En mi artículo anterior comencé una nueva serie sobre cerrojos explicando qué son, por qué se necesitan y la mecánica de cómo funcionan, y le recomiendo que lea ese artículo antes que este. En este artículo, hablaré sobre el pestillo FGCB_ADD_REMOVE y mostraré cómo puede ser un cuello de botella.
¿Qué es el pestillo FGCB_ADD_REMOVE?
La mayoría de los nombres de clases de pestillo están vinculados directamente a la estructura de datos que protegen. El pestillo FGCB_ADD_REMOVE protege una estructura de datos llamada FGCB, o bloque de control de grupo de archivos, y habrá uno de estos pestillos para cada grupo de archivos en línea de cada base de datos en línea en una instancia de SQL Server. Siempre que se agregue, elimine, aumente o reduzca un archivo en un grupo de archivos, el pestillo debe adquirirse en modo EX y, al calcular el siguiente archivo desde el que asignar, el pestillo debe adquirirse en modo SH para evitar cualquier cambio en el grupo de archivos. (Recuerde que las asignaciones de extensiones para un grupo de archivos se realizan por turnos a través de los archivos del grupo de archivos y también tienen en cuenta el relleno proporcional , que explico aquí.)
¿Cómo se convierte el pestillo en un cuello de botella?
El escenario más común cuando este pestillo se convierte en un cuello de botella es el siguiente:
- Hay una base de datos de un solo archivo, por lo que todas las asignaciones deben provenir de ese único archivo de datos
- La configuración de crecimiento automático para el archivo es muy pequeña (recuerde, antes de SQL Server 2016, la configuración de crecimiento automático predeterminada para los archivos de datos era de 1 MB).
- Hay muchas operaciones simultáneas que requieren la asignación de espacio (por ejemplo, una carga de trabajo de inserción constante de muchas conexiones de clientes)
En este caso, a pesar de que solo hay un archivo, un subproceso que requiere una asignación todavía tiene que adquirir el latch FGCB_ADD_REMOVE en modo SH. Luego intentará asignar desde el archivo de datos único, se dará cuenta de que no hay espacio y luego adquirirá el pestillo en modo EX para que luego pueda hacer crecer el archivo.
Imaginemos que ocho subprocesos que se ejecutan en ocho programadores independientes intentan asignarse al mismo tiempo y todos se dan cuenta de que no hay espacio en el archivo, por lo que necesitan aumentarlo. Cada uno de ellos intentará adquirir el pestillo en modo EX. Solo uno de ellos podrá adquirirlo y procederá a hacer crecer el archivo y los demás tendrán que esperar, con un tipo de espera LATCH_EX y una descripción del recurso FGCB_ADD_REMOVE más la dirección de memoria del latch.
Los siete subprocesos en espera están en la cola de espera de primero en entrar, primero en salir (FIFO) del pestillo. Cuando el subproceso que realiza el crecimiento del archivo finaliza, libera el pestillo y se lo otorga al primer subproceso en espera. Este nuevo dueño del pestillo va a hacer crecer el archivo y descubre que ya ha sido crecido y no hay nada que hacer. Entonces libera el pestillo y lo otorga al siguiente hilo en espera. Y así sucesivamente.
Los siete subprocesos en espera esperaron el pestillo en modo EX, pero terminaron sin hacer nada una vez que se les otorgó el pestillo, por lo que los siete subprocesos esencialmente desperdiciaron el tiempo transcurrido, y la cantidad de tiempo desperdiciado aumentó un poco para cada subproceso más abajo. la cola de espera FIFO era.
Mostrando el cuello de botella
Ahora le mostraré el escenario exacto anterior, usando eventos extendidos. Creé una base de datos de un solo archivo con una pequeña configuración de crecimiento automático y cientos de conexiones simultáneas simplemente insertando datos en una tabla.
Puedo usar la siguiente sesión de evento extendida para ver qué está pasando:
-- Drop the session if it exists.
IF EXISTS
(
SELECT * FROM sys.server_event_sessions
WHERE [name] = N'FGCB_ADDREMOVE'
)
BEGIN
DROP EVENT SESSION [FGCB_ADDREMOVE] ON SERVER;
END
GO
CREATE EVENT SESSION [FGCB_ADDREMOVE] ON SERVER
ADD EVENT [sqlserver].[database_file_size_change]
(WHERE [file_type] = 0), -- data files only
ADD EVENT [sqlserver].[latch_suspend_begin]
(WHERE [class] = 48 AND [mode] = 4), -- EX mode
ADD EVENT [sqlserver].[latch_suspend_end]
(WHERE [class] = 48 AND [mode] = 4) -- EX mode
ADD TARGET [package0].[ring_buffer]
WITH (TRACK_CAUSALITY = ON);
GO
-- Start the event session
ALTER EVENT SESSION [FGCB_ADDREMOVE]
ON SERVER STATE = START;
GO La sesión realiza un seguimiento de cuándo un subproceso ingresa a la cola de espera del latch, cuándo sale de la cola (es decir, cuándo se le otorga el latch) y cuándo se produce un crecimiento del archivo de datos. El uso del seguimiento de causalidad significa que podemos ver una línea de tiempo de las acciones de cada hilo.
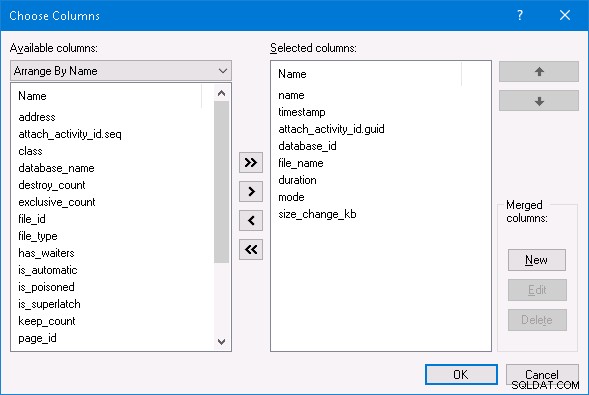
Con SQL Server Management Studio, puedo seleccionar la opción Ver datos en vivo para la sesión de eventos extendida y ver toda la actividad de eventos extendidos. Si desea hacer lo mismo, en la ventana Datos en vivo, haga clic con el botón derecho en uno de los nombres de columna en la parte superior y cambie las columnas seleccionadas para que queden como se muestra a continuación:
Dejé que la carga de trabajo se ejecutara durante unos minutos para alcanzar un estado estable y luego vi un ejemplo perfecto del escenario que describí anteriormente:
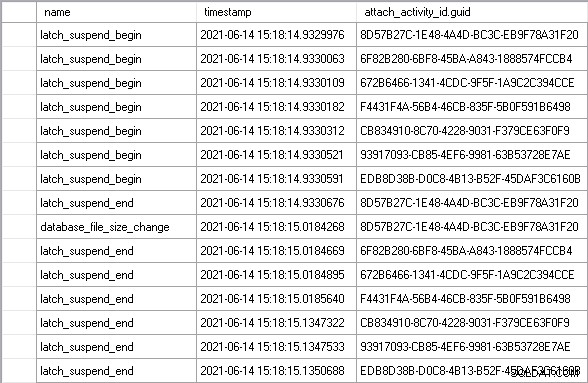
Uso de attach_activity_id.guid valores para identificar diferentes subprocesos, podemos ver que siete subprocesos comienzan a esperar el pestillo dentro de los 61,5 microsegundos. El subproceso con el valor GUID que comienza en 8D57 adquiere el latch en modo EX (el latch_suspend_end evento) y luego crece inmediatamente el archivo (el database_file_size_change evento). El subproceso 8D57 luego libera el pestillo y lo otorga en modo EX al subproceso 6F82, que esperó 85 milisegundos. No tiene nada que hacer, por lo que otorga el pestillo al hilo 672B. Y así sucesivamente, hasta que se conceda el latch al subproceso EDB8, después de esperar 202 milisegundos.
En total, los seis subprocesos que esperaron sin motivo esperaron casi 1 segundo. Parte de ese tiempo es el tiempo de espera de la señal, en el que, aunque al subproceso se le haya otorgado el pestillo, aún debe moverse hasta la parte superior de la cola ejecutable del programador antes de que pueda ingresar al procesador y ejecutar el código. Se podría decir que esta no es una medida justa del tiempo que se pasa esperando el pestillo, pero lo es absolutamente, porque no se habría incurrido en el tiempo de espera de la señal si el subproceso no hubiera tenido que esperar en primer lugar.
Además, puede pensar que un retraso de 200 milisegundos no es mucho, pero todo depende de los acuerdos de nivel de servicio de rendimiento para la carga de trabajo en cuestión. Tenemos varios clientes de alto volumen en los que si un lote tarda más de 200 milisegundos en ejecutarse, ¡no está permitido en el sistema de producción!
Resumen
Si está monitoreando las esperas en su servidor y nota que LATCH_EX es una de las principales esperas, puede usar el código en esta publicación para ver si FGCB_ADD_REMOVE es uno de los culpables.
La manera más fácil de asegurarse de que su carga de trabajo no se encuentre con un cuello de botella FGCB_ADD_REMOVE es asegurarse de que no haya configuraciones de crecimiento automático de archivos de datos configuradas con los valores predeterminados anteriores a SQL Server 2016. En los sys.master_files vista, el valor predeterminado de 1 MB se mostraría como un archivo de datos (type_desc columna establecida en FILAS) con el is_percent_growth columna establecida en 0 y la columna de crecimiento establecida en 128.
Dar una recomendación sobre cómo se debe configurar el crecimiento automático es otra discusión, pero ahora conoce un posible impacto en el rendimiento al no cambiar los valores predeterminados en versiones anteriores.