Desde el lanzamiento de SQL Server 2017 para Linux, Microsoft prácticamente ha cambiado todo el juego. Habilitó un mundo completamente nuevo de posibilidades para su famosa base de datos relacional, ofreciendo lo que hasta entonces solo estaba disponible en el espacio de Windows.
Sé que un DBA purista me diría de inmediato que la versión Linux lista para usar de SQL Server 2019 tiene varias diferencias, en términos de características, con respecto a su contraparte de Windows, tales como:
- Sin Agente SQL Server
- Sin transmisión de archivos
- Sin procedimientos almacenados extendidos del sistema (por ejemplo, xp_cmdshell)
Sin embargo, tuve la curiosidad de pensar "¿y si se pueden comparar, al menos hasta cierto punto, con cosas que ambos pueden hacer?" Entonces, apreté el gatillo en un par de máquinas virtuales, preparé algunas pruebas simples y recopilé datos para presentárselos. ¡Veamos cómo resultan las cosas!
Consideraciones iniciales
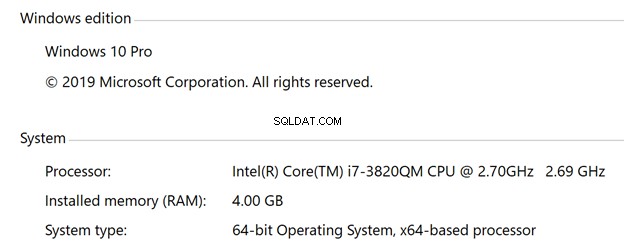
Estas son las especificaciones de cada máquina virtual:
- Ventanas
- SO Windows 10
- 4 vCPU
- 4 GB de RAM
- SSD de 30 GB
- Linux
- Servidor Ubuntu 20.04 LTS
- 4 vCPU
- 4 GB de RAM
- SSD de 30 GB


Para la versión de SQL Server, elegí la más reciente para ambos sistemas operativos:SQL Server 2019 Developer Edition CU10
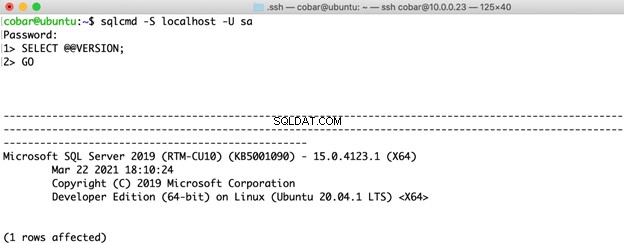
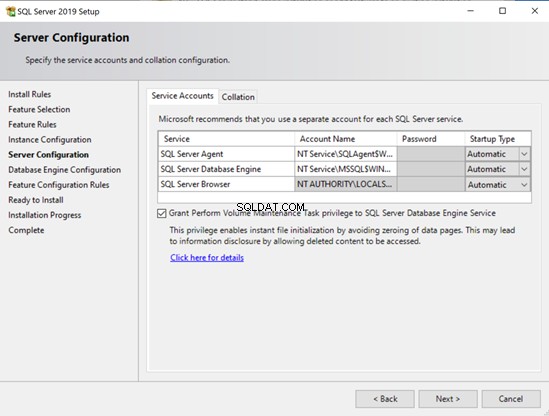
En cada implementación, lo único habilitado fue la inicialización instantánea de archivos (habilitada de forma predeterminada en Linux, habilitada manualmente en Windows). Aparte de eso, los valores predeterminados se mantuvieron para el resto de la configuración.
- En Windows, puede optar por habilitar la inicialización instantánea de archivos con el asistente de instalación.
Esta publicación no cubrirá la especificidad del trabajo de inicialización instantánea de archivos en Linux. Sin embargo, te dejaré un enlace al artículo dedicado que puedes leer más tarde (ten en cuenta que se vuelve un poco pesado en el aspecto técnico).
¿Qué incluye la prueba?
- En cada instancia de SQL Server 2019, implementé una base de datos de prueba y creé una tabla con un solo campo (un NVARCHAR(MAX)).
- Usando una cadena generada aleatoriamente de 1 000 000 de caracteres, realicé los siguientes pasos:
- *Inserte X número de filas en la tabla de prueba.
- Mida cuánto tiempo tomó completar la instrucción INSERT.
- Mida el tamaño de los archivos MDF y LDF.
- Eliminar todas las filas de la tabla de prueba.
- **Mide cuánto tiempo se tardó en completar la instrucción DELETE.
- Mida el tamaño del archivo LDF.
- Elimine la base de datos de prueba.
- Vuelva a crear la base de datos de prueba.
- Repita el mismo ciclo.
*X se realizó para 1000, 5000, 10 000, 25 000 y 50 000 filas.
**Sé que una declaración TRUNCATE hace el trabajo de manera más eficiente, pero mi punto aquí es demostrar qué tan bien se administra cada registro de transacciones para la operación de eliminación en cada sistema operativo.
Puedes ir al sitio web que usé para generar la cadena aleatoria si quieres profundizar más.
Aquí están las secciones del código TSQL que usé para las pruebas en cada sistema operativo:
Códigos TSQL de Linux
Creación de bases de datos y tablas
DROP DATABASE IF EXISTS test
CREATE DATABASE test
ON
(FILENAME= '/var/opt/mssql/data/test.mdf', NAME = test, FILEGROWTH = 128MB)
LOG ON
(FILENAME= '/var/opt/mssql/data/test_log.ldf',NAME = test_log, FILEGROWTH = 64MB);
CREATE TABLE test.dbo.ubuntu(
long_string NVARCHAR(MAX) NOT NULL
)
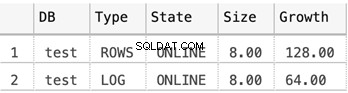
Tamaño de los archivos MDF y LDF para la base de datos de prueba
SELECT
DB_NAME(database_id) AS 'DB',
type_desc AS 'Type',
state_desc AS 'State',
CONVERT(DECIMAL(10,2),size*8/1024) AS 'Size',
CONVERT(DECIMAL(10,2),growth*8/1024) AS 'Growth'
FROM sys.master_files
WHERE DB_NAME(database_id) = 'test'
La siguiente captura de pantalla muestra los tamaños de los archivos de datos cuando no hay nada almacenado en la base de datos:
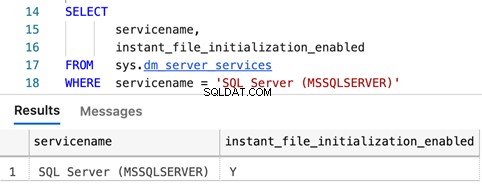
Consultas para determinar si la inicialización instantánea de archivos está habilitada
SELECT
servicename,
instant_file_initialization_enabled
FROM sys.dm_server_services
WHERE servicename = 'SQL Server (MSSQLSERVER)'

Códigos TSQL de Windows
Creación de bases de datos y tablas
DROP DATABASE IF EXISTS test
CREATE DATABASE test
ON
(FILENAME= 'S:\Program Files\Microsoft SQL Server\MSSQL15.WINDOWS\MSSQL\DATA\test.mdf', NAME = test, FILEGROWTH = 128MB)
LOG ON
(FILENAME= ''S:\Program Files\Microsoft SQL Server\MSSQL15.WINDOWS\MSSQL\DATA\test_log.ldf',NAME = test_log, FILEGROWTH = 64MB);
CREATE TABLE test.dbo.windows(
long_string NVARCHAR(MAX) NOT NULL
)
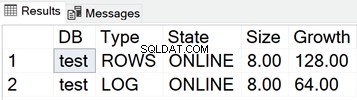
Tamaño de los archivos MDF y LDF para la base de datos de prueba
SELECT
DB_NAME(database_id) AS 'DB',
type_desc AS 'Type',
state_desc AS 'State',
CONVERT(DECIMAL(10,2),size*8/1024) AS 'Size',
CONVERT(DECIMAL(10,2),growth*8/1024) AS 'Growth'
FROM sys.master_files
WHERE DB_NAME(database_id) = 'test'
La siguiente captura de pantalla muestra los tamaños de los archivos de datos cuando no hay nada almacenado en la base de datos:
Consulta para determinar si la inicialización instantánea de archivos está habilitada
SELECT
servicename,
instant_file_initialization_enabled
FROM sys.dm_server_services
WHERE servicename = 'SQL Server (MSSQLSERVER)'
Script para realizar la instrucción INSERT:
@limit -> aquí especifiqué el número de filas para insertar en la tabla de prueba
Para Linux, como ejecuté el script usando SQLCMD, puse la función DATEDIFF al final. Me permite saber cuántos segundos lleva toda la ejecución (para la variante de Windows, simplemente podría haber echado un vistazo al temporizador en SQL Server Management Studio).
La cadena completa de 1,000,000 de caracteres va en lugar de 'XXXX'. Lo pongo así solo para presentarlo bien en esta publicación.
SET NOCOUNT ON
GO
DECLARE @StartTime DATETIME;
DECLARE @i INT;
DECLARE @limit INT;
SET @StartTime = GETDATE();
SET @i = 0;
SET @limit = 1000;
WHILE(@i < @limit)
BEGIN
INSERT INTO test.dbo.ubuntu VALUES('XXXX');
SET @i = @i + 1
END
SELECT DATEDIFF(SECOND,@StartTime,GETDATE()) AS 'Elapsed Seconds';
Script para realizar la instrucción DELETE
SET NOCOUNT ON
GO
DECLARE @StartTime DATETIME;
SET @StartTime = GETDATE();
DELETE FROM test.dbo.ubuntu;
SELECT DATEDIFF(SECOND,@StartTime,GETDATE()) AS 'Elapsed Seconds';
Los resultados obtenidos
Todos los tamaños se expresan en MB. Todas las medidas de tiempo se expresan en segundos.
| INSERTAR hora | 1000 registros | 5000 registros | 10.000 registros | 25.000 registros | 50.000 registros |
| Linux | 4 | 23 | 43 | 104 | 212 |
| Windows | 4 | 28 | 172 | 531 | 186 |
| Tamaño (MDF) | 1000 registros | 5000 registros | 10.000 registros | 25.000 registros | 50.000 registros |
| Linux | 264 | 1032 | 2056 | 5128 | 10184 |
| Windows | 264 | 1032 | 2056 | 5128 | 10248 |
| Tamaño (LDF) | 1000 registros | 5000 registros | 10.000 registros | 25.000 registros | 50.000 registros |
| Linux | 104 | 264 | 360 | 552 | 148 |
| Windows | 136 | 328 | 392 | 456 | 584 |
| BORRAR Hora | 1000 registros | 5000 registros | 10.000 registros | 25.000 registros | 50.000 registros |
| Linux | 1 | 1 | 74 | 215 | 469 |
| Windows | 1 | 63 | 126 | 357 | 396 |
| ELIMINAR Tamaño (LDF) | 1000 registros | 5000 registros | 10.000 registros | 25.000 registros | 50.000 registros |
| Linux | 136 | 264 | 392 | 584 | 680 |
| Windows | 200 | 328 | 392 | 456 | 712 |
Información clave
- El tamaño del MDF fue bastante consistente durante toda la prueba, variando ligeramente al final (pero nada demasiado loco).
- Los tiempos para INSERT fueron mejores en Linux en su mayor parte, excepto al final, cuando Windows "ganó la ronda".
- El tamaño del archivo de registro de transacciones se manejó mejor en Linux después de cada ronda de INSERT.
- Los tiempos para DELETE fueron mejores en Linux en su mayor parte, excepto al final, donde Windows "ganó la ronda" (me parece curioso que Windows también ganó la ronda INSERT final).
- El tamaño de los archivos de registro de transacciones después de cada ronda de ELIMINACIÓN era prácticamente un empate en términos de altibajos entre los dos.
- Me hubiera gustado probar con 100.000 filas, pero me faltaba un poco de espacio en disco, así que lo limité a 50.000.
Conclusión
Según los resultados obtenidos de esta prueba, diría que no hay una razón sólida para afirmar que la variante de Linux funciona exponencialmente mejor que su contraparte de Windows. Por supuesto, esto no es de ninguna manera una prueba formal en la que pueda basarse para tomar tal decisión. Sin embargo, el ejercicio en sí fue lo suficientemente interesante para mí.
Supongo que SQL Server 2019 para Windows a veces se retrasa un poco (no mucho) debido a la representación de la GUI en segundo plano, lo que no sucede en el lado de la valla del servidor Ubuntu.
Si confía en gran medida en las características y capacidades que son exclusivas de Windows (al menos en el momento de escribir este artículo), entonces hágalo. De lo contrario, difícilmente tomará una mala decisión eligiendo uno u otro.