En marzo, comencé una serie sobre los mitos generalizados sobre el rendimiento en SQL Server. Una creencia que encuentro de vez en cuando es que puede sobredimensionar columnas varchar o nvarchar sin ninguna penalización.
Supongamos que está almacenando direcciones de correo electrónico. En una vida anterior, lidié bastante con esto:en ese momento, RFC 3696 establecía que una dirección de correo electrónico podía tener 320 caracteres (64 caracteres @ 255 caracteres). Un RFC más nuevo, #5321, ahora reconoce que 254 caracteres es el máximo que puede tener una dirección de correo electrónico. Y si alguno de ustedes tiene una dirección tan larga, quizás deberíamos charlar. :-)
Ahora, ya sea que siga el estándar antiguo o el nuevo, debe admitir la posibilidad de que alguien use todos los caracteres permitidos. Lo que significa que tienes que usar 254 o 320 caracteres. Pero lo que he visto hacer a la gente es no molestarse en investigar el estándar en absoluto, y simplemente suponer que necesitan admitir 1000 caracteres, 4000 caracteres o incluso más.
Entonces, echemos un vistazo a lo que sucede cuando tenemos tablas con una columna de dirección de correo electrónico de tamaño variable, pero que almacenan exactamente los mismos datos:
CREATE TABLE dbo.Email_V320 ( id int IDENTITY PRIMARY KEY, email varchar(320) ); CREATE TABLE dbo.Email_V1000 ( id int IDENTITY PRIMARY KEY, email varchar(1000) ); CREATE TABLE dbo.Email_V4000 ( id int IDENTITY PRIMARY KEY, email varchar(4000) ); CREATE TABLE dbo.Email_Vmax ( id int IDENTITY PRIMARY KEY, email varchar(max) );
Ahora, generemos 10 000 direcciones de correo electrónico ficticias a partir de los metadatos del sistema y completemos las cuatro tablas con los mismos datos:
INSERT dbo.Email_V320(email) SELECT TOP (10000) REPLACE(LEFT(LEFT(c.name, 64) + '@' + LEFT(o.name, 128) + '.com', 254), ' ', '') FROM sys.all_columns AS c INNER JOIN sys.all_objects AS o ON c.[object_id] = o.[object_id] INNER JOIN sys.all_columns AS c2 ON c.[object_id] = c2.[object_id] ORDER BY NEWID(); INSERT dbo.Email_V1000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_V4000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_Vmax (email) SELECT email FROM dbo.Email_V320; -- let's rebuild ALTER INDEX ALL ON dbo.Email_V320 REBUILD; ALTER INDEX ALL ON dbo.Email_V1000 REBUILD; ALTER INDEX ALL ON dbo.Email_V4000 REBUILD; ALTER INDEX ALL ON dbo.Email_Vmax REBUILD;
Para validar que cada tabla contiene exactamente los mismos datos:
SELECT AVG(LEN(email)), MAX(LEN(email)) FROM dbo.Email_<size>;
Los cuatro dan 35 y 77 para mí; Su experiencia puede ser diferente. También asegurémonos de que las cuatro tablas ocupen la misma cantidad de páginas en el disco:
SELECT o.name, COUNT(p.[object_id])
FROM sys.objects AS o
CROSS APPLY sys.dm_db_database_page_allocations
(DB_ID(), o.object_id, 1, NULL, 'LIMITED') AS p
WHERE o.name LIKE N'Email[_]V[^2]%'
GROUP BY o.name; Las cuatro consultas arrojan 89 páginas (nuevamente, su kilometraje puede variar).
Ahora, tomemos una consulta típica que da como resultado un escaneo de índice agrupado:
SELECT id, email FROM dbo.Email_<size>;
Si observamos cosas como la duración, las lecturas y los costos estimados, todos parecen iguales:
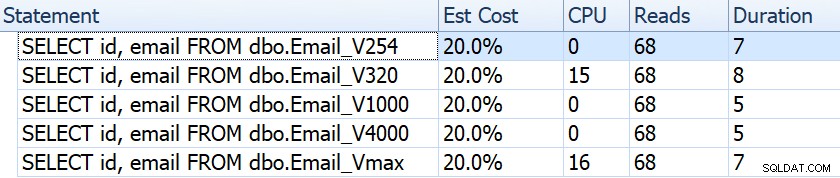
Esto puede llevar a las personas a la suposición falsa de que no hay ningún impacto en el rendimiento. Pero si miramos un poco más de cerca, en la información sobre herramientas para el análisis de índice agrupado en cada plan, vemos una diferencia que puede entrar en juego en otras consultas más elaboradas:

Desde aquí vemos que, cuanto mayor sea la definición de la columna, mayor será la fila estimada y el tamaño de los datos. En esta consulta simple, el costo de E/S (0.0512731) es el mismo en todas las consultas, independientemente de la definición, porque el escaneo del índice agrupado tiene que leer todos los datos de todos modos.
Pero hay otros escenarios en los que esta fila estimada y el tamaño total de los datos tendrán un impacto:operaciones que requieren recursos adicionales, como las clasificaciones. Tomemos esta consulta ridícula que no tiene ningún propósito real, aparte de requerir varias operaciones de clasificación:
SELECT /* V<size> */ ROW_NUMBER() OVER (PARTITION BY email ORDER BY email DESC),
email, REVERSE(email), SUBSTRING(email, 1, CHARINDEX('@', email))
FROM dbo.Email_V<size>
GROUP BY REVERSE(email), email, SUBSTRING(email, 1, CHARINDEX('@', email))
ORDER BY REVERSE(email), email; Ejecutamos estas cuatro consultas y vemos que todos los planes se ven así:

Sin embargo, ese ícono de advertencia en el operador SELECT solo aparece en las tablas 4000/max. ¿Cuál es la advertencia? Es una advertencia de concesión de memoria excesiva, introducida en SQL Server 2016. Esta es la advertencia para varchar(4000):

Y para varchar(máx):

Miremos un poco más de cerca y veamos qué está pasando, al menos según sys.dm_exec_query_stats:
SELECT [table] = SUBSTRING(t.[text], 1, CHARINDEX(N'*/', t.[text])), s.last_elapsed_time, s.last_grant_kb, s.max_ideal_grant_kb FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.[text] LIKE N'%/*%dbo.'+N'Email_V%' ORDER BY s.last_grant_kb;
Resultados:

En mi escenario, la duración no se vio afectada por las diferencias de concesión de memoria (excepto en el caso máximo), pero se puede ver claramente la progresión lineal que coincide con el tamaño declarado de la columna. Que puede usar para extrapolar lo que sucedería en un sistema con memoria insuficiente. O una consulta más elaborada contra un conjunto de datos mucho más grande. O concurrencia significativa. Cualquiera de esos escenarios podría requerir derrames para procesar las operaciones de clasificación y, como resultado, es casi seguro que la duración se vería afectada.
Pero, ¿de dónde vienen estas concesiones de memoria más grandes? Recuerde, es la misma consulta, con exactamente los mismos datos. El problema es que, para ciertas operaciones, SQL Server tiene que tener en cuenta la cantidad de datos *podría* haber en una columna. No hace esto basándose en el perfilado real de los datos, y no puede hacer ninguna suposición basada en los valores de paso de histograma <=201. En su lugar, tiene que estimar que cada fila contiene un valor de la mitad del tamaño de columna declarado . Entonces, para un varchar (4000), asume que cada dirección de correo electrónico tiene 2,000 caracteres.
Cuando no es posible tener una dirección de correo electrónico de más de 254 o 320 caracteres, no hay nada que ganar con el tamaño excesivo y hay mucho que perder potencialmente. Aumentar el tamaño de una columna de ancho variable más adelante es mucho más fácil que lidiar con todas las desventajas ahora.
Por supuesto, sobredimensionar char o nchar las columnas pueden tener penalizaciones mucho más obvias.