Captura de pantalla n.°1 muestra algunos puntos para distinguir entre Merge Join transformation y Lookup transformation .
Con respecto a la búsqueda:
Si desea encontrar filas que coincidan en la fuente 2 en función de la entrada de la fuente 1 y si sabe que solo habrá una coincidencia para cada fila de entrada, le sugiero que utilice la operación de búsqueda. Un ejemplo sería usted OrderDetails y desea encontrar el Order Id coincidente y Customer Number , entonces Lookup es una mejor opción.
Respecto a la unión por fusión:
Si desea realizar uniones como obtener todas las direcciones (casa, trabajo, otro) de Address tabla para un Cliente dado en el Customer entonces tienes que ir con Merge Join porque el cliente puede tener 1 o más direcciones asociadas con ellos.
Un ejemplo para comparar:
Aquí hay un escenario para demostrar las diferencias de rendimiento entre Merge Join y Lookup . Los datos utilizados aquí son una unión uno a uno, que es el único escenario común entre ellos para comparar.
-
Tengo tres tablas llamadas
dbo.ItemPriceInfo,dbo.ItemDiscountInfoydbo.ItemAmount. Los scripts para crear estas tablas se proporcionan en la sección de scripts SQL. -
Tablas
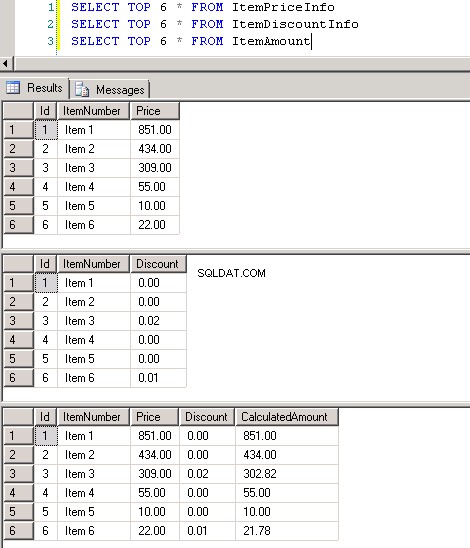
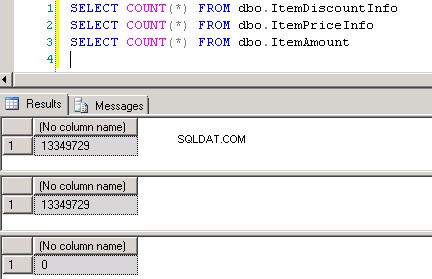
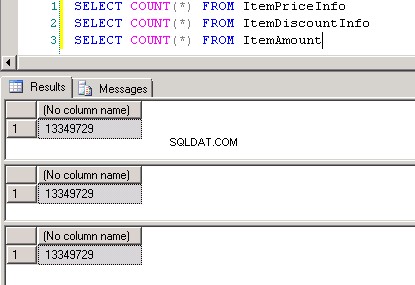
dbo.ItemPriceInfoydbo.ItemDiscountInfoambos tienen 13.349.729 filas. Ambas tablas tienen ItemNumber como columna común. ItemPriceInfo tiene información de precios y ItemDiscountInfo tiene información de descuentos. Captura de pantalla n.º 2 muestra el recuento de filas en cada una de estas tablas. Captura de pantalla n.º 3 muestra las 6 filas principales para dar una idea de los datos presentes en las tablas. -
Creé dos paquetes SSIS para comparar el rendimiento de las transformaciones Merge Join y Lookup. Ambos paquetes deben tomar la información de las tablas
dbo.ItemPriceInfoydbo.ItemDiscountInfo, calcule la cantidad total y guárdela en la tabladbo.ItemAmount. -
Primer paquete usado
Merge Jointransformación y dentro de eso usó INNER JOIN para combinar los datos. Capturas de pantalla n.º 4 y #5 mostrar la ejecución del paquete de muestra y la duración de la ejecución. Tomó05minutos14segundos719milisegundos para ejecutar el paquete basado en la transformación Merge Join. -
Segundo paquete usado
Lookuptransformación con Caché completa (que es la configuración predeterminada). capturas de pantalla #6 y #7 mostrar la ejecución del paquete de muestra y la duración de la ejecución. Tomó11minutos03segundos610milisegundos para ejecutar el paquete basado en la transformación de búsqueda. Es posible que encuentre el mensaje de advertencia Información:The buffer manager has allocated nnnnn bytes, even though the memory pressure has been detected and repeated attempts to swap buffers have failed.Aquí hay un enlace que habla de cómo calcular el tamaño de caché de búsqueda. Durante la ejecución de este paquete, aunque la tarea de flujo de datos se completó más rápido, la limpieza de la canalización llevó mucho tiempo. -
Esto no significa que la transformación de búsqueda es mala. Es solo que tiene que ser usado sabiamente. Lo uso con bastante frecuencia en mis proyectos, pero nuevamente no trato con más de 10 millones de filas para buscar todos los días. Por lo general, mis trabajos manejan entre 2 y 3 millones de filas y para eso el rendimiento es realmente bueno. Hasta 10 millones de filas, ambos funcionaron igual de bien. La mayoría de las veces lo que he notado es que el cuello de botella resulta ser el componente de destino en lugar de las transformaciones. Puede superar eso teniendo múltiples destinos. Aquí es un ejemplo que muestra la implementación de múltiples destinos.
-
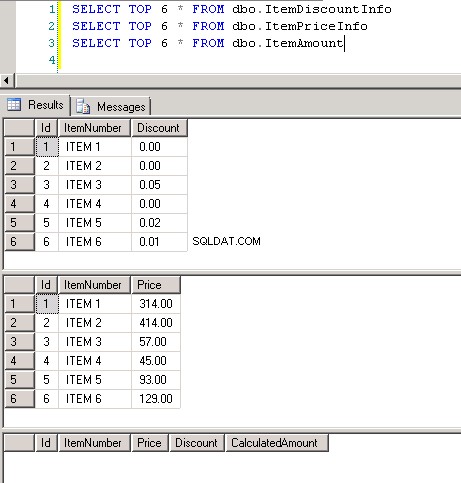
Captura de pantalla n.º 8 muestra el recuento de registros en las tres tablas. Captura de pantalla n.°9 muestra los 6 registros principales en cada una de las tablas.
Espero que ayude.
Secuencias de comandos SQL:
CREATE TABLE [dbo].[ItemAmount](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
[CalculatedAmount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemAmount] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemDiscountInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemDiscountInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemPriceInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemPriceInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
Captura de pantalla n.º 1:

Captura de pantalla n.º 2:
Captura de pantalla n.º 3:
Captura de pantalla n.º 4:
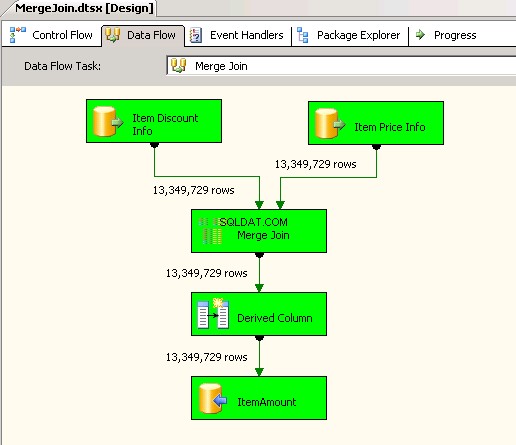
Captura de pantalla n.º 5:

Captura de pantalla n.º 6:
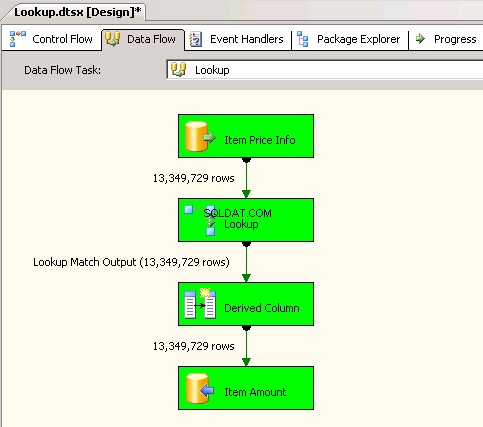
Captura de pantalla n.º 7:
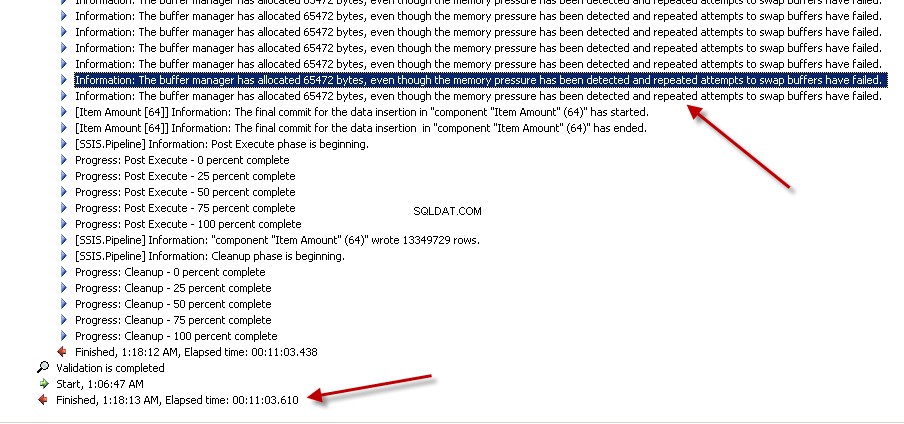
Captura de pantalla n.º 8:
Captura de pantalla n.º 9: