La automatización de procesos de back-end en su instancia de SQL Server es una tarea común. Ya sea actualizando las estadísticas, reconstruyendo índices, leyendo o eliminando datos, es extremadamente valioso integrar otros marcos de programación con su RDBMS. Este artículo considerará este tipo de tareas específicamente integradas con Python.
No nos centraremos en cuestiones tan fundamentales como qué es SQL y Python, o cómo y dónde los usamos. En cambio, vamos a examinar los casos específicos que requieren combinar SQL y Python, y varios módulos de métodos disponibles para hacerlo.
Cadena de conexión del servidor SQL
Antes de comenzar a explorar el caso de la conexión de Python al servidor SQL, familiaricémonos con los conceptos básicos.
Una cadena de conexión representa los datos necesarios que apuntan a la instancia de la base de datos y la autentican. Puede haber pequeños matices para cada tipo de instancia de base de datos, pero en general, la información requerida sería el nombre del servidor, el controlador de la base de datos, el nombre de usuario, la contraseña y el número de puerto.
Detalles de la instancia del servidor SQL
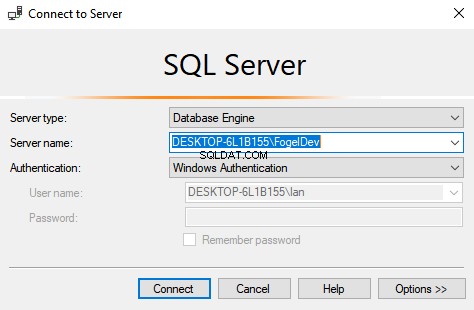
Los detalles de esta cadena de conexión serán los mismos que cuando se conecta mediante SSMS a la instancia de la base de datos. Tome nota de la instancia de la base de datos {SERVER}\{INSTANCE} formato:aquí está DESKTOP-6L1B155\FogelDev . También es posible conectarse a un nombre de servidor si tiene una sola instancia predeterminada en ejecución.
Base de datos de SQL Server y código de creación de tablas
Primero, necesitamos una base de datos con una estructura de tabla necesaria para trabajar con Python y SQL Server. El siguiente script creará dicha base de datos y una sola tabla en ella. Esa tabla servirá como área de demostración para que veamos cómo usar SQL y Python juntos.
CREATE DATABASE CODESIGHT_DEMOS;
USE CODESIGHT_DEMOS;
CREATE TABLE POSTS
(
ID INT IDENTITY(1,1) PRIMARY KEY,
NAME VARCHAR(200),
Author VARCHAR(100),
URL VARCHAR(100),
DATE DATE
)
INSERT INTO POSTS
VALUES('Properly Dealing with Encryption of Databases in an AlwaysOn Availability Group Scenario','Alejandro Cobar','https://codingsight.com/encryption-of-databases-in-alwayson-availability-group-scenario/','4/23/2021')
INSERT INTO POSTS
VALUES('An Overview of DataFrames in Python','Aveek Das','https://codingsight.com/an-overview-of-dataframes-in-python/','4/23/2021')
INSERT INTO POSTS
VALUES('SQL Server Business Intelligence (BI) – Traditional Tools and Technologies','Haroon Ashraf','https://codingsight.com/sql-server-business-intelligence-bi-tools-and-technologies/','4/19/2021')
Módulos de Python
Nuestro objetivo ahora es definir cómo conectar Python a las instancias del servidor SQL. Hay varios módulos de Python disponibles para realizar esta tarea, y dos de ellos son principales. Vamos a tratar con PYODC y SQLAlchemy . Estos módulos manejan la parte de conexión de las operaciones.
Se requiere un código adicional para leer los datos de las tablas de SQL Server en la memoria. Aquí es donde los Pandas entra la biblioteca.
Pandas se puede integrar estrechamente con SQLALchemy para leer los datos directamente en el DataFrame objetos (en almacenamiento basado en matriz de memoria que puede funcionar a la velocidad del rayo y parecerse a las tablas de una base de datos).
Echemos un vistazo a algunos ejemplos de cadenas de conexión.
El primer ejemplo usa el servidor SQL y la instancia de la captura de pantalla anterior. Puede establecer estas variables en sus detalles específicos para instanciar la conexión.
Tenga en cuenta también que esta conexión en particular utiliza la autenticación de Windows. Por lo tanto, intentará autenticarse como el usuario de mi máquina de Windows en la que estoy conectado. Si no se especifican nombre de usuario y contraseña, este es el comportamiento predeterminado en la cadena de conexión.
- Nombre del servidor ='ESCRITORIO-6L1B155'
- Nombre de instancia ='FogelDev'
- Nombre de la base de datos ='CODESIGHT_DEMOS'
- Número de puerto ='1433'
print("mssql+pyodbc://@{SERVER}:{PORT}\\{INSTANCE}/{DATABASE}?driver=SQL+Server+Native+Client+11.0".format(SERVER = Servername, INSTANCE = Instancename,DATABASE = Databasename,PORT = Portnumber))
MSSQLengine = sqlalchemy.create_engine("mssql+pyodbc://@{SERVER}\\{INSTANCE}:{PORT}/{DATABASE}?driver=SQL+Server+Native+Client+11.0".format(SERVER = Servername, INSTANCE = Instancename,DATABASE = Databasename,PORT = Portnumber))
Podemos probar si esta conexión funciona correctamente ejecutando una consulta con Pandas. Tiene que leer una consulta de la cadena de conexión usando read_sql_query comando.
df = pd.read_sql_query("SELECT * FROM POSTS", MSSQLengine)
df

Autenticación del servidor SQL
¿Qué sucede si necesita usar la cadena de conexión basada en la autenticación del servidor SQL para conectarse a su servidor SQL? Podemos ajustar nuestro código de Python para agregar nombre de usuario y contraseña a SQLALchemy motor.
- Nombre del servidor ='ESCRITORIO-6L1B155'
- Instancename ='FogelDev'
- Nombre de la base de datos ='CODESIGHT_DEMOS'
- Número de puerto ='1433'
- Nombre de usuario ='CodingSightUser'
- Contraseña ='Contraseña123'
print("mssql+pyodbc://{USER}:{PASS}@{SERVER}:{PORT}\\{INSTANCE}/{DATABASE}?driver=SQL+Server+Native+Client+11.0".format(SERVER = Servername, INSTANCE = Instancename,DATABASE = Databasename,PORT = Portnumber,USER = Username, PASS = Password))
MSSQLengine = sqlalchemy.create_engine("mssql+pyodbc://{USER}:{PASS}@{SERVER}\\{INSTANCE}:{PORT}/{DATABASE}?driver=SQL+Server+Native+Client+11.0".format(SERVER = Servername, INSTANCE = Instancename,DATABASE = Databasename,PORT = Portnumber,USER = Username, PASS = Password))
Nuevamente, estamos probando nuestra conexión, pero esta vez seleccionamos 1 registro de la tabla solamente.
df = pd.read_sql_query("SELECT TOP 1 * FROM POSTS", MSSQLengine)
df
Escribir datos
Finalmente, eche un vistazo a obtener los datos de Python en nuestra tabla de base de datos de SQL Server. Creamos un objeto Dataframe y lo agregamos a la tabla.
El método del marco de datos:
newdata = [{'Name': 'How to Create the Date Table in Power BI', 'Author': 'Haroon Ashraf', 'URL':'https://codingsight.com/how-to-create-date-table-in-power-bi/', 'Date':'4/21/21'}]
load_df = pd.DataFrame(newdata)
load_df.to_sql("POSTS", MSSQLengine, if_exists='append',index = False, chunksize = 200)
Otro método sería insertar los datos directamente en la tabla con el comando de ejecución.
El método de ejecución:
MSSQLengine.execute("INSERT INTO [POSTS] VALUES('SQL Query Optimization: 5 Core Facts to Boost Queries','Edwin Sanchez','https://codingsight.com/sql-query-optimization-5-core-facts-to-boost-queries/','3/31/21')");Cuando termine, la tabla final se verá de la siguiente manera. Tiene las primeras 3 filas cargadas por el script de creación inicial de SQL Server, y Python carga las filas 4 y 5.

Resumen
Esta publicación destacó los parámetros de la cadena de conexión para conectar el código de Python con SQL Server. Examinamos la lectura de los datos del servidor SQL y verificamos dos métodos de autenticación diferentes:el caso específico de la conexión de Python a la autenticación de Windows del servidor SQL y la autenticación del servidor SQL estándar. Además, revisamos los métodos para cargar datos, uno de los cuales implica el uso del objeto DataFrame en Python, y otro es un comando SQL INSERT sin formato.