Autor invitado:Michael J Swart (@MJSwart)
Dedico una gran cantidad de tiempo a traducir los requisitos de software en esquemas y consultas. Estos requisitos a veces son fáciles de implementar, pero a menudo son difíciles. Quiero hablar sobre las opciones de diseño de la interfaz de usuario que conducen a patrones de acceso a datos que son difíciles de implementar con SQL Server.
Ordenar por columna
Ordenar por columna es un patrón tan familiar que podemos darlo por sentado. Cada vez que interactuamos con un software que muestra una tabla, podemos esperar que las columnas se puedan ordenar de esta manera:
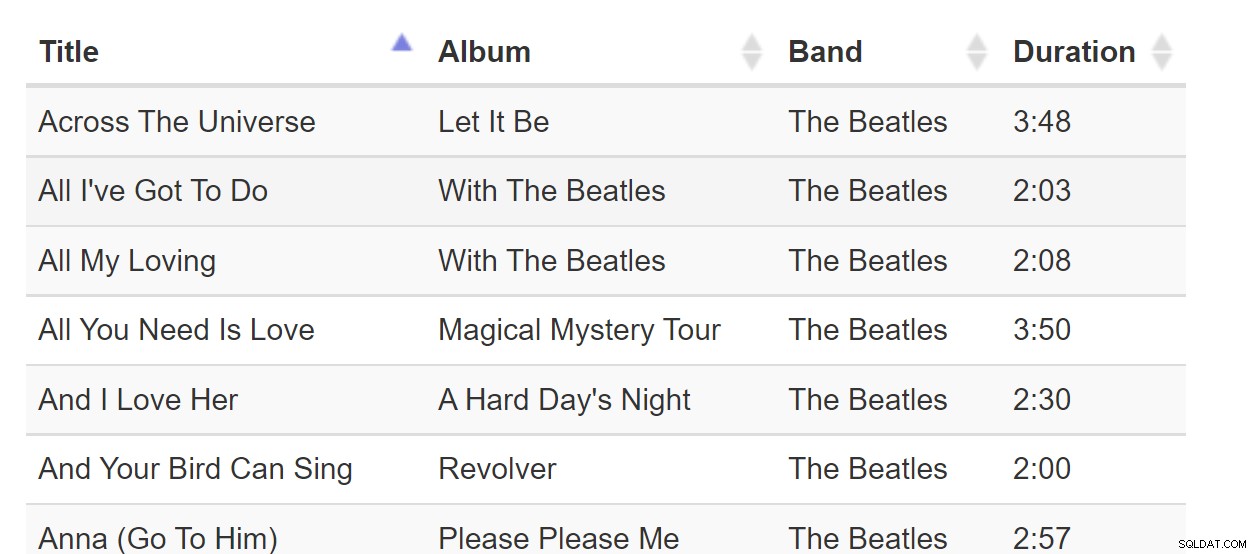
Sort-By-Colunn es un gran patrón cuando todos los datos caben en el navegador. Pero si el conjunto de datos tiene miles de millones de filas, esto puede volverse incómodo incluso si la página web solo requiere una página de datos. Considere esta tabla de canciones:
CREATE TABLE Songs
(
Title NVARCHAR(300) NOT NULL,
Album NVARCHAR(300) NOT NULL,
Band NVARCHAR(300) NOT NULL,
DurationInSeconds INT NOT NULL,
CONSTRAINT PK_Songs PRIMARY KEY CLUSTERED (Title),
);
CREATE NONCLUSTERED INDEX IX_Songs_Album
ON dbo.Songs(Album)
INCLUDE (Band, DurationInSeconds);
CREATE NONCLUSTERED INDEX IX_Songs_Band
ON dbo.Songs(Band); Y considere estas cuatro consultas ordenadas por cada columna:
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Title; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Album; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Band; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY DurationInSeconds;
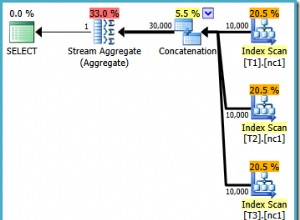
Incluso para una consulta tan simple, existen diferentes planes de consulta. Las dos primeras consultas utilizan índices de cobertura:
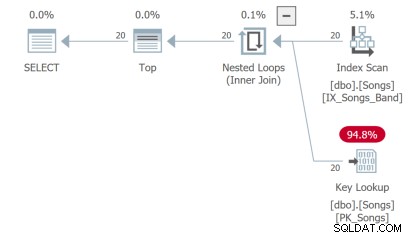
La tercera consulta necesita hacer una búsqueda clave que no es ideal:
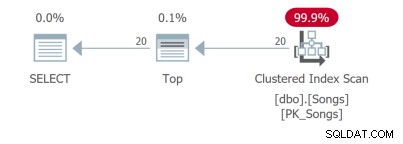
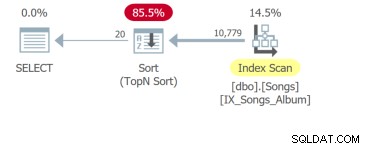
Pero lo peor es la cuarta consulta que necesita escanear toda la tabla y ordenar para devolver las primeras 20 filas:
El punto es que aunque la única diferencia es la cláusula ORDER BY, esas consultas deben analizarse por separado. La unidad básica de ajuste de SQL es la consulta. Entonces, si me muestra los requisitos de la interfaz de usuario con diez columnas ordenables, le mostraré diez consultas para analizar.
¿Cuándo se vuelve esto incómodo?
La función Ordenar por columna es un excelente patrón de interfaz de usuario, pero puede volverse incómodo si los datos provienen de una gran tabla en crecimiento con muchas, muchas columnas. Puede ser tentador crear índices de cobertura en cada columna, pero eso tiene otras ventajas y desventajas. Los índices de almacén de columnas pueden ayudar en algunas circunstancias, pero eso introduce otro nivel de incomodidad. No siempre hay una alternativa fácil.
Resultados paginados
El uso de resultados paginados es una buena manera de no abrumar al usuario con demasiada información a la vez. También es una buena manera de no abrumar a los servidores de bases de datos... por lo general.
Considere este diseño:

Los datos detrás de este ejemplo requieren contar y procesar todo el conjunto de datos para informar la cantidad de resultados. La consulta de este ejemplo podría usar una sintaxis como esta:
... ORDER BY LastModifiedTime OFFSET @N ROWS FETCH NEXT 25 ROWS ONLY;
Es una sintaxis conveniente y la consulta solo produce 25 filas. Pero el hecho de que el conjunto de resultados sea pequeño no significa necesariamente que sea barato. Tal como vimos con el patrón Ordenar por columna, un operador TOP solo es económico si no necesita ordenar una gran cantidad de datos primero.
Solicitudes de página asíncronas
A medida que un usuario navega de una página de resultados a la siguiente, las solicitudes web involucradas pueden estar separadas por segundos o minutos. Esto lleva a problemas que se parecen mucho a las trampas que se ven cuando se usa NOLOCK. Por ejemplo:
SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY; -- wait a little bit SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 25 ROWS FETCH NEXT 25 ROWS ONLY;
Cuando se agrega una fila entre las dos solicitudes, el usuario puede ver la misma fila dos veces. Y si se elimina una fila, el usuario puede perder una fila mientras navega por las páginas. Este patrón de resultados paginados es equivalente a "Dame filas 26-50". Cuando la verdadera pregunta debería ser "Dame las próximas 25 filas". La diferencia es sutil.
Mejores patrones
Con Paged-Results, ese "OFFSET @N ROWS" puede tomar más y más tiempo a medida que crece @N. En su lugar, considere los botones Load-More o Infinite-Scrolling. Con la paginación Load-More, existe al menos la posibilidad de hacer un uso eficiente de un índice. La consulta sería algo como:
SELECT [Some Columns] FROM [Some Table] WHERE [Sort Value] > @Bookmark ORDER BY [Sort Value] FETCH NEXT 25 ROWS ONLY;
Todavía sufre algunos de los inconvenientes de las solicitudes de página asincrónicas, pero debido al marcador, el usuario continuará donde lo dejó.
Buscar texto para subcadena
La búsqueda está en todas partes en Internet. Pero, ¿qué solución se debe usar en el back-end? Quiero advertir contra la búsqueda de una subcadena usando el filtro LIKE de SQL Server con comodines como este:
SELECT Title, Category FROM MyContent WHERE Title LIKE '%' + @SearchTerm + '%';
Puede conducir a resultados incómodos como este:
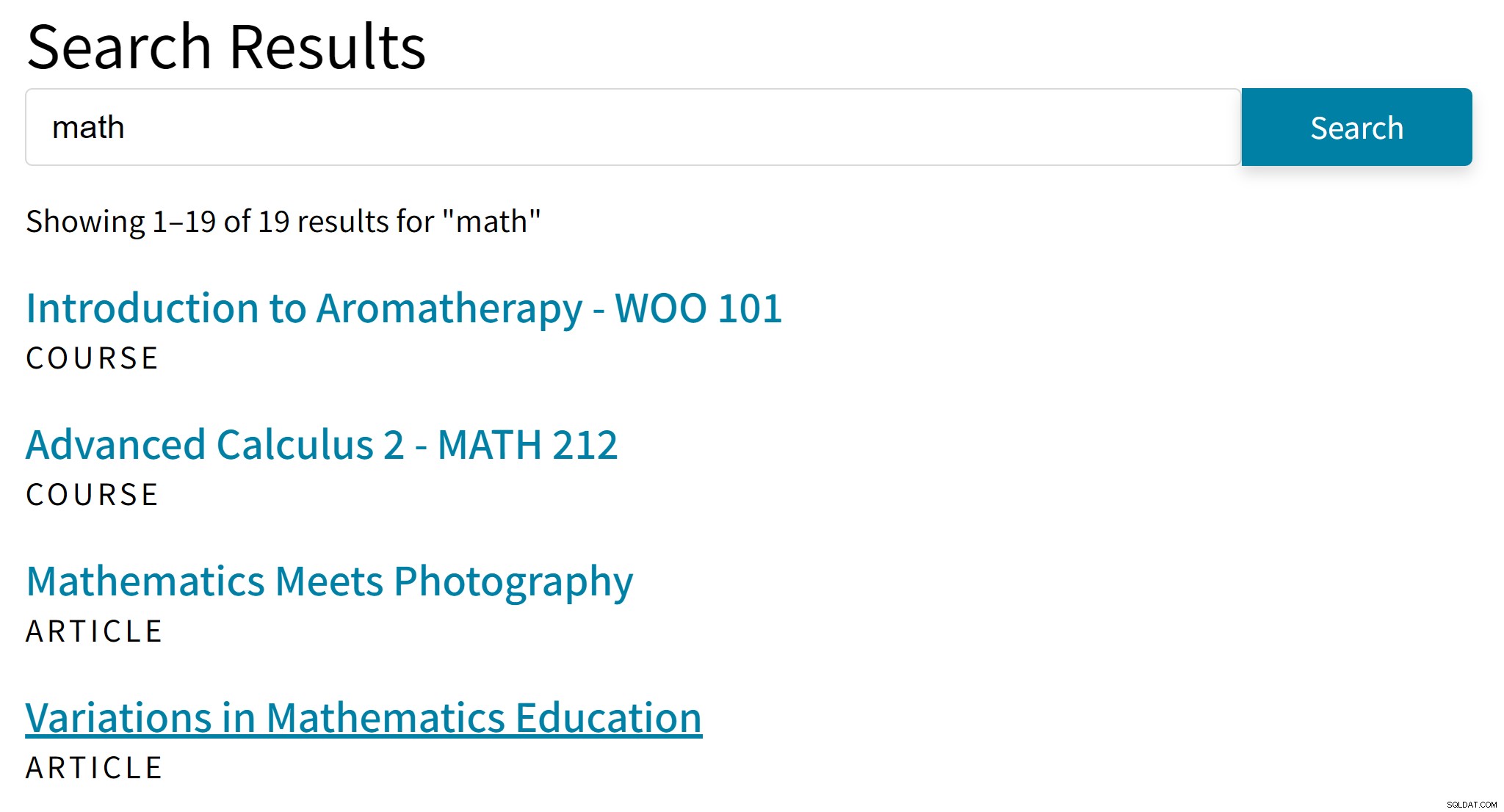
"Aromaterapia" probablemente no sea un buen resultado para el término de búsqueda "matemáticas". Mientras tanto, en los resultados de búsqueda faltan artículos que solo mencionan álgebra o trigonometría.
También puede ser muy difícil lograrlo de manera eficiente con SQL Server. No existe un índice sencillo que admita este tipo de búsqueda. Paul White dio una solución complicada con Trigram Wildcard String Search en SQL Server. También hay dificultades que pueden ocurrir con intercalaciones y Unicode. Puede convertirse en una solución costosa para una experiencia de usuario no tan buena.
Qué usar en su lugar
La búsqueda de texto completo de SQL Server parece que podría ayudar, pero personalmente nunca la he usado. En la práctica, solo he visto el éxito en soluciones fuera de SQL Server (por ejemplo, Elasticsearch).
Conclusión
En mi experiencia, descubrí que los diseñadores de software a menudo son muy receptivos a los comentarios de que sus diseños a veces serán difíciles de implementar. Cuando no lo son, he encontrado útil resaltar las trampas, los costos y el tiempo de entrega. Ese tipo de comentarios es necesario para ayudar a crear soluciones escalables y sostenibles.
Sobre el autor
 Michael J Swart es un bloguero y profesional de bases de datos apasionado que se centra en el desarrollo de bases de datos y la arquitectura de software. Le gusta hablar sobre cualquier tema relacionado con los datos, contribuyendo a proyectos comunitarios. Michael escribe en un blog como "Database Whisperer" en michaeljswart.com.
Michael J Swart es un bloguero y profesional de bases de datos apasionado que se centra en el desarrollo de bases de datos y la arquitectura de software. Le gusta hablar sobre cualquier tema relacionado con los datos, contribuyendo a proyectos comunitarios. Michael escribe en un blog como "Database Whisperer" en michaeljswart.com.