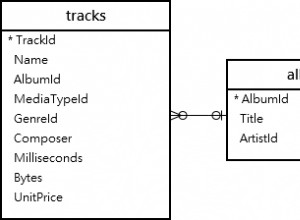
-
No debe actualizar 10k filas en un conjunto a menos que esté seguro de que la operación está obteniendo bloqueos de página (debido a que varias filas por página forman parte de
UPDATE) operación). El problema es que la escalada de bloqueo (desde bloqueos de fila o de página a bloqueos de tabla) se produce en 5000 bloqueos . Por lo tanto, lo más seguro es mantenerlo justo por debajo de 5000, en caso de que la operación utilice bloqueos de fila. -
No deberías no utilice SET ROWCOUNT para limitar el número de filas que se modificarán. Aquí hay dos problemas:
-
Ha quedado en desuso desde que se lanzó SQL Server 2005 (hace 11 años):
El uso de SET ROWCOUNT no afectará las instrucciones DELETE, INSERT y UPDATE en una versión futura de SQL Server. Evite usar SET ROWCOUNT con declaraciones DELETE, INSERT y UPDATE en nuevos trabajos de desarrollo y planee modificar las aplicaciones que actualmente lo usan. Para un comportamiento similar, use la sintaxis TOP
-
Puede afectar más que solo la declaración con la que está tratando:
Establecer la opción SET ROWCOUNT hace que la mayoría de las instrucciones Transact-SQL dejen de procesarse cuando se han visto afectadas por el número especificado de filas. Esto incluye disparadores. La opción ROWCOUNT no afecta a los cursores dinámicos, pero limita el conjunto de filas de cursores insensibles y de conjunto de claves. Esta opción debe usarse con precaución.
En su lugar, use el
TOP ()cláusula. -
-
No tiene sentido tener una transacción explícita aquí. Complica el código y no tiene manejo para un
ROLLBACK, que ni siquiera es necesario ya que cada declaración es su propia transacción (es decir, confirmación automática). -
Suponiendo que encuentre una razón para mantener la transacción explícita, entonces no tiene un
TRY/CATCHestructura. Consulte mi respuesta en DBA.StackExchange paraTRY/CATCHplantilla que maneja transacciones:¿Estamos obligados a manejar la transacción en el código C#, así como en el procedimiento de la tienda?
Sospecho que el verdadero WHERE La cláusula no se muestra en el código de ejemplo en la Pregunta, por lo que simplemente confiando en lo que se ha mostrado, mejor modelo sería:
DECLARE @Rows INT,
@BatchSize INT; -- keep below 5000 to be safe
SET @BatchSize = 2000;
SET @Rows = @BatchSize; -- initialize just to enter the loop
BEGIN TRY
WHILE (@Rows = @BatchSize)
BEGIN
UPDATE TOP (@BatchSize) tab
SET tab.Value = 'abc1'
FROM TableName tab
WHERE tab.Parameter1 = 'abc'
AND tab.Parameter2 = 123
AND tab.Value <> 'abc1' COLLATE Latin1_General_100_BIN2;
-- Use a binary Collation (ending in _BIN2, not _BIN) to make sure
-- that you don't skip differences that compare the same due to
-- insensitivity of case, accent, etc, or linguistic equivalence.
SET @Rows = @@ROWCOUNT;
END;
END TRY
BEGIN CATCH
RAISERROR(stuff);
RETURN;
END CATCH;
Probando @Rows contra @BatchSize , puedes evitar ese UPDATE final consulta (en la mayoría de los casos) porque el conjunto final suele ser un número de filas menor que @BatchSize , en cuyo caso sabemos que no hay más para procesar (que es lo que ve en el resultado que se muestra en su respuesta). Solo en aquellos casos en los que el conjunto final de filas sea igual a @BatchSize ejecutará este código una UPDATE final afectando a 0 filas.
También agregué una condición a WHERE cláusula para evitar que las filas que ya se han actualizado se vuelvan a actualizar.
NOTA SOBRE EL RENDIMIENTO
Hice hincapié en "mejor" arriba (como en "esto es un mejor model") porque tiene varias mejoras con respecto al código original del O.P. y funciona bien en muchos casos, pero no es perfecto para todos los casos. Para tablas de al menos cierto tamaño (que varía debido a varios factores, así que no puedo) t ser más específico), el rendimiento se degradará ya que hay menos filas para arreglar si:
- no hay un índice para respaldar la consulta, o
- hay un índice, pero al menos una columna en
WHEREcláusula es un tipo de datos de cadena que no utiliza una intercalación binaria, por lo tanto, unCOLLATELa cláusula se agrega a la consulta aquí para forzar la intercalación binaria, y al hacerlo invalida el índice (para esta consulta en particular).
Esta es la situación que encontró @mikesigs, por lo que requiere un enfoque diferente. El método actualizado copia los ID de todas las filas que se actualizarán en una tabla temporal, luego usa esa tabla temporal para INNER JOIN a la tabla que se actualiza en la(s) columna(s) de clave de índice agrupado. (Es importante capturar y unirse en el índice agrupado columnas, sean o no las columnas de la clave principal).
Consulte la respuesta de @mikesigs a continuación para obtener más detalles. El enfoque que se muestra en esa respuesta es un patrón muy efectivo que yo mismo he usado en muchas ocasiones. Los únicos cambios que haría son:
- Cree explícitamente el
#targetIdstable en lugar de usarSELECT INTO... - Para
#targetIdstabla, declare una clave primaria agrupada en la(s) columna(s). - Para el
#batchIdstabla, declare una clave primaria agrupada en la(s) columna(s). - Para insertar en
#targetIds, useINSERT INTO #targetIds (column_name(s)) SELECTy eliminar elORDER BYya que es innecesario.
Por lo tanto, si no tiene un índice que pueda usarse para esta operación y no puede crear temporalmente uno que realmente funcione (un índice filtrado podría funcionar, dependiendo de su WHERE cláusula para UPDATE consulta), luego intente el enfoque que se muestra en la respuesta de @mikesigs (y si usa esa solución, vote a favor).