Este es el primer artículo de una serie de artículos sobre In-Memory OLTP. Le ayuda a comprender cómo funciona internamente el nuevo motor Hekaton. Nos centraremos en los detalles de las tablas e índices optimizados en memoria. Este es el artículo de nivel de entrada, lo que significa que no necesita ser un experto en SQL Server; sin embargo, sí necesita tener algunos conocimientos básicos sobre el motor tradicional de SQL Server.
Introducción
El motor OLTP en memoria de SQL Server 2014 (proyecto Hekaton) se creó desde cero para utilizar terabytes de memoria disponible y una gran cantidad de núcleos de procesamiento. OLTP en memoria permite a los usuarios trabajar con tablas e índices optimizados para memoria y procedimientos almacenados compilados de forma nativa. Puede usarlo junto con las tablas e índices basados en disco y los procedimientos almacenados de T-SQL que SQL Server siempre ha proporcionado.
Los componentes internos y las capacidades del motor OLTP en memoria difieren significativamente del motor relacional estándar. Debe revisar casi todo lo que sabía sobre cómo se manejan múltiples procesos concurrentes.
El motor de SQL Server está optimizado para el almacenamiento basado en disco. Lee páginas de datos de 8 KB en la memoria para su procesamiento y vuelve a escribir páginas de datos de 8 KB en el disco después de las modificaciones. Por supuesto, SQL Server corrige principalmente los cambios en el disco en el registro de transacciones. Leer páginas de datos de 8 KB desde el disco y volver a escribirlas puede generar una gran cantidad de E/S y conduce a un mayor costo de latencia. Incluso cuando los datos están en la memoria caché del búfer, el servidor SQL está diseñado para asumir que no es así, lo que conduce a un uso ineficiente de la CPU.
Teniendo en cuenta las limitaciones de las estructuras de almacenamiento tradicionales basadas en disco, el equipo de SQL Server comenzó a crear un motor de base de datos optimizado para una gran memoria principal y CPU de múltiples núcleos. El equipo se fijó los siguientes objetivos:
- Optimizado para datos que se almacenaron por completo en la memoria pero que también fueron duraderos en los reinicios de SQL Server
- Totalmente integrado en el motor de SQL Server existente
- Rendimiento muy alto para operaciones OLTP
- Diseñado para CPU modernas
SQL Server In-Memory OLTP cumple todos estos objetivos.
Acerca de OLTP en memoria
SQL Server 2014 In-Memory OLTP proporciona una serie de tecnologías para trabajar con tablas optimizadas para memoria, junto con las tablas basadas en disco. Por ejemplo, le permite acceder a datos en memoria utilizando interfaces estándar como T-SQL y SSMS. La siguiente ilustración muestra tablas e índices optimizados para memoria, como parte de In-Memory OLTP (a la izquierda) y las tablas basadas en disco (a la izquierda) que requieren leer y escribir páginas de datos de 8 KB. In-Memory OLTP también admite procedimientos almacenados compilados de forma nativa y proporciona un nuevo compilador de OLTP en memoria.
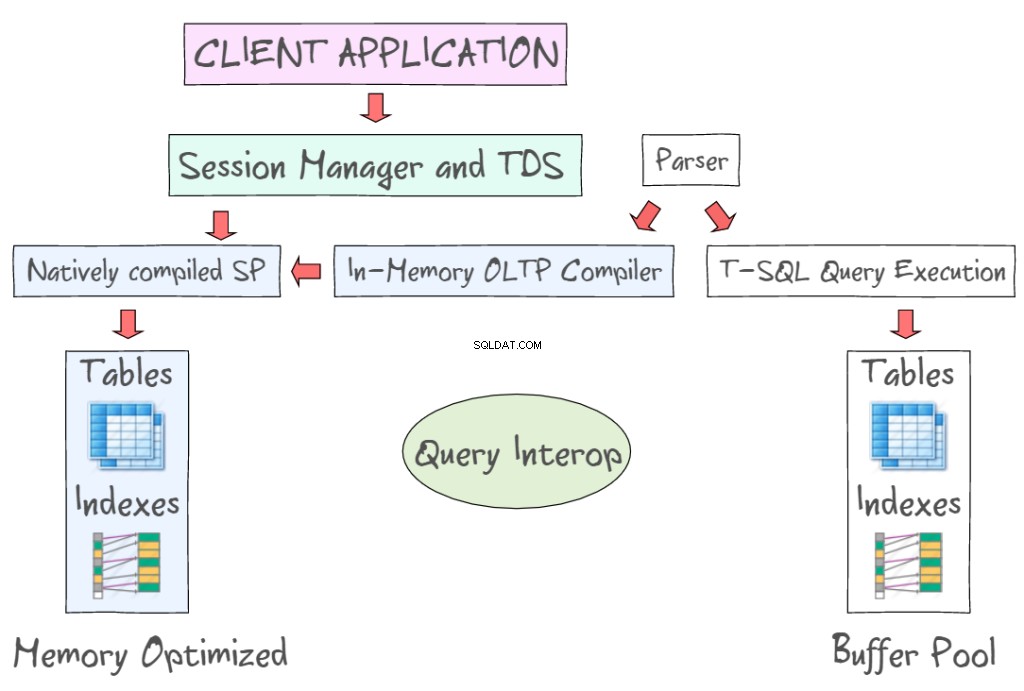
Query Interop permite interpretar T-SQL para hacer referencia a tablas optimizadas para memoria. Si una transacción hace referencia a tablas basadas en disco y optimizadas para memoria, se puede denominar transacción entre contenedores. La aplicación del cliente utiliza Tabular Data Stream, un protocolo de capa de aplicación que se utiliza para transferir datos entre un servidor de base de datos y un cliente. Fue inicialmente diseñado y desarrollado por Sybase Inc. para su motor de base de datos relacional Sybase SQL Server en 1984, y luego por Microsoft en Microsoft SQL Server.
Tablas optimizadas para memoria
Al acceder a las tablas basadas en disco, es posible que los datos necesarios ya estén en la memoria, aunque es posible que no lo estén. Si los datos no están en la memoria, SQL Server necesita leerlos del disco. La diferencia más fundamental al usar tablas optimizadas para memoria es que la tabla completa y sus índices se almacenan en la memoria todo el tiempo . Las operaciones de datos simultáneas no requieren bloqueo ni bloqueo.
Mientras un usuario modifica los datos en la memoria, SQL Server realiza algunas E/S de disco para cualquier tabla que deba ser duradera; de lo contrario, necesitamos una tabla para retener los datos en la memoria en el momento de un bloqueo o reinicio del servidor.
Estructura de almacenamiento basada en filas
Otra diferencia significativa es la estructura de almacenamiento subyacente. Las tablas basadas en disco están optimizadas para bloqueo direccionable almacenamiento en disco, mientras que las tablas optimizadas en memoria están optimizadas para byte-direccionable almacenamiento de memoria.
SQL Server mantiene filas de datos en páginas de datos de 8K, con asignación de espacio de extensiones para tablas basadas en disco. La página de datos es la unidad fundamental de almacenamiento en disco y memoria. Mientras lee y escribe datos del disco, SQL Server lee y escribe solo las páginas de datos relevantes. Una página de datos solo contendrá datos de una tabla o índice. Los procesos de aplicación modifican filas en diferentes páginas de datos según sea necesario. Posteriormente, durante la operación CHECKPOINT, SQL Server primero corrige los registros en el disco y luego escribe todas las páginas sucias en el disco. Esta operación a menudo provoca una gran cantidad de E/S físicas aleatorias.
Para las tablas optimizadas para memoria, no hay páginas de datos ni extensiones. Solo hay filas de datos escritas en la memoria secuencialmente, en el orden en que ocurrieron las transacciones. Cada fila contiene un puntero de índice a la siguiente fila. Toda la E/S es exploración en memoria de estas estructuras. No existe la noción de que las filas de datos se escriban en una ubicación particular que pertenezca a un objeto específico. Aunque, no tiene que pensar que las tablas optimizadas para memoria se almacenan como un conjunto no organizado de filas de datos (similar a los montones basados en disco). Cada declaración CREATE TABLE para una tabla optimizada para memoria crea al menos un índice que SQL Server usa para vincular todas las filas de datos en esa tabla.
Cada fila de datos consiste en el encabezado de la fila y la carga útil que son los datos reales de la columna. El encabezado almacena información sobre la declaración que creó la fila, punteros para cada índice en la tabla de destino y valores de marca de tiempo. La marca de tiempo indica la hora en que una transacción insertó y eliminó una fila. Registros de SQL Server actualizados insertando una nueva versión de fila y marcando la versión anterior como eliminada. Pueden existir varias versiones de la misma fila en un momento dado. Esto permite el acceso simultáneo a la misma fila durante la modificación de datos. SQL Server muestra la versión de la fila relevante para cada transacción según la hora en que comenzó la transacción en relación con las marcas de tiempo de la versión de la fila. Este es el núcleo del nuevo control de concurrencia de múltiples versiones mecanismo para tablas en memoria.
Por cierto, Oracle tiene un excelente sistema de control de múltiples versiones. Básicamente, funciona de la siguiente manera:
- El usuario A inicia una transacción y actualiza 1000 filas con algún valor en el momento T1.
- El usuario B lee las mismas 1000 filas en el momento T2.
- El usuario A actualiza la fila 565 con el valor Y (el valor original era X).
- El usuario B llega a la fila 565 y encuentra que una transacción está en operación desde el tiempo T1.
- La base de datos devuelve el registro sin modificar de los registros. El valor devuelto es el valor que se comprometió en el momento menor o igual a T2.
- Si no se pudo recuperar el registro de los registros de rehacer, significa que la base de datos no está configurada correctamente. Es necesario asignar más espacio a los registros.
- Los resultados devueltos son siempre los mismos con respecto a la hora de inicio de la transacción. Entonces, dentro de la transacción, se logra la consistencia de lectura.
Tablas compiladas de forma nativa
La principal diferencia final es que las tablas optimizadas en memoria se compilan de forma nativa . Cuando un usuario crea una tabla o índice optimizado para memoria, SQL Server almacena la estructura de cada tabla (junto con todos los índices) en los metadatos. Posteriormente, SQL Server utiliza esos metadatos para compilar en DDL un conjunto de rutinas de idioma nativo para acceder a la tabla. Dichos DDL están asociados con la base de datos, pero en realidad no forman parte de ella.
En otras palabras, SQL Server mantiene en la memoria no solo tablas e índices, sino también DDL para acceder y modificar estas estructuras. Una vez que se modificó una tabla, SQL Server debe volver a crear todo el DDL para las operaciones de la tabla. Es por eso que no puede modificar una tabla una vez creada. Estas operaciones son invisibles para los usuarios.
Procedimientos almacenados compilados de forma nativa
El mejor rendimiento se logra al utilizar procedimientos almacenados compilados de forma nativa para acceder a las tablas compiladas de forma nativa. Dichos procedimientos contienen instrucciones del procesador y pueden ser ejecutados directamente por la CPU sin compilación adicional. Sin embargo, existen algunas restricciones en las construcciones de T-SQL para los procedimientos almacenados compilados de forma nativa (en comparación con el código interpretado tradicionalmente). Otro punto importante es que los procedimientos almacenados compilados de forma nativa solo pueden acceder a tablas optimizadas para memoria.
Sin candados
In-Memory OLTP es un sistema sin bloqueo. Esto es posible porque SQL Server nunca modifica ninguna fila existente. La operación ACTUALIZAR crea la nueva versión y marca la versión anterior como eliminada. Luego inserta una nueva versión de fila con nuevos datos dentro.
Índices
Como habrás adivinado, los índices son muy diferentes a los tradicionales. Las tablas optimizadas en memoria no tienen páginas. SQL Server utiliza índices para vincular todas las filas que pertenecen a una tabla en una sola estructura. No podemos usar la instrucción CREATE INDEX para crear un índice para la tabla optimizada en memoria. Una vez que haya creado la CLAVE PRIMARIA en una columna, SQL Server crea automáticamente un índice único en esa columna. En realidad, es el único índice único permitido. Puede crear un máximo de ocho índices en una tabla optimizada para memoria.
Por analogía con las tablas, SQL Server mantiene índices optimizados para memoria en la memoria. Sin embargo, SQL Server nunca registra operaciones en índices. SQL Server mantiene los índices automáticamente durante las modificaciones de la tabla.
Las tablas optimizadas para memoria admiten dos tipos de índices:índice hash y índice de rango . Ambas son estructuras no agrupadas.
El índice hash es un nuevo tipo de índice, diseñado específicamente para tablas optimizadas para memoria. Es extremadamente útil para realizar búsquedas en valores específicos. El índice en sí se almacena como una tabla hash. Es una matriz de cubos hash, donde cada cubo es un puntero a una sola fila.
El índice de rango (no agrupado) es útil para recuperar rangos de valores.
Recuperación
El mecanismo de restauración básico para una base de datos con tablas optimizadas para memoria es el mismo que el mecanismo de recuperación de bases de datos con tablas basadas en disco. Sin embargo, la recuperación de tablas optimizadas para memoria incluye el paso de cargar las tablas optimizadas para memoria en la memoria antes de que la base de datos esté disponible para el acceso del usuario.
Cuando SQL Server se reinicia, cada base de datos pasa por las siguientes fases del proceso de recuperación:análisis , rehacer y deshacer .
En la fase de análisis, el motor OLTP en memoria identifica el inventario del punto de control para cargar y precarga las entradas de registro de la tabla del sistema. También procesará algunos registros de asignación de archivos.
En la fase de rehacer, los datos de los pares de archivos de datos y delta se cargan en la memoria. Luego, los datos se actualizan desde el registro de transacciones activo en función del último punto de control duradero y las tablas en memoria se completan y los índices se reconstruyen. Durante esta fase, la recuperación de tablas basada en disco y optimizada para memoria se ejecuta simultáneamente.
La fase de deshacer no es necesaria para las tablas optimizadas para memoria, ya que In-Memory OLTP no registra ninguna transacción no confirmada para las tablas optimizadas para memoria.
Cuando se completan todas las operaciones, la base de datos está disponible para el acceso.
Resumen
En este artículo, echamos un vistazo rápido al motor OLTP en memoria de SQL Server. Hemos aprendido que las estructuras optimizadas para memoria se almacenan en la memoria. Los procesos de aplicación pueden encontrar los datos necesarios accediendo a estas estructuras en la memoria sin necesidad de E/S de disco. En los siguientes artículos, veremos cómo crear y acceder a bases de datos y tablas OLTP en memoria.
Lecturas adicionales
OLTP en memoria:novedades de SQL Server 2016
Uso de índices en tablas optimizadas para memoria de SQL Server