentro de SQL Server de lo que se expone en los planes de ejecución. Con suerte, algunos de los detalles discutidos en este artículo bastante largo serán interesantes o incluso útiles para algunas personas.
Es bueno tener expectativas de rendimiento y saber qué formas y propiedades del plan son generalmente beneficiosas. Ese tipo de experiencia y conocimiento le servirán bien para el 99% o más de las consultas que alguna vez se le pedirá que sintonice. A veces, sin embargo, es bueno probar algo un poco extraño o inusual solo para ver qué sucede y validar esas expectativas.