Un ejemplo en el que esto puede marcar la diferencia es que puede evitar una optimización del rendimiento que evite agregar información de versiones de filas a las tablas con desencadenantes posteriores.
Esto está cubierto por Paul White aquí
El tamaño real de los datos almacenados es irrelevante; lo que importa es el tamaño potencial.
De manera similar, si usa tablas optimizadas para memoria desde 2016, ha sido posible usar columnas LOB o combinaciones de anchos de columna que podrían exceder el límite de entrada pero con una penalización.
Las columnas (máx.) siempre se almacenan fuera de fila. Para otras columnas, si el tamaño de la fila de datos en la definición de la tabla puede exceder los 8060 bytes, SQL Server coloca las columnas de longitud variable más grandes fuera de la fila. Nuevamente, no depende de la cantidad de datos que almacene allí.
Esto puede tener un gran efecto negativo en el consumo de memoria y el rendimiento
Otro caso en el que la declaración excesiva de anchos de columna puede marcar una gran diferencia es si la tabla alguna vez se procesará con SSIS. La memoria asignada para columnas de longitud variable (no BLOB) es fija para cada fila en un árbol de ejecución y es por la longitud máxima declarada de las columnas, lo que puede conducir a un uso ineficiente de los búferes de memoria (ejemplo). Si bien el desarrollador del paquete SSIS puede declarar un tamaño de columna más pequeño que la fuente, es mejor realizar este análisis por adelantado y aplicarlo allí.
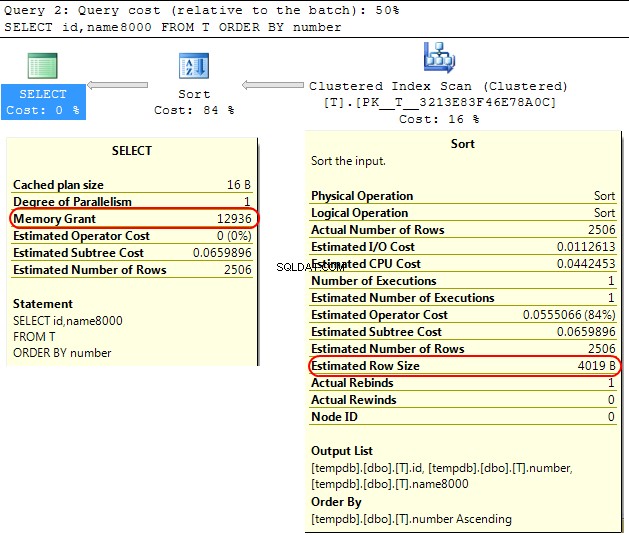
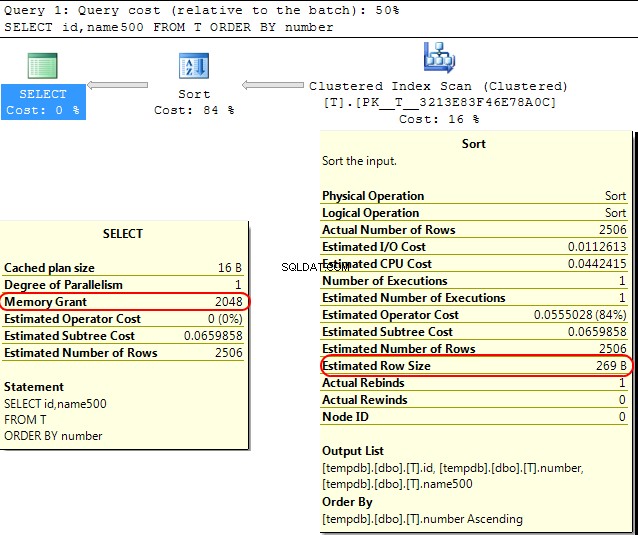
De vuelta en el propio motor de SQL Server, un caso similar es que al calcular la concesión de memoria para asignar para SORT operaciones SQL Server asume que varchar(x) las columnas consumirán en promedio x/2 bytes.
Si la mayor parte de su varchar las columnas están más llenas que eso, esto puede conducir al sort operaciones que se derraman en tempdb .
En su caso, si su varchar las columnas se declaran como 8000 bytes pero en realidad tiene un contenido mucho menor que su consulta se le asignará memoria que no requiere, lo que obviamente es ineficiente y puede generar esperas para las concesiones de memoria.
Esto se cubre en la Parte 2 de SQL Workshops Webcast 1 descargable desde aquí o vea a continuación.
use tempdb;
CREATE TABLE T(
id INT IDENTITY(1,1) PRIMARY KEY,
number int,
name8000 VARCHAR(8000),
name500 VARCHAR(500))
INSERT INTO T
(number,name8000,name500)
SELECT number, name, name /*<--Same contents in both cols*/
FROM master..spt_values
SELECT id,name500
FROM T
ORDER BY number
SELECT id,name8000
FROM T
ORDER BY number