Las bases de datos de series temporales, como sugiere su nombre, están diseñadas para almacenar datos que cambian con el tiempo. Puede ser cualquier tipo de datos recopilados a lo largo del tiempo. Pueden ser métricas recopiladas de algunos sistemas y, de hecho, todos los sistemas de tendencias son ejemplos de datos de series temporales.
Tenemos diferentes tipos de bases de datos de series temporales, ¿cuáles deberíamos usar?
En este blog, veremos cuáles son las principales diferencias entre dos de las principales opciones, TimescaleDB e InfluxDB.
InfluxDB
InfluxDB ha sido creado por InfluxData. Es una base de datos de serie temporal NoSQL personalizada y de código abierto escrita en Go. El almacén de datos proporciona un lenguaje similar a SQL para consultar los datos, llamado InfluxQL, que facilita la integración de los desarrolladores en sus aplicaciones. También tiene un nuevo lenguaje de consulta personalizado llamado Flux, este lenguaje puede facilitar algunas tareas, pero siempre hay una curva de aprendizaje cuando se adopta un lenguaje de consulta personalizado.
Este es un ejemplo de consulta Flux:
from(db:"testing")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "cpu")
|> exponentialMovingAverage()En esta base de datos, cada medición tiene una marca de tiempo y un conjunto asociado de etiquetas y un conjunto de campos. El campo representa los valores reales de lectura de la medición, mientras que la etiqueta representa los metadatos para describir las mediciones. Los tipos de datos de campo están limitados a flotantes, enteros, cadenas y booleanos, y no se pueden cambiar sin volver a escribir los datos. Los valores de las etiquetas están indexados. Se representan como cadenas y no se pueden actualizar.
InfluxDB es bastante fácil de comenzar, ya que no tiene que preocuparse por crear esquemas o índices. Sin embargo, es bastante rígido y limitado, sin capacidad para crear índices adicionales, índices en campos continuos, actualizar metadatos después del hecho, hacer cumplir la validación de datos, etc.
No es sin esquema. Hay un esquema subyacente que se crea automáticamente a partir de los datos de entrada.
InfluxDB tiene que implementar desde cero varias herramientas para la tolerancia a fallas, como replicación, alta disponibilidad y copia de seguridad/restauración, y es responsable de su confiabilidad en el disco. Estamos limitados a usar estas herramientas y muchas de estas funciones, como HA, solo están disponibles en la versión empresarial.
La herramienta de copia de seguridad InfluxDB puede realizar una copia de seguridad completa o incremental, y se puede utilizar para la recuperación de un punto en el tiempo.
InfluxDB también ofrece una compresión en disco significativamente mejor que PostgreSQL y TimescaleDB.
Base de datos de escala de tiempo
TimescaleDB es una base de datos de series temporales de código abierto optimizada para una ingesta rápida y consultas complejas que admite SQL completo. Se basa en PostgreSQL y ofrece lo mejor de los mundos NoSQL y relacional para datos de series temporales.
Este es un ejemplo de consulta de TimescaleDB:
SELECT time,
exponential_moving_average(value, 0.5) OVER (ORDER BY time)
FROM testing
WHERE measurement = cpu and time > now() - '1 hour';TimescaleDB, como extensión de PostgreSQL, es una base de datos relacional. Esto permite tener una curva de aprendizaje corta para nuevos usuarios y heredar herramientas como pg_dump o pg_backup para realizar copias de seguridad y herramientas de alta disponibilidad, lo que es una ventaja frente a otras bases de datos de series temporales. También es compatible con la replicación de transmisión como método principal de replicación, que se puede usar en una configuración de alta disponibilidad. En términos de conmutación por error y copias de seguridad, puede automatizar este proceso utilizando un sistema externo como ClusterControl.
En TimescaleDB, cada medición de serie temporal se registra en su propia fila, con un campo de tiempo seguido de cualquier número de otros campos, que pueden ser flotantes, enteros, cadenas, booleanos, matrices, blobs JSON, dimensiones geoespaciales, fecha/hora/ marcas de tiempo, divisas, datos binarios y más.
Puede crear índices en cualquier campo (índices estándar) o campos múltiples (índices compuestos), o en expresiones como funciones, o incluso limitar un índice a un subconjunto de filas (índice parcial). Cualquiera de estos campos se puede utilizar como clave externa para las tablas secundarias, que luego pueden almacenar metadatos adicionales.
De esta forma, debe elegir un esquema y decidir qué índices necesitará para su sistema.
Rendimiento
Si hablamos de rendimiento, podemos consultar el gran blog de comparación de TimescaleDB. Allí tiene una comparación detallada del rendimiento entre ambas bases de datos con gráficos y métricas. Veamos algunas de las informaciones más importantes de este blog.
Inserciones
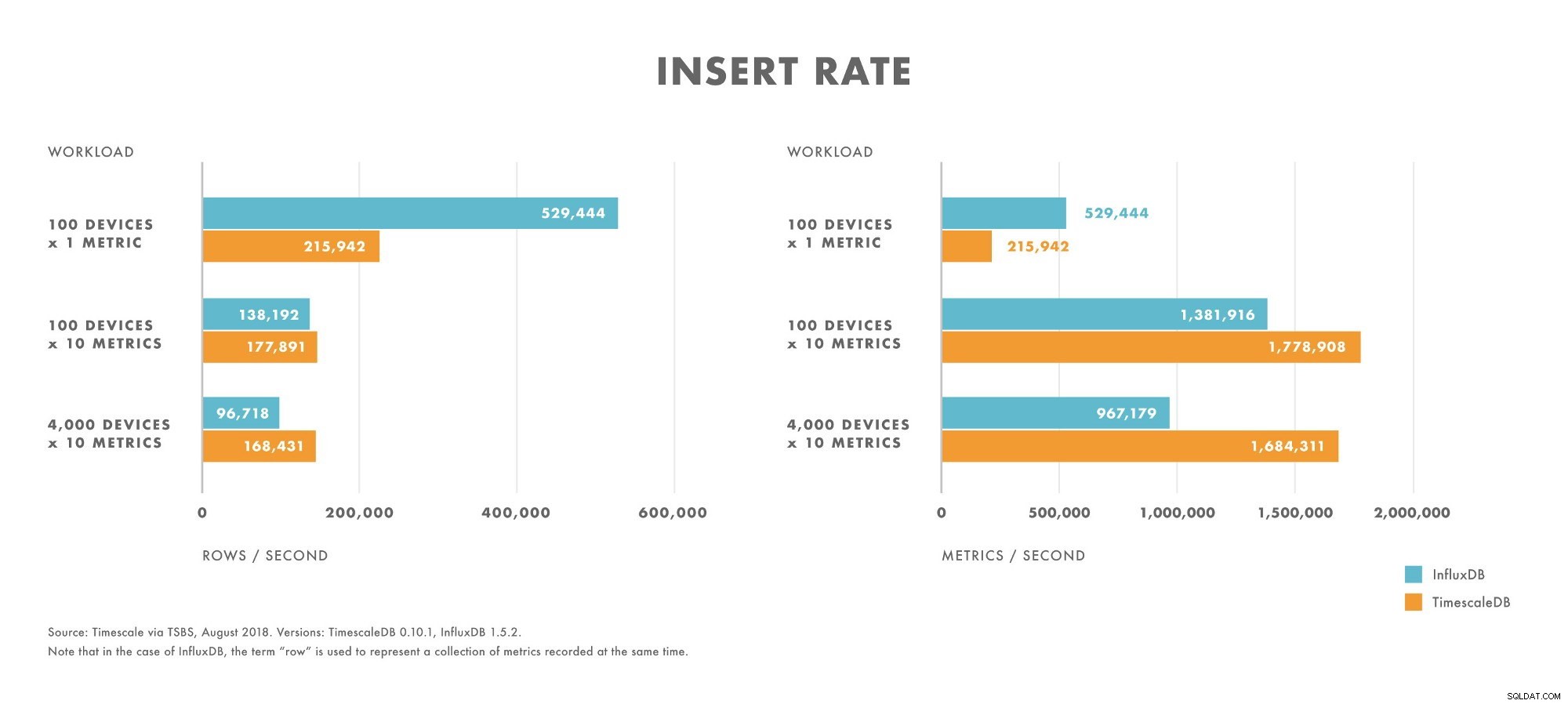
- Para cargas de trabajo con cardinalidad muy baja (por ejemplo, 100 dispositivos), InfluxDB supera a TimescaleDB.
- A medida que aumenta la cardinalidad, el rendimiento de inserción de InfluxDB cae más rápido que en TimescaleDB.
- Para cargas de trabajo con cardinalidad de moderada a alta (por ejemplo, 100 dispositivos que envían 10 métricas), TimescaleDB supera a InfluxDB.

Latencia de lectura
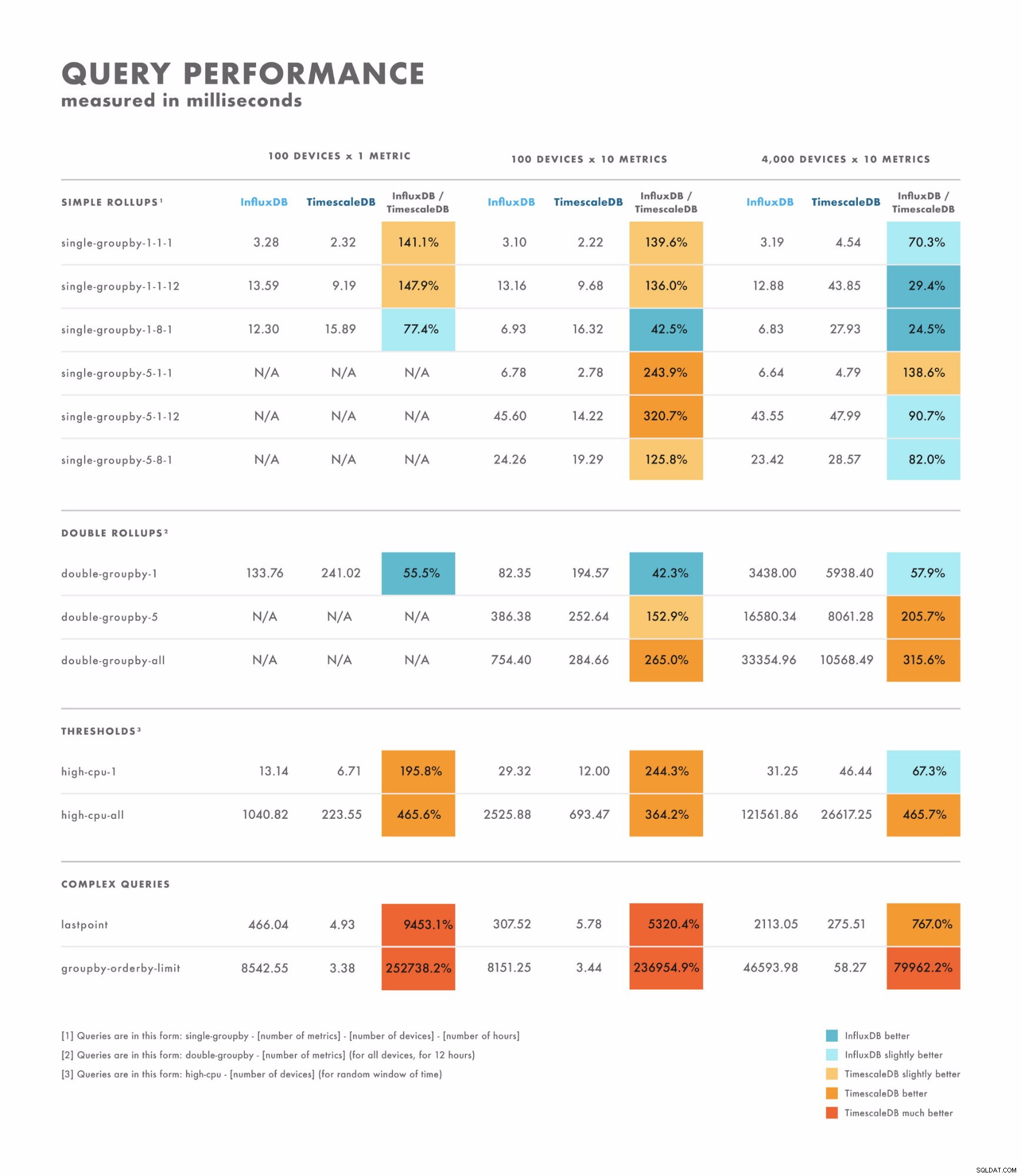
- Para consultas simples, los resultados varían bastante:hay algunas en las que una base de datos es claramente mejor que la otra, mientras que otras dependen de la cardinalidad de su conjunto de datos. La diferencia aquí suele estar en el rango de milisegundos de un solo dígito a dos dígitos.
- Para consultas complejas, TimescaleDB supera ampliamente a InfluxDB y admite una variedad más amplia de tipos de consultas. La diferencia aquí suele estar en el rango de segundos a decenas de segundos.
- Con eso en mente, la mejor manera de realizar pruebas correctamente es compararlas con las consultas que planea ejecutar.
Problemas de estabilidad
- InfluxDB tiene problemas de estabilidad y rendimiento en cardinalidades altas (más de 100 000).
Conclusión
Si sus datos encajan en el modelo de datos de InfluxDB y no espera cambiar en el futuro, entonces debería considerar usar InfluxDB, ya que es más fácil comenzar con este modelo y, como la mayoría de las bases de datos que usan un enfoque orientado a columnas, ofrece mejor compresión en disco que PostgreSQL y TimescaleDB.
Sin embargo, el modelo relacional es más versátil y ofrece más funcionalidad, flexibilidad y control que el modelo InfluxDB. Esto es especialmente importante a medida que su aplicación evoluciona. Y cuando planifique su sistema, debe considerar sus necesidades actuales y futuras.
En este blog, pudimos ver una breve comparación entre TimescaleDB e InfluxDB, y podríamos decir que TimescaleDB como una extensión de PostgreSQL, parece bastante maduro y rico en funciones, ya que hereda mucho de PostgreSQL. Pero puede tomar su propia decisión en función de los pros y los contras mencionados anteriormente en este blog y asegurarse de comparar su propia carga de trabajo. ¡Buena suerte en este nuevo mundo de bases de datos de series temporales!