SQL Server introdujo objetos OLTP en memoria en SQL Server 2014. Había muchas limitaciones en la versión inicial; algunos se han abordado en SQL Server 2016 y se espera que se aborden más en la próxima versión a medida que la función continúa evolucionando. Hasta el momento, la adopción de In-Memory OLTP no parece estar muy extendida, pero a medida que la característica madure, espero que más clientes comiencen a preguntar sobre la implementación. Al igual que con cualquier cambio importante de esquema o código, recomiendo realizar pruebas exhaustivas para determinar si OLTP en memoria brindará los beneficios esperados. Con eso en mente, estaba interesado en ver cómo cambiaba el rendimiento de las declaraciones INSERT, UPDATE y DELETE muy simples con In-Memory OLTP. Tenía la esperanza de que si podía demostrar que el bloqueo o bloqueo es un problema con las tablas basadas en disco, entonces las tablas en memoria proporcionarían una solución, ya que no tienen bloqueos ni bloqueos.
Desarrollé la siguiente prueba casos:
- Una tabla basada en disco con procedimientos almacenados tradicionales para DML.
- Una tabla en memoria con procedimientos almacenados tradicionales para DML.
- Una tabla en memoria con procedimientos compilados de forma nativa para DML.
Estaba interesado en comparar el rendimiento de los procedimientos almacenados tradicionales y los procedimientos compilados de forma nativa, porque una restricción de un procedimiento compilado de forma nativa es que cualquier tabla a la que se haga referencia debe estar en memoria. Si bien las modificaciones solitarias de una sola fila pueden ser comunes en algunos sistemas, a menudo veo modificaciones que ocurren dentro de un procedimiento almacenado más grande con múltiples declaraciones (SELECT y DML) que acceden a una o más tablas. La documentación de In-Memory OLTP recomienda encarecidamente utilizar procedimientos compilados de forma nativa para obtener el máximo beneficio en términos de rendimiento. Quería saber cuánto mejoraba el rendimiento.
La configuración
Creé una base de datos con un grupo de archivos optimizado para memoria y luego creé tres tablas diferentes en la base de datos (una basada en disco, dos en memoria):
- Tabla de discos
- InMemory_Temp1
- InMemory_Temp2
El DDL era casi el mismo para todos los objetos, teniendo en cuenta el disco frente a la memoria cuando correspondía. DDL de DiskTable frente a DDL en memoria:
CREATE TABLE [dbo].[DiskTable] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) ON [DiskTables]; GO CREATE TABLE [dbo].[InMemTable_Temp1] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000), [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) WITH (MEMORY_OPTIMIZED=ON, DURABILITY = SCHEMA_AND_DATA); GO
También creé nueve procedimientos almacenados, uno para cada combinación de tabla/modificación.
- Insertar tabla_disco
- Actualización de tabla_disco
- DiskTable_Delete
- InMemRegularSP_Insert
- InMemRegularSP_Actualización
- InMemRegularSP _Eliminar
- InMemCompiledSP_Insert
- InMemCompiledSP_Actualización
- InMemCompiledSP_Delete
Cada procedimiento almacenado aceptaba una entrada de número entero para realizar un bucle para ese número de modificaciones. Los procedimientos almacenados siguieron el mismo formato, las variaciones fueron solo la tabla a la que se accedió y si el objeto se compiló de forma nativa o no. El código completo para crear la base de datos y los objetos se puede encontrar aquí, con instrucciones de ejemplo INSERTAR y ACTUALIZAR a continuación:
CREATE PROCEDURE dbo.[DiskTable_Inserts] @NumRows INT AS BEGIN SET NOCOUNT ON; DECLARE @Name INT; DECLARE @Type INT; DECLARE @ColInt INT; DECLARE @ColVarchar VARCHAR(255) DECLARE @RowLoop INT = 1; WHILE (@RowLoop <= @NumRows) BEGIN SET @Name = CONVERT (INT, RAND () * 1000) + 1; SET @Type = CONVERT (INT, RAND () * 100) + 1; SET @ColInt = CONVERT (INT, RAND () * 850) + 1 SET @ColVarchar = CONVERT (INT, RAND () * 1300) + 1 INSERT INTO [dbo].[DiskTable] ( [Name], [Type], [c4], [c5], [c6], [c7], [c8], [c9], [c10], [c11] ) VALUES (@Name, @Type, @ColInt, @ColInt + (CONVERT (INT, RAND () * 20) + 1), @ColInt + (CONVERT (INT, RAND () * 30) + 1), @ColInt + (CONVERT (INT, RAND () * 40) + 1), @ColVarchar, @ColVarchar + (CONVERT (INT, RAND () * 20) + 1), @ColVarchar + (CONVERT (INT, RAND () * 30) + 1), @ColVarchar + (CONVERT (INT, RAND () * 40) + 1)) SELECT @RowLoop = @RowLoop + 1 END END GO CREATE PROCEDURE [InMemUpdates_CompiledSP] @NumRows INT WITH NATIVE_COMPILATION, SCHEMABINDING AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english') DECLARE @RowLoop INT = 1; DECLARE @ID INT DECLARE @RowNum INT = @@SPID * (CONVERT (INT, RAND () * 1000) + 1) WHILE (@RowLoop <= @NumRows) BEGIN SELECT @ID = ID FROM [dbo].[IDs_InMemTable2] WHERE RowNum = @RowNum UPDATE [dbo].[InMemTable_Temp2] SET [c4] = [c5] * 2 WHERE [ID] = @ID SET @RowLoop = @RowLoop + 1 SET @RowNum = @RowNum + (CONVERT (INT, RAND () * 10) + 1) END END GO
Nota:Las tablas IDs_* se volvieron a llenar después de completar cada conjunto de INSERT y eran específicas para los tres escenarios diferentes.
Metodología de prueba
Las pruebas se realizaron utilizando secuencias de comandos .cmd que usaban sqlcmd para llamar a una secuencia de comandos que ejecutaba el procedimiento almacenado, por ejemplo:
sqlcmd -S CAP\ROGERS -i"C:\Temp\SentryOne\InMemTable_RegularDeleteSP_100.sql"salir
Usé este enfoque para crear una o más conexiones a la base de datos que se ejecutarían simultáneamente. Además de comprender los cambios básicos en el rendimiento, también quería examinar el efecto de diferentes cargas de trabajo. Estos scripts se iniciaron desde una máquina separada para eliminar la sobrecarga de crear instancias de conexiones. Cada procedimiento almacenado fue ejecutado 1000 veces por una conexión, y probé 1 conexión, 10 conexiones y 100 conexiones (1000, 10000 y 100000 modificaciones, respectivamente). Capturé las métricas de rendimiento mediante Query Store y también capturé las estadísticas de espera. Con Query Store pude capturar la duración promedio y la CPU para cada procedimiento almacenado. Los datos de estadísticas de espera se capturaron para cada conexión mediante dm_exec_session_wait_stats y luego se agregaron para toda la prueba.
Realicé cada prueba cuatro veces y luego calculé los promedios generales de los datos utilizados en esta publicación. Los scripts utilizados para las pruebas de carga de trabajo se pueden descargar desde aquí.
Resultados
Como era de esperar, el rendimiento con objetos en memoria fue mejor que con objetos basados en disco. Sin embargo, una tabla en memoria con un procedimiento almacenado regular a veces tenía un rendimiento comparable o solo ligeramente mejor en comparación con una tabla basada en disco con un procedimiento almacenado regular. Recuerde:estaba interesado en comprender si realmente necesitaba un procedimiento almacenado compilado para obtener un gran beneficio con una tabla en memoria. Para este escenario, lo hice. En todos los casos, la tabla en memoria con el procedimiento compilado de forma nativa tuvo un rendimiento significativamente mejor. Los dos gráficos a continuación muestran los mismos datos, pero con diferentes escalas para el eje x, para demostrar ese rendimiento para los procedimientos almacenados regulares que modifican los datos degradados con más conexiones simultáneas.
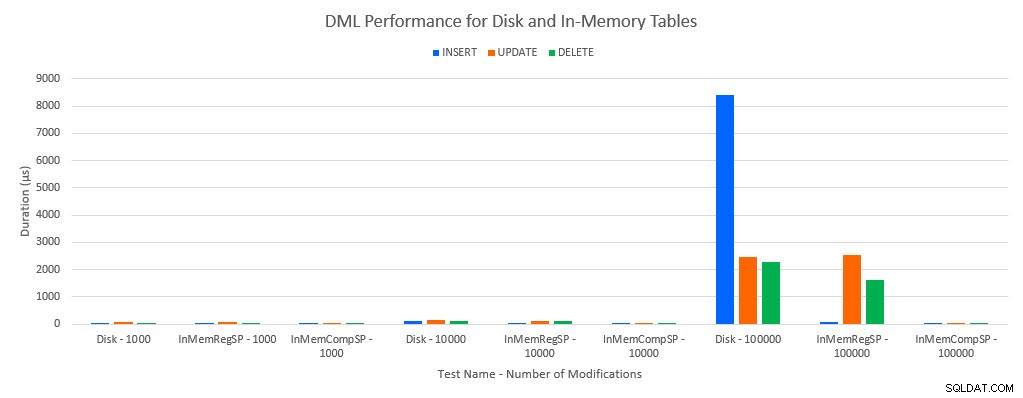
Rendimiento DML por prueba y carga de trabajo
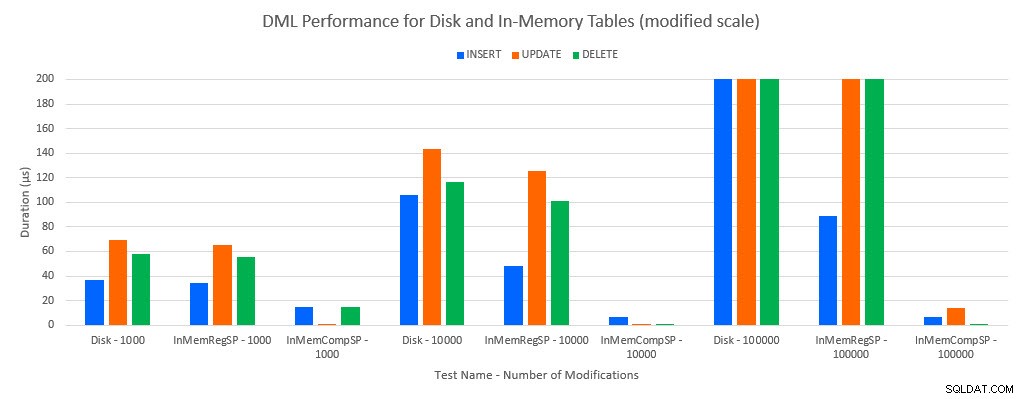
Rendimiento DML por prueba y carga de trabajo [escala modificada]
La excepción son los INSERT en la tabla In-Memory con el procedimiento almacenado regular. Con 100 conexiones, la duración promedio es superior a 8 ms para una tabla basada en disco, pero inferior a 100 microsegundos para la tabla en memoria. La razón probable es la ausencia de bloqueo y bloqueo con la tabla en memoria, y esto es compatible con los datos de estadísticas de espera:
| Prueba | INSERTAR | ACTUALIZAR | ELIMINAR |
|---|---|---|---|
| Tabla de discos:1000 | REGISTRO DE ESCRITURA | REGISTRO DE ESCRITURA | REGISTRO DE ESCRITURA |
| InMemTable_RegularSP:1000 | REGISTRO DE ESCRITURA | REGISTRO DE ESCRITURA | REGISTRO DE ESCRITURA |
| InMemTable_CompiledSP:1000 | REGISTRO DE ESCRITURA | MEMORY_ALLOCATION_EXT | MEMORY_ALLOCATION_EXT |
| Tabla de discos:10 000 | REGISTRO DE ESCRITURA | REGISTRO DE ESCRITURA | REGISTRO DE ESCRITURA |
| InMemTable_RegularSP:10 000 | REGISTRO DE ESCRITURA | REGISTRO DE ESCRITURA | REGISTRO DE ESCRITURA |
| InMemTable_CompiledSP:10 000 | REGISTRO DE ESCRITURA | REGISTRO DE ESCRITURA | MEMORY_ALLOCATION_EXT |
| Tabla de discos:100 000 | PAGELATCH_EX | REGISTRO DE ESCRITURA | REGISTRO DE ESCRITURA |
| InMemTable_RegularSP:100 000 | REGISTRO DE ESCRITURA | REGISTRO DE ESCRITURA | REGISTRO DE ESCRITURA |
| InMemTable_CompiledSP:100 000 | REGISTRO DE ESCRITURA | REGISTRO DE ESCRITURA | REGISTRO DE ESCRITURA |
Estadísticas de espera por prueba
Los datos de estadísticas de espera se enumeran aquí en función del tiempo total de espera de recursos (que generalmente también se traducía en el tiempo de recursos promedio más alto, pero había excepciones). El tipo de espera WRITELOG es el factor limitante en este sistema la mayor parte del tiempo. Sin embargo, PAGELATCH_EX espera 100 conexiones simultáneas que ejecutan instrucciones INSERT, lo que sugiere que, con una carga adicional, el comportamiento de bloqueo y bloqueo que existe con las tablas basadas en disco podría ser un factor limitante. En los escenarios de ACTUALIZACIÓN y ELIMINACIÓN con 10 y 100 conexiones para las pruebas de tablas basadas en disco, el Tiempo promedio de espera de recursos fue más alto para los bloqueos (LCK_M_X).
Conclusión
In-Memory OLTP puede proporcionar absolutamente un impulso de rendimiento para la carga de trabajo adecuada. Los ejemplos probados aquí, sin embargo, son extremadamente simples y no deben ser juzgados como una sola razón para migrar a una solución In-Memory. Todavía existen múltiples limitaciones que deben tenerse en cuenta, y se deben realizar pruebas exhaustivas antes de que se produzca una migración (particularmente porque migrar a una tabla en memoria es un proceso fuera de línea). Pero para el escenario correcto, esta nueva característica puede proporcionar un aumento de rendimiento. Siempre que comprenda que seguirán existiendo algunas limitaciones subyacentes, como la velocidad del registro de transacciones para las tablas duraderas, aunque probablemente de forma reducida, independientemente de si la tabla existe en el disco o en la memoria.



