El mes pasado, cubrí el rompecabezas de Peter Larsson de hacer coincidir la oferta con la demanda. Mostré la solución sencilla basada en el cursor de Peter y le expliqué que tiene una escala lineal. El desafío que les dejé es tratar de llegar a una solución basada en conjuntos para la tarea, y vaya, ¡que la gente esté a la altura del desafío! Gracias Luca, Kamil Kosno, Daniel Brown, Brian Walker, Joe Obbish, Rainer Hoffmann, Paul White, Charlie y, por supuesto, Peter Larsson, por enviar sus soluciones. Algunas de las ideas eran brillantes y alucinantes.
Este mes, voy a comenzar a explorar las soluciones enviadas, aproximadamente, pasando de las de peor rendimiento a las de mejor rendimiento. ¿Por qué molestarse con los que tienen un mal desempeño? Porque todavía puedes aprender mucho de ellos; por ejemplo, identificando antipatrones. De hecho, el primer intento de resolver este desafío para muchas personas, incluidos Peter y yo, se basa en un concepto de intersección de intervalos. Sucede que la técnica clásica basada en predicados para identificar la intersección de intervalos tiene un rendimiento deficiente ya que no existe un buen esquema de indexación que la admita. Este artículo está dedicado a este enfoque de bajo rendimiento. A pesar del bajo rendimiento, trabajar en la solución es un ejercicio interesante. Requiere practicar la habilidad de modelar el problema de una manera que se preste a un tratamiento basado en conjuntos. También es interesante identificar el motivo del mal desempeño, facilitando así evitar el antipatrón en el futuro. Tenga en cuenta que esta solución es solo el punto de partida.
DDL y un pequeño conjunto de datos de muestra
Como recordatorio, la tarea consiste en consultar una tabla llamada "Subastas". Use el siguiente código para crear la tabla y complétela con un pequeño conjunto de datos de muestra:
BOTAR TABLA SI EXISTE dbo.Subastas; CREAR TABLA dbo.Auctions( ID INT NOT NULL IDENTITY(1, 1) RESTRICCIÓN pk_Auctions PRIMARY KEY CLUSTERED, Code CHAR(1) NOT NULL RESTRICTION ck_Auctions_Code CHECK (Código ='D' O Código ='S'), Cantidad DECIMAL(19 , 6) RESTRICCIÓN NO NULA ck_Auctions_Quantity CHECK (Cantidad> 0)); ESTABLECER SIN CUENTA EN; ELIMINAR DE dbo.Subastas; SET IDENTITY_INSERT dbo.Subastas ON; INSERTAR EN dbo.Subastas(ID, Código, Cantidad) VALORES (1, 'D', 5.0), (2, 'D', 3.0), (3, 'D', 8.0), (5, 'D', 2.0), (6, 'D', 8.0), (7, 'D', 4.0), (8, 'D', 2.0), (1000, 'S', 8.0), (2000, 'S', 6.0), (3000, 'S', 2.0), (4000, 'S', 2.0), (5000, 'S', 4.0), (6000, 'S', 3.0), (7000, 'S', 2.0); SET IDENTITY_INSERT dbo.Subastas DESACTIVADAS;
Su tarea consistía en crear emparejamientos que coincidieran con las entradas de oferta y demanda en función del pedido de ID, escribiéndolos en una tabla temporal. El siguiente es el resultado deseado para el pequeño conjunto de datos de muestra:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5.0000002 1000 3.0000003 2000 6.0000003 3000 2,0000005 4000 2,0000006 5000 4,0000006 6000 3,0000006 7000 1,0000007 7000 1,000000
El mes pasado, también proporcioné un código que puede usar para completar la tabla Subastas con un gran conjunto de datos de muestra, controlando la cantidad de entradas de oferta y demanda, así como su rango de cantidades. Asegúrese de utilizar el código del artículo del mes pasado para comprobar el rendimiento de las soluciones.
Modelando los datos como intervalos
Una idea intrigante que se presta para admitir soluciones basadas en conjuntos es modelar los datos como intervalos. En otras palabras, represente cada entrada de demanda y suministro como un intervalo que comienza con las cantidades totales acumuladas del mismo tipo (demanda o suministro) hasta pero excluyendo el actual, y terminando con el total acumulado incluyendo el actual, por supuesto basado en ID ordenando Por ejemplo, observando el pequeño conjunto de datos de muestra, la primera entrada de demanda (ID 1) es para una cantidad de 5,0 y la segunda (ID 2) es para una cantidad de 3,0. La primera entrada de demanda se puede representar con el inicio del intervalo:0.0, final:5.0, y la segunda con el inicio del intervalo:5.0, final:8.0, y así sucesivamente.
De manera similar, la primera entrada de suministro (ID 1000) es para una cantidad de 8,0 y el segundo (ID 2000) es para una cantidad de 6,0. La primera entrada de suministro se puede representar con el inicio del intervalo:0,0, final:8,0, y la segunda con el inicio del intervalo:8,0, final:14,0, y así sucesivamente.
Los pares de oferta y demanda que necesita crear son los segmentos superpuestos de los intervalos de intersección entre los dos tipos.
Esto probablemente se entienda mejor con una representación visual del modelado basado en intervalos de los datos y el resultado deseado, como se muestra en la Figura 1.
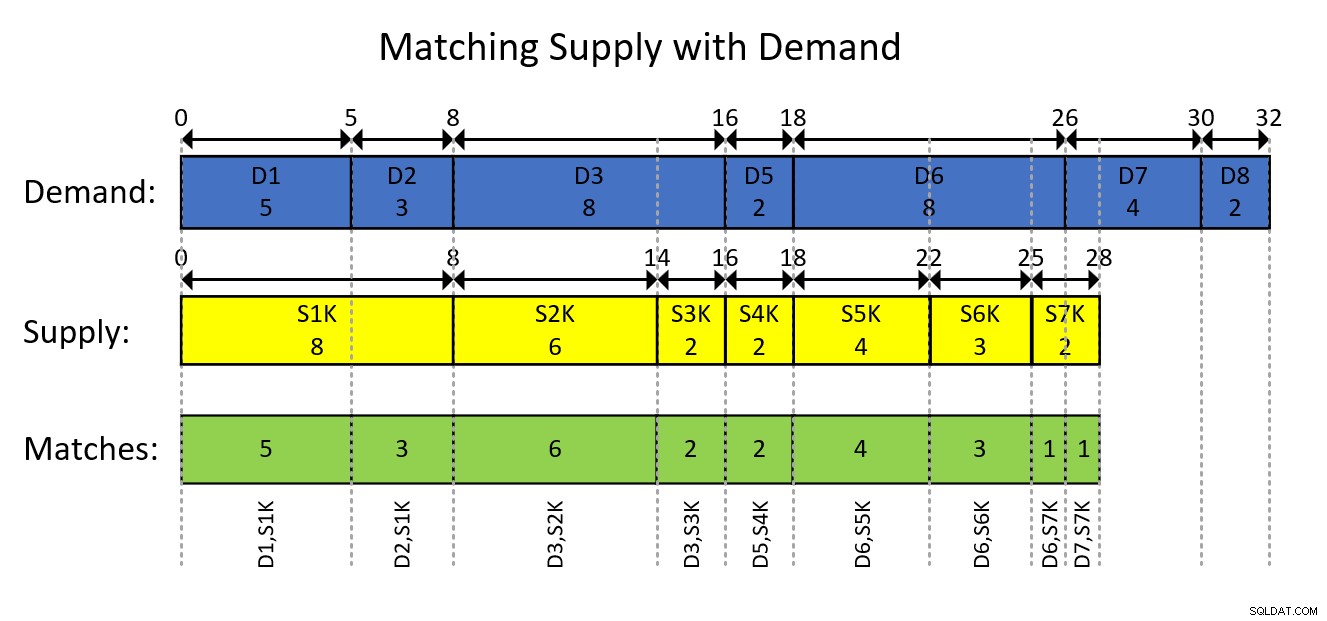 Figura 1:Modelado de los datos como intervalos
Figura 1:Modelado de los datos como intervalos
La representación visual en la Figura 1 se explica por sí misma pero, en resumen...
Los rectángulos azules representan las entradas de demanda como intervalos, mostrando las cantidades totales acumulativas exclusivas como el comienzo del intervalo y el total acumulativo inclusivo como el final del intervalo. Los rectángulos amarillos hacen lo mismo para las entradas de suministro. Luego observe cómo los segmentos superpuestos de los intervalos de intersección de los dos tipos, representados por los rectángulos verdes, son los pares de oferta y demanda que necesita producir. Por ejemplo, el primer emparejamiento de resultados es con ID de demanda 1, ID de suministro 1000, cantidad 5. El segundo emparejamiento de resultados es con ID de demanda 2, ID de suministro 1000, cantidad 3. Y así sucesivamente.
Intersecciones de intervalo usando CTE
Antes de comenzar a escribir el código T-SQL con soluciones basadas en la idea de modelado de intervalos, ya debería tener una idea intuitiva de qué índices pueden ser útiles aquí. Dado que es probable que utilice funciones de ventana para calcular los totales acumulados, podría beneficiarse de un índice de cobertura con una clave basada en las columnas Código, Id. e incluyendo la columna Cantidad. Aquí está el código para crear dicho índice:
CREAR ÍNDICE ÚNICO NO AGRUPADO idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Cantidad);
Ese es el mismo índice que recomendé para la solución basada en cursores que cubrí el mes pasado.
Además, aquí hay potencial para beneficiarse del procesamiento por lotes. Puede habilitar su consideración sin los requisitos del modo por lotes en el almacén de filas, por ejemplo, usando SQL Server 2019 Enterprise o posterior, creando el siguiente índice de almacén de columnas ficticio:
CREAR ÍNDICE DE ALMACÉN DE COLUMNAS NO CLÚSTER idx_cs EN dbo.Auctions(ID) DONDE ID =-1 AND ID =-2;
Ahora puede comenzar a trabajar en el código T-SQL de la solución.
El siguiente código crea los intervalos que representan las entradas de demanda:
CON D0 AS-- D0 calcula la demanda actual como EndDemand( SELECCIONE ID, Cantidad, SUMA(Cantidad) SOBRE(ORDENAR POR ID FILAS SIN LÍMITES PRECEDENTES) AS EndDemand FROM dbo.Auctions WHERE Code ='D'),-- D extrae EndDemand anterior como StartDemand, expresando la demanda de inicio a fin como un intervaloD AS( SELECT ID, Cantidad, EndDemand - Cantidad AS StartDemand, EndDemand FROM D0)SELECT *FROM D;
La consulta que define el CTE D0 filtra las entradas de demanda de la tabla Subastas y calcula una cantidad total acumulada como delimitador final de los intervalos de demanda. Luego, la consulta que define el segundo CTE llamado D consulta D0 y calcula el delimitador inicial de los intervalos de demanda restando la cantidad actual del delimitador final.
Este código genera el siguiente resultado:
ID Cantidad StartDemand EndDemand---- --------- ------------ ----------1 5,000000 0,000000 5,0000002 3,000000 5,000000 8,0000003 8,000000 deLos intervalos de suministro se generan de manera muy similar aplicando la misma lógica a las entradas de suministro, usando el siguiente código:
CON S0 AS-- S0 calcula el suministro actual como EndSupply( SELECCIONE ID, Cantidad, SUMA(Cantidad) SOBRE(ORDENAR POR ID FILAS SIN LÍMITES PRECEDENTES) AS EndSupply FROM dbo.Auctions WHERE Code ='S'),-- S extrae Prev EndSupply como StartSupply, expresando el suministro de inicio a fin como un intervalo S AS( SELECT ID, Cantidad, FinSupply - Cantidad AS StartSupply, EndSupply FROM S0)SELECT *FROM S;Este código genera el siguiente resultado:
ID Cantidad StartSupply EndSupply----- --------- ------------ ----------1000 8.000000 0.000000 8.0000002000 6.000000 8.000000 14.0000003000 2.000000 14.000000 16.0000004000 2.000000 16.000000 18.0000005000 4.000000 18.000000 22.0000006000 3.000000 22.000000 25.00007000 2.000000 25.000000 27.000000Lo que queda es identificar los intervalos de oferta y demanda que se cruzan a partir de los CTE D y S, y calcular los segmentos superpuestos de esos intervalos que se cruzan. Recuerde que los emparejamientos de resultados deben escribirse en una tabla temporal. Esto se puede hacer usando el siguiente código:
-- Eliminar tabla temporal si existe DROP TABLE IF EXISTS #MyPairings; CON D0 AS-- D0 calcula la demanda actual como EndDemand( SELECCIONE ID, Cantidad, SUMA(Cantidad) SOBRE(ORDENAR POR ID FILAS ILIMITADAS PRECEDENTES) AS EndDemand FROM dbo.Auctions WHERE Code ='D'),-- D extrae anterior EndDemand como StartDemand, expresando la demanda inicial-final como un intervaloD AS( SELECT ID, Cantidad, EndDemand - Cantidad AS StartDemand, EndDemand FROM D0),S0 AS-- S0 calcula el suministro actual como EndSupply( SELECT ID, Cantidad, SUM(Cantidad) SOBRE (ORDENAR POR ID FILAS SIN LÍMITES PRECEDENTES) AS EndSupply FROM dbo.Auctions WHERE Code ='S'),-- S extrae Prev EndSupply como StartSupply, expresando el suministro inicial-final como un intervaloS AS( SELECCIONE ID, Cantidad, Suministro final - Cantidad AS StartSupply, EndSupply FROM S0)-- La consulta externa identifica las transacciones como los segmentos superpuestos de los intervalos que se cruzan-- En los intervalos de oferta y demanda que se cruzan, la cantidad comercial es entonces -- MENOR(Demanda Final, SuministroFinal) - MAYOR(Demsnad Inicial, SuministroInicial)SELECCIONAR D.ID COMO DemandID, S.ID COMO SupplyID, CASO WH EN EndDemandStartSupply THEN StartDemand ELSE StartSupply END AS TradeQuantityINTO #MyPairingsFROM D INNER JOIN S ON D.StartDemand S.StartSupply; Además del código que crea los intervalos de oferta y demanda, que ya vio anteriormente, la adición principal aquí es la consulta externa, que identifica los intervalos de intersección entre D y S, y calcula los segmentos superpuestos. Para identificar los intervalos de intersección, la consulta externa une D y S usando el siguiente predicado de unión:
D.StartDemandS.StartSupply Ese es el predicado clásico para identificar la intersección de intervalos. También es la fuente principal del bajo rendimiento de la solución, como explicaré en breve.
La consulta externa también calcula la cantidad comercial en la lista SELECT como:
MENOS(EndDemand, EndSupply) - MAYORES(StartDemand, StartSupply)Si usa Azure SQL, puede usar esta expresión. Si usa SQL Server 2019 o anterior, puede usar la siguiente alternativa lógicamente equivalente:
CASO CUANDO EndDemandStartSupply THEN StartDemand ELSE StartSupply END Dado que el requisito era escribir el resultado en una tabla temporal, la consulta externa utiliza una instrucción SELECT INTO para lograrlo.
La idea de modelar los datos como intervalos es claramente intrigante y elegante. Pero ¿qué pasa con el rendimiento? Desafortunadamente, esta solución específica tiene un gran problema relacionado con cómo se identifica la intersección de intervalos. Examine el plan para esta solución que se muestra en la Figura 2.
Figura 2:Plan de consulta para intersecciones usando la solución CTE
Comencemos con las partes económicas del plan.
La entrada externa de la combinación de bucles anidados calcula los intervalos de demanda. Utiliza un operador de Búsqueda de índice para recuperar las entradas de demanda y un operador Agregado de ventana en modo por lotes para calcular el delimitador final del intervalo de demanda (denominado Expr1005 en este plan). El delimitador de inicio del intervalo de demanda es entonces Expr1005 - Cantidad (de D).
Como nota al margen, es posible que le sorprenda el uso de un operador Ordenar explícito antes del operador Agregado de ventana en modo por lotes, ya que las entradas de demanda recuperadas de Búsqueda de índice ya están ordenadas por ID como la función de ventana necesita que estén. Esto tiene que ver con el hecho de que, actualmente, SQL Server no admite una combinación eficiente de operación de índice de conservación de orden en paralelo antes de un operador de agregado de ventana en modo de lote paralelo. Si fuerza un plan en serie solo con fines de experimentación, verá que el operador Ordenar desaparece. SQL Server decidió en general que se prefería el uso del paralelismo aquí, a pesar de que resultaba en la clasificación explícita adicional. Pero nuevamente, esta parte del plan representa una pequeña porción del trabajo en el gran esquema de las cosas.
De manera similar, la entrada interna de la combinación de bucles anidados comienza calculando los intervalos de suministro. Curiosamente, SQL Server optó por utilizar operadores de modo de fila para manejar esta parte. Por un lado, los operadores de modo de fila utilizados para calcular los totales acumulados implican más gastos generales que la alternativa de agregado de ventana del modo por lotes; por otro lado, SQL Server tiene una implementación paralela eficiente de una operación de índice de preservación del orden seguida por el cálculo de la función de ventana, evitando la clasificación explícita para esta parte. Es curioso que el optimizador eligiera una estrategia para los intervalos de demanda y otra para los intervalos de oferta. En cualquier caso, el operador Index Seek recupera las entradas de suministro y la secuencia subsiguiente de operadores hasta el operador Compute Scalar calcula el delimitador final del intervalo de suministro (denominado Expr1009 en este plan). El delimitador de inicio del intervalo de suministro es entonces Expr1009 - Cantidad (de S).
A pesar de la cantidad de texto que usé para describir estas dos partes, la parte verdaderamente costosa del trabajo en el plan es lo que sigue.
La siguiente parte necesita unir los intervalos de demanda y los intervalos de oferta usando el siguiente predicado:
D.StartDemandS.StartSupply Sin un índice de apoyo, suponiendo intervalos de demanda de DI e intervalos de suministro de SI, esto implicaría procesar filas de DI * SI. El plan de la Figura 2 se creó después de llenar la tabla Subastas con 400 000 filas (200 000 entradas de demanda y 200 000 entradas de oferta). Por lo tanto, sin un índice de respaldo, el plan habría necesitado procesar 200 000 * 200 000 =40 000 000 000 filas. Para mitigar este costo, el optimizador optó por crear un índice temporal (consulte el operador Index Spool) con el delimitador de finalización del intervalo de suministro (Expr1009) como clave. Eso es más o menos lo mejor que podría hacer. Sin embargo, esto soluciona solo una parte del problema. Con dos predicados de rango, solo uno puede ser compatible con un predicado de búsqueda de índice. El otro tiene que ser manejado usando un predicado residual. De hecho, puede ver en el plan que la búsqueda en el índice temporal usa el predicado de búsqueda Expr1009> Expr1005 – D.Quantity, seguido de un operador de filtro que maneja el predicado residual Expr1005> Expr1009 – S.Quantity.
Suponiendo que, en promedio, el predicado de búsqueda aísla la mitad de las filas de oferta del índice por fila de demanda, el número total de filas emitidas desde el operador Index Spool y procesadas por el operador Filter es entonces DI * SI / 2. En nuestro caso, con 200,000 filas de demanda y 200 000 filas de oferta, esto se traduce en 20 000 000 000. De hecho, la fila que va del operador Index Spool al filtro reporta un número de filas cercano a este.
Este plan tiene una escala cuadrática, en comparación con la escala lineal de la solución basada en cursores del mes pasado. Puede ver el resultado de una prueba de rendimiento que compara las dos soluciones en la Figura 3. Puede ver claramente la parábola bien formada para la solución basada en conjuntos.
Figura 3:Rendimiento de las intersecciones usando la solución CTE frente a la solución basada en cursores
Intersecciones de intervalo usando tablas temporales
Puede mejorar un poco las cosas reemplazando el uso de CTE para los intervalos de oferta y demanda con tablas temporales, y para evitar el spool de índice, creando su propio índice en la tabla temporal que contiene los intervalos de oferta con el delimitador final como clave. Aquí está el código de la solución completa:
-- Quitar tablas temporales si existen ELIMINAR TABLA SI EXISTE #MyPairings, #Demand, #Supply; CON D0 AS-- D0 calcula la demanda actual como EndDemand( SELECCIONE ID, Cantidad, SUMA(Cantidad) SOBRE(ORDENAR POR ID FILAS ILIMITADAS PRECEDENTES) AS EndDemand FROM dbo.Auctions WHERE Code ='D'),-- D extrae anterior EndDemand como StartDemand, expresando la demanda inicial-final como un intervaloD AS( SELECT ID, Cantidad, EndDemand - Cantidad AS StartDemand, EndDemand FROM D0)SELECT ID, Cantidad, CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand, CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemandINTO #DemandFROM D;WITH S0 AS-- S0 calcula el suministro actual como EndSupply( SELECT ID, Cantidad, SUM(Cantidad) SOBRE(ORDENAR POR ID FILAS ILIMITADAS PRECEDENTES) AS SuministroFinal DESDE dbo.Subastas DONDE Código ='S'),-- S extrae SuministroFinal anterior como SuministroInicial, expresando el suministro inicial-final como un intervaloS AS( SELECT ID, Cantidad, SuministroFinal - Cantidad AS SuministroInicial, SuministroFinal DESDE S0) SELECCIONE ID, Cantidad, CAST (ISNULL (Suministro inicial, 0.0) COMO DECIMAL (19, 6)) COMO Suministro inicial, CAST (ISNULL (Suministro final, 0.0) AS DECIMAL(19, 6)) AS EndSupplyINTO #SupplyFROM S; CREAR ÍNDICE CLÚSTER ÚNICO idx_cl_ES_ID ON #Supply(EndSupply, ID); -- La consulta externa identifica transacciones como los segmentos superpuestos de los intervalos que se cruzan -- En los intervalos de oferta y demanda que se cruzan, la cantidad de la transacción es -- MENOR (Demanda final, Suministro final) - MAYOR (Iniciar demanda, Iniciar suministro) SELECCIONE D.ID COMO DemandID, S.ID AS SupplyID, CASE WHEN EndDemandStartSupply THEN StartDemand ELSE StartSupply END AS TradeQuantityINTO #MyPairingsFROM #Demand AS D INNER JOIN #Supply AS CON (FORCESEEK) ON D.StartDemand S.StartSupply; Los planes para esta solución se muestran en la Figura 4:
Figura 4:Plan de consulta para intersecciones mediante la solución de tablas temporales
Los dos primeros planes utilizan una combinación de operadores Index Seek + Sort + Window Aggregate en modo por lotes para calcular los intervalos de oferta y demanda y escribirlos en tablas temporales. El tercer plan maneja la creación de índices en la tabla #Supply con el delimitador EndSupply como clave principal.
El cuarto plan representa, con mucho, la mayor parte del trabajo, con un operador de unión de bucles anidados que coincide con cada intervalo de #Demand, los intervalos de intersección de #Supply. Observe que también aquí, el operador Index Seek se basa en el predicado #Supply.EndSupply> #Demand.StartDemand como predicado de búsqueda y #Demand.EndDemand> #Supply.StartSupply como predicado residual. Entonces, en términos de complejidad/escalado, obtienes la misma complejidad cuadrática que en la solución anterior. Simplemente paga menos por fila, ya que está utilizando su propio índice en lugar de la cola de índice utilizada por el plan anterior. Puede ver el rendimiento de esta solución en comparación con las dos anteriores en la Figura 5.
Figura 5:Rendimiento de las intersecciones usando tablas temporales en comparación con otras dos soluciones
Como puede ver, la solución con las tablas temporales funciona mejor que la que tiene los CTE, pero todavía tiene una escala cuadrática y lo hace muy mal en comparación con el cursor.
¿Qué sigue?
Este artículo cubrió el primer intento de manejar la clásica tarea de hacer coincidir la oferta con la demanda utilizando una solución basada en conjuntos. La idea era modelar los datos como intervalos, hacer coincidir la oferta con las entradas de demanda mediante la identificación de los intervalos de oferta y demanda que se cruzan, y luego calcular la cantidad de negociación en función del tamaño de los segmentos superpuestos. Sin duda, una idea intrigante. El problema principal es también el problema clásico de identificar la intersección de intervalos mediante el uso de dos predicados de rango. Incluso con el mejor índice implementado, solo puede admitir un predicado de rango con una búsqueda de índice; el otro predicado de rango tiene que ser manejado usando un predicado residual. Esto da como resultado un plan con complejidad cuadrática.
Entonces, ¿qué puedes hacer para superar este obstáculo? Hay varias ideas diferentes. Una idea brillante pertenece a Joe Obbish, sobre la que puede leer en detalle en su publicación de blog. Cubriré otras ideas en los próximos artículos de la serie.
[ Saltar a:Desafío original | Soluciones:Parte 1 | Parte 2 | Parte 3 ]