SQL Server 2014 CTP1 ha estado disponible durante algunas semanas, y es probable que haya visto bastante prensa sobre las tablas optimizadas para memoria y los índices de almacén de columnas actualizables. Si bien estos son ciertamente dignos de atención, en esta publicación quería explorar la nueva mejora del paralelismo SELECT … INTO. La mejora es uno de esos cambios listos para usar que, por su apariencia, no requerirán cambios significativos en el código para comenzar a beneficiarse de ella. Mis exploraciones se realizaron con la versión Microsoft SQL Server 2014 (CTP1) – 11.0.9120.5 (X64), Enterprise Evaluation Edition.
SELECCIÓN paralela... EN
SQL Server 2014 presenta SELECT ... INTO habilitado para paralelo para las bases de datos y para probar esta función, utilicé la base de datos AdventureWorksDW2012 y una versión de la tabla FactInternetSales que tenía 61 847 552 filas (yo fui responsable de agregar esas filas; no vienen con la base de datos de manera predeterminada).
Debido a que esta función, a partir de CTP1, requiere el nivel de compatibilidad de la base de datos 110, con fines de prueba configuré la base de datos en el nivel de compatibilidad 100 y ejecuté la siguiente consulta para mi primera prueba:
SELECT [ProductKey],
[OrderDateKey],
[DueDateKey],
[ShipDateKey],
[CustomerKey],
[PromotionKey],
[CurrencyKey],
[SalesTerritoryKey],
[SalesOrderNumber],
[SalesOrderLineNumber],
[RevisionNumber],
[OrderQuantity],
[UnitPrice],
[ExtendedAmount],
[UnitPriceDiscountPct],
[DiscountAmount],
[ProductStandardCost],
[TotalProductCost],
[SalesAmount],
[TaxAmt],
[Freight],
[CarrierTrackingNumber],
[CustomerPONumber],
[OrderDate],
[DueDate],
[ShipDate]
INTO dbo.FactInternetSales_V2
FROM dbo.FactInternetSales; La duración de la ejecución de la consulta fue de 3 minutos y 19 segundos en mi máquina virtual de prueba y el plan de ejecución de la consulta real producido fue el siguiente:

SQL Server usó un plan en serie, como esperaba. Observe también que mi tabla tenía un índice de almacén de columnas no agrupado que se analizó (creé este índice de almacén de columnas no agrupado para usarlo con otras pruebas, pero también le mostraré el plan de ejecución de consultas del índice de almacén de columnas agrupado más adelante). El plan no usaba paralelismo y Columnstore Index Scan usaba el modo de ejecución de fila en lugar del modo de ejecución por lotes.
A continuación, modifiqué el nivel de compatibilidad de la base de datos (y tenga en cuenta que todavía no hay un nivel de compatibilidad de SQL Server 2014 en CTP1):
USE [master]; GO ALTER DATABASE [AdventureWorksDW2012] SET COMPATIBILITY_LEVEL = 110; GO
Solté la tabla FactInternetSales_V2 y luego volví a ejecutar mi SELECT ... INTO original operación. Esta vez, la duración de la ejecución de la consulta fue de 1 minuto y 7 segundos y el plan real de ejecución de la consulta fue el siguiente:
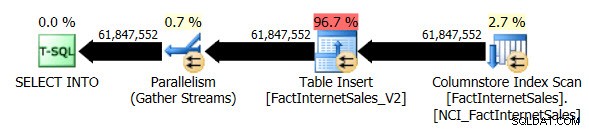
Ahora tenemos un plan paralelo y el único cambio que tuve que hacer fue el nivel de compatibilidad de la base de datos para AdventureWorksDW2012. Mi VM de prueba tiene cuatro vCPU asignadas y el plan de ejecución de consultas distribuyó filas en cuatro subprocesos:

El escaneo de índice de almacén de columnas no agrupado, aunque usaba paralelismo, no usaba el modo de ejecución por lotes. En su lugar, utilizó el modo de ejecución de filas.
Aquí hay una tabla para mostrar los resultados de las pruebas hasta el momento:
| Tipo de escaneo | Nivel de compatibilidad | SELECCIÓN paralela... EN | Modo de ejecución | Duración |
|---|---|---|---|---|
| Escaneo de índice de almacén de columnas no agrupado | 100 | No | Fila | 3:19 |
| Escaneo de índice de almacén de columnas no agrupado | 110 | Sí | Fila | 1:07 |
Entonces, como siguiente prueba, eliminé el índice del almacén de columnas no agrupado y volví a ejecutar SELECT ... INTO consulta usando el nivel de compatibilidad de la base de datos 100 y 110.
La prueba del nivel de compatibilidad 100 tardó 5 minutos y 44 segundos en ejecutarse y se generó el siguiente plan:
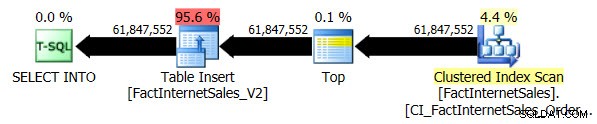
El análisis de índice agrupado en serie tardó 2 minutos y 25 segundos más que el análisis de índice de almacén de columnas no agrupado en serie.
Con el nivel de compatibilidad 110, la consulta tardó 1 minuto y 55 segundos en ejecutarse y se generó el siguiente plan:

De forma similar a la prueba de análisis de índice de almacén de columnas paralelo no agrupado, el análisis de índice agrupado paralelo distribuyó filas en cuatro subprocesos:
La siguiente tabla resume estas dos pruebas mencionadas:
| Tipo de escaneo | Nivel de compatibilidad | SELECCIÓN paralela... EN | Modo de ejecución | Duración |
|---|---|---|---|---|
| Escaneo de índice agrupado | 100 | No | Fila (N/A) | 5:44 |
| Escaneo de índice agrupado | 110 | Sí | Fila (N/A) | 1:55 |
Entonces me pregunté sobre el rendimiento de un índice de almacén de columnas agrupado (nuevo en SQL Server 2014), así que eliminé los índices existentes y creé un índice de almacén de columnas agrupado en la tabla FactInternetSales. También tuve que descartar las ocho restricciones de clave externa diferentes definidas en la tabla antes de poder crear el índice de almacén de columnas agrupado.
La discusión se vuelve algo académica, ya que estoy comparando SELECT ... INTO rendimiento en niveles de compatibilidad de base de datos que no ofrecían índices de almacén de columnas agrupados en primer lugar, ni las pruebas anteriores para índices de almacén de columnas no agrupados en el nivel de compatibilidad de base de datos 100, y sin embargo, es interesante ver y comparar las características de rendimiento general.
CREATE CLUSTERED COLUMNSTORE INDEX [CCSI_FactInternetSales] ON [dbo].[FactInternetSales] WITH (DROP_EXISTING = OFF); GO
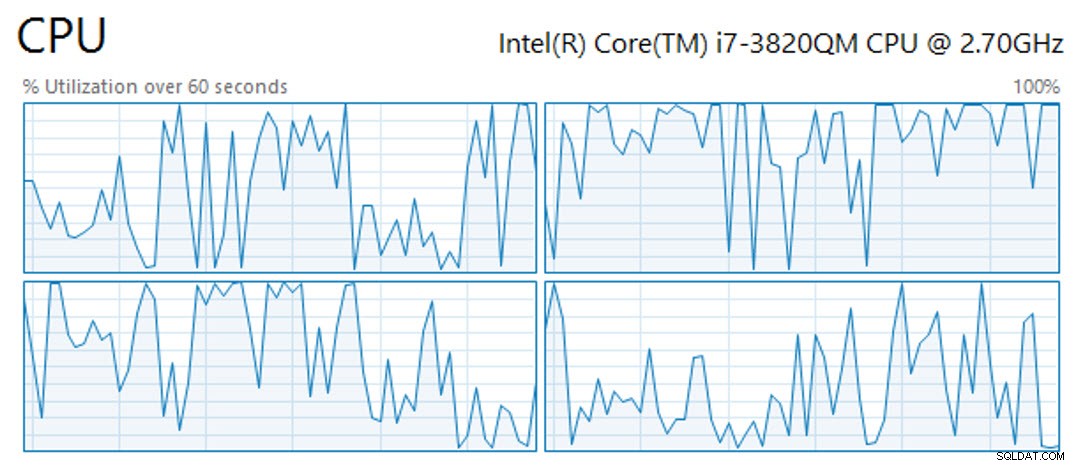
Aparte, la operación para crear el índice de almacén de columnas agrupado en una tabla de 61 847 552 millones de filas tomó 11 minutos y 25 segundos con cuatro CPU virtuales disponibles (de las cuales la operación las aprovechó todas), 4 GB de RAM y almacenamiento de invitado virtual en SSD OCZ Vertex. Durante ese tiempo, las CPU no estuvieron vinculadas todo el tiempo, sino que mostraron picos y valles (una muestra de 60 segundos de actividad de la CPU se muestra a continuación):
Después de que se creó el índice de almacén de columnas agrupado, volví a ejecutar los dos SELECT ... INTO pruebas La prueba del nivel de compatibilidad 100 tardó 3 minutos y 22 segundos en ejecutarse, y el plan era uno en serie como se esperaba (estoy mostrando la versión del plan de SQL Server Management Studio desde el escaneo de índice de almacén de columnas agrupado, a partir de SQL Server 2014 CTP1 , aún no está completamente reconocido por Plan Explorer):

A continuación, cambié el nivel de compatibilidad de la base de datos a 110 y volví a ejecutar la prueba, que esta vez la consulta tomó 1 minuto y 11 segundos y tenía el siguiente plan de ejecución real:

El plan distribuyó las filas en cuatro subprocesos y, al igual que el índice de almacén de columnas no agrupado, el modo de ejecución del análisis del índice de almacén de columnas agrupado fue por fila y no por lotes.
La siguiente tabla resume todas las pruebas dentro de esta publicación (en orden de duración, de menor a mayor):
| Tipo de escaneo | Nivel de compatibilidad | SELECCIÓN paralela... EN | Modo de ejecución | Duración |
|---|---|---|---|---|
| Escaneo de índice de almacén de columnas no agrupado | 110 | Sí | Fila | 1:07 |
| Exploración del índice de almacén de columnas en clúster | 110 | Sí | Fila | 1:11 |
| Escaneo de índice agrupado | 110 | Sí | Fila (N/A) | 1:55 |
| Escaneo de índice de almacén de columnas no agrupado | 100 | No | Fila | 3:19 |
| Exploración del índice de almacén de columnas en clúster | 100 | No | Fila | 3:22 |
| Escaneo de índice agrupado | 100 | No | Fila (N/A) | 5:44 |
Algunas observaciones:
- No estoy seguro de si la diferencia entre
SELECT ... INTOparalelo la operación en un índice de almacén de columnas no agrupado frente a un índice de almacén de columnas agrupado es estadísticamente significativa. Necesitaría hacer más pruebas, pero creo que esperaría para realizarlas hasta RTM. - Puedo decir con seguridad que el paralelo
SELECT ... INTOsuperó significativamente a los equivalentes en serie en un índice agrupado, almacén de columnas no agrupado y pruebas de índice de almacén de columnas agrupado.
Vale la pena mencionar que estos resultados son para una versión CTP del producto, y mis pruebas deben verse como algo que podría cambiar en el comportamiento de RTM, por lo que estaba menos interesado en las duraciones independientes en comparación con la comparación de esas duraciones entre serie y paralelo. condiciones.
Algunas características de rendimiento requieren una refactorización significativa, pero para SELECT ... INTO mejora, todo lo que tenía que hacer era aumentar el nivel de compatibilidad de la base de datos para comenzar a ver los beneficios, lo que definitivamente es algo que aprecio.