En términos generales, el mejor tipo de Clasificación es la que se evita por completo. Con una indexación cuidadosa y, a veces, una escritura creativa de consultas, a menudo podemos eliminar la necesidad de un operador Ordenar de los planes de ejecución. Cuando los datos a clasificar son grandes, evitar este tipo de clasificación puede producir mejoras de rendimiento muy significativas.
El segundo mejor tipo de clasificación es el que no podemos evitar, pero que reserva una cantidad adecuada de memoria y utiliza toda o la mayor parte para hacer algo que valga la pena. Ser valioso puede tomar muchas formas. A veces, una ordenación puede pagarse por sí sola al habilitar una operación posterior que funciona de manera mucho más eficiente en la entrada ordenada. Otras veces, Sort es simplemente necesario, y solo debemos hacerlo lo más eficiente posible.
Luego vienen los Tipos que normalmente queremos evitar:los que reservan mucha más memoria de la que necesitan y los que reservan muy poca. Este último caso es en el que la mayoría de la gente se centra. Con memoria reservada (o disponible) insuficiente para completar la operación de clasificación requerida en la memoria, un operador Sort, con pocas excepciones, derramará filas de datos en tempdb . En realidad, esto casi siempre significa escribir páginas de clasificación en el almacenamiento físico (y volver a leerlas más tarde, por supuesto).
En las versiones modernas de SQL Server, una clasificación derramada genera un icono de advertencia en los planes posteriores a la ejecución, que pueden incluir detalles sobre la cantidad de datos derramados, la cantidad de subprocesos involucrados y el nivel de derrame.
Antecedentes:niveles de derrame
Considere la tarea de ordenar 4000 MB de datos, cuando solo tenemos 500 MB de memoria disponible. Obviamente, no podemos ordenar todo el conjunto en la memoria a la vez, pero podemos dividir la tarea:
Primero leemos 500 MB de datos, ordenamos ese conjunto en la memoria y luego escribimos el resultado en el disco. Realizar esto un total de 8 veces consume toda la entrada de 4000 MB, lo que da como resultado 8 conjuntos de datos ordenados de 500 MB de tamaño. El segundo paso es realizar una combinación de 8 vías de los conjuntos de datos ordenados. Tenga en cuenta que una fusión se requiere, no una simple concatenación de los conjuntos, ya que solo se garantiza que los datos se ordenarán según sea necesario dentro de un conjunto particular de 500 MB en la etapa intermedia.
En principio, podríamos leer y fusionar una fila a la vez de cada una de las ocho ejecuciones de clasificación, pero esto no sería muy eficiente. En cambio, leemos la primera parte de cada tipo que se ejecuta en la memoria, digamos 60 MB. Esto consume 8 x 60 MB =480 MB de los 500 MB que tenemos disponibles. Luego, podemos realizar de manera eficiente la combinación de 8 vías en la memoria durante un tiempo, almacenando en búfer la salida ordenada final con la memoria de 20 MB aún disponible. A medida que se vacía cada uno de los búferes de memoria de ejecución de clasificación, leemos una nueva sección de esa ejecución de clasificación en la memoria. Una vez que se han consumido todas las ejecuciones de clasificación, la clasificación está completa.
Hay algunos detalles adicionales y optimizaciones que podemos incluir, pero ese es el esquema básico de un derrame de Nivel 1, también conocido como derrame de un solo paso. Se requiere una sola pasada adicional sobre los datos para producir la salida ordenada final.
Ahora, una fusión de n vías teóricamente podría acomodar un tipo de cualquier tamaño, en cualquier cantidad de memoria, simplemente aumentando el número de conjuntos intermedios ordenados localmente. El problema es que a medida que aumenta 'n', terminamos leyendo y escribiendo fragmentos de datos más pequeños. Por ejemplo, clasificar 400 GB de datos en 500 MB de memoria significaría algo así como una combinación de 800 vías, con solo alrededor de 0,6 MB de cada conjunto clasificado intermedio en la memoria en cualquier momento (800 x 0,6 MB =480 MB, dejando algo de espacio para un búfer de salida).
Se pueden usar varios pases de combinación para evitar esto. La idea general es fusionar progresivamente pequeños fragmentos en otros más grandes, hasta que podamos producir eficientemente el flujo de salida ordenado final. En el ejemplo, esto podría significar fusionar 40 de los 800 conjuntos ordenados de primer paso a la vez, lo que da como resultado 20 fragmentos más grandes, que luego se pueden fusionar nuevamente para formar la salida. Con un total de dos pasadas adicionales sobre los datos, esto sería un derrame de Nivel 2, y así sucesivamente. Afortunadamente, un aumento lineal en el nivel de derrame permite un aumento exponencial en el tamaño de clasificación, por lo que los niveles de derrame de clasificación profunda rara vez son necesarios.
El derrame de "Nivel 15,000"
En este punto, es posible que se pregunte qué combinación de concesión de memoria pequeña y tamaño de datos enorme podría resultar en un derrame de clasificación de nivel 15,000. ¿Intenta ordenar todo Internet en 1 MB de memoria? Posiblemente, pero eso es demasiado difícil de demostrar. Para ser honesto, no tengo idea de si un nivel de derrame tan genuinamente alto es posible en SQL Server. El objetivo aquí (un truco, sin duda) es hacer que SQL Server informe un derrame de nivel 15,000.
El ingrediente clave es la partición. Desde SQL Server 2012, se nos ha permitido un (conveniente) máximo de 15 000 particiones por objeto (el soporte para 15 000 particiones también está disponible en 2008 SP2 y 2008 R2 SP1, pero debe habilitarlo manualmente por base de datos y tener en cuenta todas las las advertencias).
Lo primero que necesitaremos es una función de partición de 15.000 elementos y un esquema de partición asociado. Para evitar un bloque de código en línea verdaderamente enorme, el siguiente script usa SQL dinámico para generar las declaraciones requeridas:
DECLARE
@sql nvarchar(max) =
N'
CREATE PARTITION FUNCTION PF (integer)
AS RANGE LEFT
FOR VALUES
(1';
DECLARE @i integer = 2;
WHILE @i < 15000
BEGIN
SET @sql += N',' + CONVERT(nvarchar(5), @i);
SET @i += 1;
END;
SET @sql = @sql + N');';
EXECUTE (@sql);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]); La secuencia de comandos es bastante fácil de modificar a un número más bajo en caso de que su configuración tenga problemas con 15,000 particiones (particularmente desde el punto de vista de la memoria, como veremos en breve). Los siguientes pasos son crear una tabla de montón normal (no particionada) con una sola columna de enteros y luego llenarla con los enteros del 1 al 15 000 inclusive:
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test1 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Eso debería completarse en 100ms más o menos. Si tiene una tabla de números disponible, siéntase libre de usarla para una experiencia más basada en conjuntos. La forma en que se completa la tabla base no es importante. Para obtener nuestro derrame de nivel 15,000, todo lo que necesitamos hacer ahora es crear un índice agrupado particionado en la tabla:
CREATE UNIQUE CLUSTERED INDEX CUQ ON dbo.Test1 (c1) WITH (MAXDOP = 1) ON PS (c1);
El tiempo de ejecución depende mucho del sistema de almacenamiento en uso. En mi computadora portátil, usando un SSD de consumo bastante típico de hace un par de años, toma alrededor de 20 segundos, lo cual es bastante significativo considerando que solo estamos tratando con 15,000 filas en total. En una máquina virtual de Azure con especificaciones bastante bajas y un rendimiento de E/S bastante terrible, la misma prueba tomó cerca de 20 minutos.
Análisis
El plan de ejecución para la construcción del índice es:
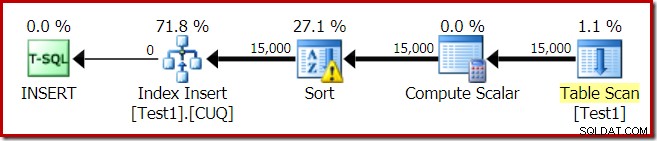
Table Scan lee las 15 000 filas de nuestra tabla de almacenamiento dinámico. Compute Scalar calcula el número de partición del índice de destino para cada fila mediante la función interna RangePartitionNew() . La clasificación es la parte más interesante del plan, por lo que la veremos con más detalle.
Primero, la advertencia de clasificación, como se muestra en Plan Explorer:

Una advertencia similar de SSMS (tomada de una ejecución diferente del script):
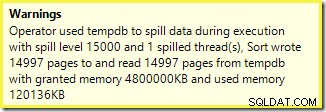
Lo primero a tener en cuenta es el informe de un nivel de derrame de tipo 15,000, como se prometió. Esto no es del todo exacto, pero los detalles son bastante interesantes. La clasificación en este plan tiene un Partition ID propiedad, que normalmente no está presente:
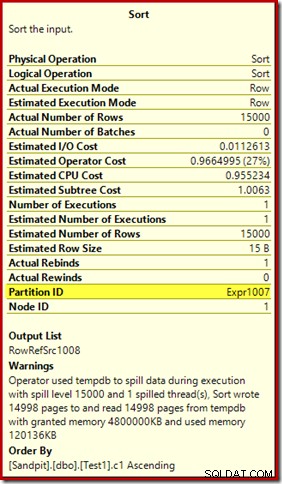
Esta propiedad se establece igual a la definición de función de partición interna en Compute Scalar.
Esta es una construcción de índice no alineado , porque el origen y el destino tienen arreglos de partición diferentes. En este caso, esa diferencia surge porque la tabla del montón de origen no está particionada, pero el índice de destino sí lo está. Como consecuencia, se crean 15 000 clasificaciones separadas en tiempo de ejecución:una por partición de destino no vacía. Cada una de estas clasificaciones llega al nivel 1 y SQL Server suma todas estas clasificaciones para dar el nivel de clasificación final de 15 000.
Los 15.000 tipos separados explican la gran concesión de memoria. Cada instancia de clasificación tiene un tamaño mínimo de 40 páginas, que es 40 x 8 KB =320 KB. Por lo tanto, las 15 000 clasificaciones requieren 15 000 x 320 KB =4 800 000 KB de memoria como mínimo. Eso es apenas por debajo de los 4,6 GB de RAM reservados exclusivamente para una consulta que ordena 15 000 filas que contienen una sola columna de enteros. ¡Y cada tipo se derrama en el disco, a pesar de recibir solo una fila! Si se usara el paralelismo para la construcción del índice, la concesión de memoria podría aumentar aún más por la cantidad de subprocesos. Tenga en cuenta también que la única fila está escrita en una página, lo que explica el número de páginas escritas y leídas de tempdb. Parece haber una condición de carrera que significa que el número de páginas notificado suele ser inferior a 15 000.
Este ejemplo refleja un caso límite, por supuesto, pero todavía es difícil entender por qué cada clasificación derrama su única fila en lugar de clasificar en la memoria que se le ha dado. Tal vez esto sea por diseño por alguna razón, o tal vez sea simplemente un error. Cualquiera que sea el caso, todavía es bastante entretenido ver una especie de unos pocos cientos de KB de datos tardando tanto con una concesión de memoria de 4,6 GB y un derrame de nivel de 15.000. A menos que lo encuentre en un entorno de producción, tal vez. De todos modos, es algo a tener en cuenta.
El engañoso informe de derrame de nivel 15,000 se reduce básicamente a las limitaciones de representación en la salida del plan de espectáculos. El problema fundamental es algo que surge en muchos lugares donde ocurren acciones repetidas, por ejemplo, en el lado interno de la unión de bucles anidados. Sin duda, sería útil poder ver un desglose más preciso en lugar de un total general en estos casos. Con el tiempo, esta área ha mejorado un poco, por lo que ahora tenemos más información del plan por subproceso o por partición para algunas operaciones. Sin embargo, todavía queda un largo camino por recorrer.
Todavía no es útil que 15 000 derrames de nivel 1 separados se notifiquen aquí como un solo derrame de nivel 15 000.
Variaciones de prueba
Este artículo se trata más de resaltar las limitaciones de la información del plan y el potencial de bajo rendimiento cuando se usa un número extremo de particiones, que de hacer que la operación de ejemplo en particular sea más eficiente, pero también hay un par de variaciones interesantes que quiero ver. .
En línea, ordenar en tempdb
Realizando la misma operación de creación de índice particionado con ONLINE = ON, SORT_IN_TEMPDB = ON no sufre de la misma enorme concesión de memoria y derrame:
CREATE TABLE dbo.Test2
(
c1 integer NOT NULL
);
-- Copy the sample data
INSERT dbo.Test2 WITH (TABLOCKX)
(c1)
SELECT
T1.c1
FROM dbo.Test1 AS T1
OPTION (MAXDOP 1);
-- Partitioned clustered index build
CREATE CLUSTERED INDEX CUQ
ON dbo.Test2 (c1)
WITH (MAXDOP = 1, ONLINE = ON, SORT_IN_TEMPDB = ON)
ON PS (c1);
Tenga en cuenta que usar ONLINE por sí sola no es suficiente. De hecho, eso da como resultado el mismo plan que antes con los mismos problemas, más una sobrecarga adicional para construir cada partición de índice en línea. Para mí, eso da como resultado un tiempo de ejecución de más de un minuto. Dios sabe cuánto tiempo llevaría una instancia de Azure de baja especificación con un rendimiento de E/S espantoso.
De todos modos, el plan de ejecución con ONLINE = ON, SORT_IN_TEMPDB = ON es:

La clasificación se realiza antes de que se calcule el número de partición de destino. No tiene la propiedad ID de partición, por lo que es simplemente una ordenación normal. Toda la operación se ejecuta durante unos diez segundos (aún quedan muchas particiones por crear). Reserva menos de 3 MB de memoria y utiliza un máximo de 816 KB. Una gran mejora con respecto a 4,6 GB y 15 000 derrames.
Primero el índice, luego los datos
Se pueden obtener resultados similares escribiendo primero los datos en una tabla heap:
-- Heap source
CREATE TABLE dbo.SourceData
(
c1 integer NOT NULL
);
-- Add data
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.SourceData (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; A continuación, cree una tabla agrupada con particiones vacía e inserte los datos del montón:
-- Destination table
CREATE TABLE dbo.Test3
(
c1 integer NOT NULL
)
ON PS (c1); -- Optional
-- Partitioned Clustered Index
CREATE CLUSTERED INDEX CUQ
ON dbo.Test3 (c1)
ON PS (c1);
-- Add data
INSERT dbo.Test3 WITH (TABLOCKX)
(c1)
SELECT
SD.c1
FROM dbo.SourceData AS SD
OPTION (MAXDOP 1);
-- Clean up
DROP TABLE dbo.SourceData; Esto toma alrededor de diez segundos, con una concesión de memoria de 2 MB y sin derrames:
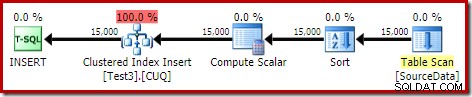
Por supuesto, la ordenación también podría evitarse por completo indexando la tabla de origen (sin particiones) e insertando los datos en el orden del índice (la mejor ordenación es no ordenar en absoluto, recuerde).
Montón particionado, luego datos, luego índice
Para esta última variación, primero creamos un montón con particiones y cargamos las 15 000 filas de prueba:
CREATE TABLE dbo.Test4
(
c1 integer NOT NULL
)
ON PS (c1);
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test4 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Ese script se ejecuta durante uno o dos segundos, lo cual es bastante bueno. El último paso es crear el índice agrupado particionado:
CREATE CLUSTERED INDEX CUQ ON dbo.Test4 (c1) WITH (MAXDOP = 1) ON PS (c1);
Eso es un completo desastre, tanto desde el punto de vista del rendimiento como desde la perspectiva de la información del plan de espectáculos. La operación en sí se ejecuta durante poco menos de un minuto, con el siguiente plan de ejecución:

Este es un plan de inserción coubicado. Constant Scan contiene una fila para cada ID de partición. El lado interior del bucle busca la partición actual del montón (sí, una búsqueda en un montón). La ordenación tiene una propiedad de identificación de partición (a pesar de que esto es constante por iteración de ciclo), por lo que hay una ordenación por partición y el comportamiento de derrame no deseado. La advertencia de estadísticas en la tabla del montón es falsa.
La raíz del plan de inserción indica que se reservó una concesión de memoria de 1 MB, con un máximo de 144 KB utilizados:
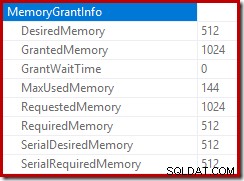
El operador de clasificación no informa un derrame de nivel 15,000, pero por lo demás hace un completo lío de las matemáticas de iteración por ciclo involucradas:

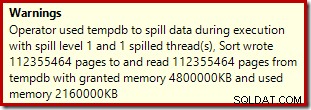
Supervisar la memoria otorgada por DMV durante la ejecución muestra que esta consulta en realidad reserva solo 1 MB, con un máximo de 144 KB utilizados en cada iteración del bucle. (Por el contrario, la reserva de memoria de 4,6 GB en la primera prueba es absolutamente genuina). Esto es confuso, por supuesto.
El problema (como se mencionó anteriormente) es que SQL Server se confunde acerca de la mejor manera de informar sobre lo que sucedió en muchas iteraciones. Probablemente no sea práctico incluir información de rendimiento del plan por partición por iteración, pero no se puede evitar el hecho de que el arreglo actual produce resultados confusos a veces. Solo podemos esperar que algún día se pueda encontrar una mejor manera de reportar este tipo de información, en un formato más consistente.