Hoy en día, la replicación es un hecho en un entorno tolerante a fallas y de alta disponibilidad para prácticamente cualquier tecnología de base de datos que esté utilizando. Es un tema que hemos visto una y otra vez, pero que nunca pasa de moda.
Si usa TimescaleDB, el tipo de replicación más común es la replicación de transmisión, pero ¿cómo funciona?
En este blog, revisaremos algunos conceptos relacionados con la replicación y nos centraremos en la replicación de transmisión para TimescaleDB, que es una funcionalidad heredada del motor PostgreSQL subyacente. Luego, veremos cómo ClusterControl puede ayudarnos a configurarlo.
Por lo tanto, la replicación de transmisión se basa en enviar los registros WAL y aplicarlos al servidor en espera. Entonces, primero, veamos qué es WAL.
WAL
Write Ahead Log (WAL) es un método estándar para garantizar la integridad de los datos, se habilita automáticamente de forma predeterminada.
Los WAL son los registros REDO en TimescaleDB. Pero, ¿qué son los registros REDO?
Los registros REDO contienen todos los cambios que se realizaron en la base de datos y se utilizan para la replicación, la recuperación, la copia de seguridad en línea y la recuperación de un punto en el tiempo (PITR). Cualquier cambio que no se haya aplicado a las páginas de datos se puede rehacer desde los registros REDO.
El uso de WAL da como resultado una cantidad significativamente menor de escrituras en disco, porque solo el archivo de registro debe vaciarse en el disco para garantizar que se confirme una transacción, en lugar de cada archivo de datos modificado por la transacción.
Un registro WAL especificará, bit a bit, los cambios realizados en los datos. Cada registro WAL se adjuntará a un archivo WAL. La posición de inserción es un Número de secuencia de registro (LSN) que es un desplazamiento de bytes en los registros, que aumenta con cada nuevo registro.
Los WAL se almacenan en el directorio pg_wal, en el directorio de datos. Estos archivos tienen un tamaño predeterminado de 16 MB (el tamaño se puede cambiar alterando la opción de configuración --with-wal-segsize al construir el servidor). Tienen un nombre incremental único, en el siguiente formato:"00000001 00000000 00000000".
El número de archivos WAL contenidos en pg_wal dependerá del valor asignado a los parámetros min_wal_size y max_wal_size en el archivo de configuración postgresql.conf.
Un parámetro que debemos configurar al configurar todas nuestras instalaciones de TimescaleDB es el wal_level. Determina cuánta información se escribe en el WAL. El valor predeterminado es mínimo, que escribe solo la información necesaria para recuperarse de un bloqueo o apagado inmediato. El archivo agrega el registro requerido para el archivo WAL; hot_standby agrega además la información requerida para ejecutar consultas de solo lectura en un servidor en espera; y, finalmente, lógico agrega la información necesaria para soportar la decodificación lógica. Este parámetro requiere un reinicio, por lo que puede ser difícil cambiarlo al ejecutar bases de datos de producción si lo hemos olvidado.
Replicación de transmisión
La replicación de transmisión se basa en el método de trasvase de registros. Los registros WAL se mueven directamente de un servidor de base de datos a otro para ser aplicados. Podemos decir que es un PITR continuo.
Esta transferencia se realiza de dos maneras diferentes, transfiriendo registros WAL de un archivo (segmento WAL) a la vez (envío de registros basado en archivos) y transfiriendo registros WAL (un archivo WAL se compone de registros WAL) sobre la marcha (basado en registros). envío de registros), entre un servidor maestro y uno o varios servidores esclavos, sin esperar a que se llene el archivo WAL.
En la práctica, un proceso llamado receptor WAL, que se ejecuta en el servidor esclavo, se conectará al servidor maestro mediante una conexión TCP/IP. En el servidor maestro existe otro proceso, llamado WAL sender, y se encarga de enviar los registros WAL al servidor esclavo a medida que ocurren.
La replicación de transmisión se puede representar de la siguiente manera:
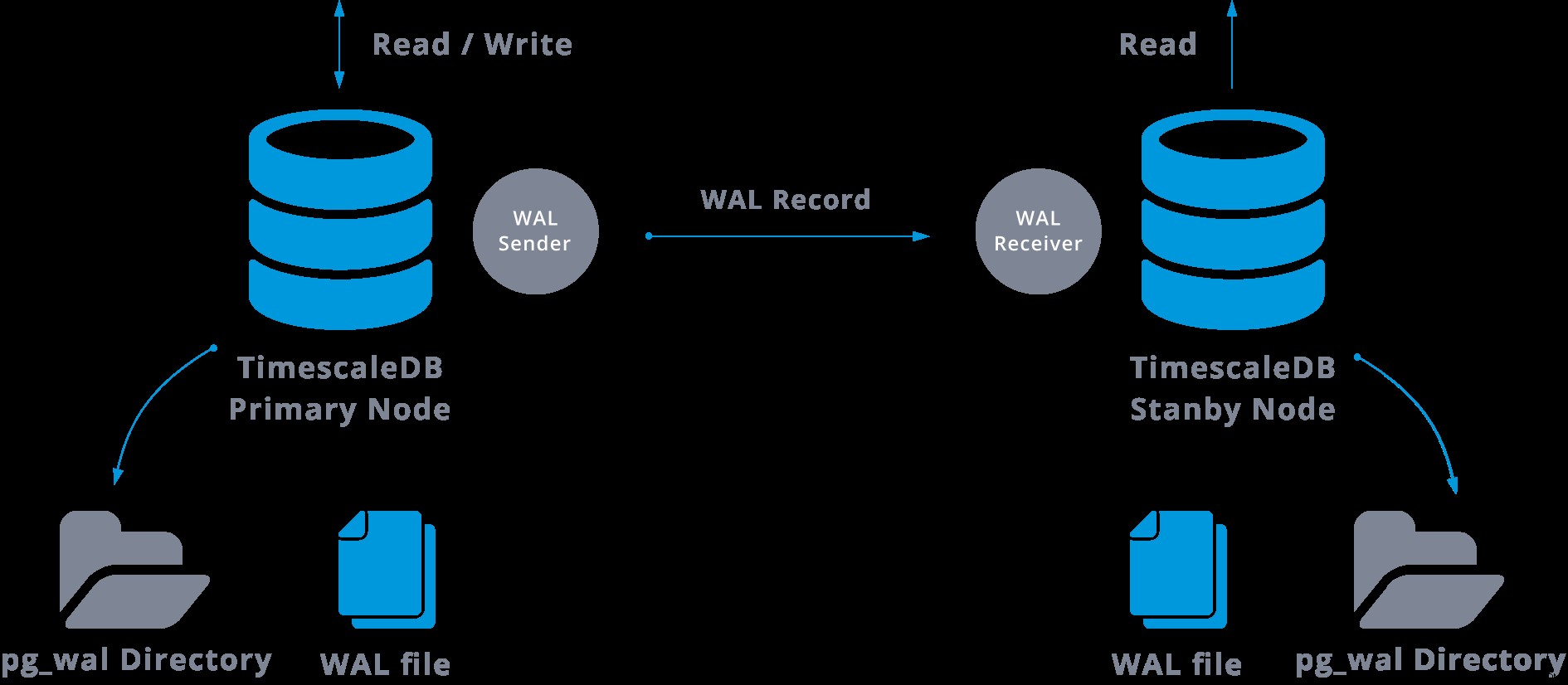
Al observar el diagrama anterior, podemos pensar, ¿qué sucede cuando falla la comunicación entre el remitente de WAL y el receptor de WAL?
Al configurar la replicación de transmisión, tenemos la opción de habilitar el archivo WAL.
En realidad, este paso no es obligatorio, pero es extremadamente importante para una configuración de replicación sólida, ya que es necesario evitar que el servidor principal recicle archivos WAL antiguos que aún no se han aplicado al esclavo. Si esto ocurre, tendremos que volver a crear la réplica desde cero.
Al configurar la replicación con archivado continuo, comenzamos desde una copia de seguridad y, para alcanzar el estado de sincronización con el maestro, debemos aplicar todos los cambios alojados en el WAL que ocurrieron después de la copia de seguridad. Durante este proceso, el standby primero restaurará todos los WAL disponibles en la ubicación del archivo (lo cual se hace llamando a restore_command). El comando de restauración fallará cuando alcancemos el último registro WAL archivado, por lo que después de eso, el modo de espera buscará en el directorio pg_wal para ver si el cambio existe allí (esto se hace para evitar la pérdida de datos cuando los servidores maestros fallan y algunos los cambios que ya se movieron a la réplica y se aplicaron allí aún no se archivaron).
Si eso falla y el registro solicitado no existe allí, comenzará a comunicarse con el maestro a través de la replicación de transmisión.
Cada vez que falla la replicación de transmisión, volverá al paso 1 y restaurará los registros del archivo nuevamente. Este ciclo de recuperación desde el archivo, pg_wal, y a través de la replicación de transmisión continúa hasta que el servidor se detiene o un archivo desencadenante activa la conmutación por error.
Este será un diagrama de dicha configuración:
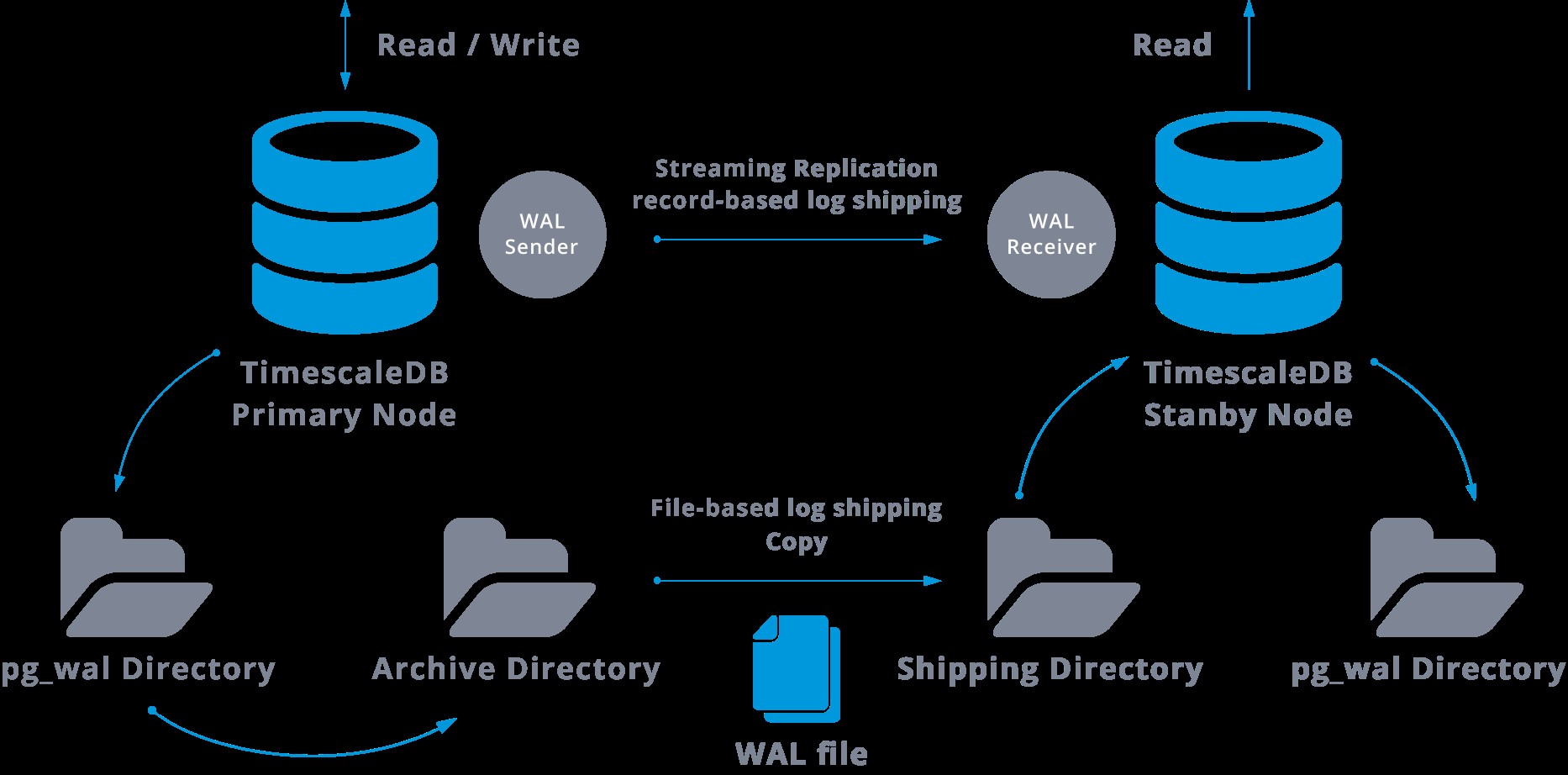
La replicación de transmisión es asíncrona de forma predeterminada, por lo que en algún momento podemos tener algunas transacciones que se pueden confirmar en el maestro y aún no replicar en el servidor de reserva. Esto implica una posible pérdida de datos.
Sin embargo, se supone que este retraso entre la confirmación y el impacto de los cambios en la réplica es realmente pequeño (algunos milisegundos), asumiendo, por supuesto, que el servidor de réplica es lo suficientemente potente como para mantenerse al día con la carga.
Para los casos en los que incluso el riesgo de una pequeña pérdida de datos no es tolerable, podemos utilizar la función de replicación síncrona.
En la replicación síncrona, cada confirmación de una transacción de escritura esperará hasta que se reciba la confirmación de que la confirmación se ha escrito en el registro de escritura anticipada en el disco del servidor primario y en espera.
Este método minimiza la posibilidad de pérdida de datos, ya que para que eso suceda necesitaremos que tanto el maestro como el standby fallen al mismo tiempo.
La desventaja obvia de esta configuración es que aumenta el tiempo de respuesta para cada transacción de escritura, ya que debemos esperar hasta que todas las partes hayan respondido. Entonces, el tiempo para una confirmación es, como mínimo, el viaje de ida y vuelta entre el maestro y la réplica. Las transacciones de solo lectura no se verán afectadas por eso.
Para configurar la replicación síncrona, necesitamos que cada uno de los servidores en espera especifique un nombre_aplicación en la información_conexión_primaria del archivo recovery.conf:información_conferencia_primaria ='...nombre_aplicación=esclavoX' .
También necesitamos especificar la lista de servidores en espera que van a participar en la replicación sincrónica:synchronous_standby_name ='slaveX,slaveY'.
Podemos configurar uno o varios servidores sincrónicos, y este parámetro también especifica qué método (PRIMERO y CUALQUIERA) para elegir los modos de espera sincrónicos de los enumerados.
Para implementar TimescaleDB con configuraciones de replicación de transmisión (sincrónica o asincrónica), podemos usar ClusterControl, como podemos ver aquí.
Una vez que hayamos configurado nuestra replicación y esté en funcionamiento, necesitaremos algunas funciones adicionales para la supervisión y la gestión de copias de seguridad. ClusterControl nos permite monitorear y administrar copias de seguridad/retención de nuestro clúster TimescaleDB desde el mismo lugar sin ninguna herramienta externa.
Cómo configurar la replicación de transmisión en TimescaleDB
La configuración de la replicación de transmisión es una tarea que requiere seguir algunos pasos a fondo. Si desea configurarlo manualmente, puede seguir nuestro blog sobre este tema.
Sin embargo, puede implementar o importar su TimescaleDB actual en ClusterControl y, luego, puede configurar la replicación de transmisión con unos pocos clics. Veamos cómo podemos hacerlo.
Para esta tarea, supondremos que tiene su clúster de TimescaleDB administrado por ClusterControl. Vaya a ClusterControl -> Seleccionar clúster -> Acciones de clúster -> Agregar esclavo de replicación.
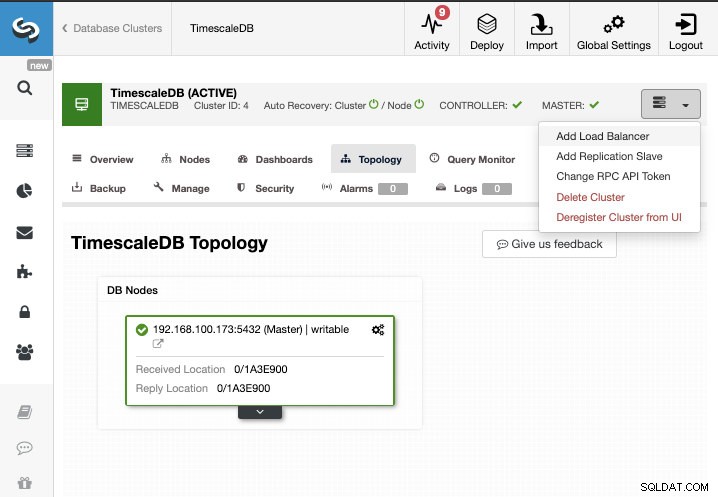
Podemos crear un nuevo esclavo de replicación (en espera) o podemos importar uno existente. En este caso, crearemos uno nuevo.
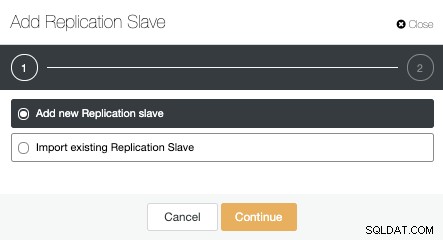
Ahora, debemos seleccionar el nodo maestro, agregar la dirección IP o el nombre de host para el nuevo servidor en espera y el puerto de la base de datos. También podemos especificar si queremos que ClusterControl instale el software y si queremos configurar la replicación de streaming síncrona o asíncrona.
Eso es todo. Solo tenemos que esperar hasta que ClusterControl termine el trabajo. Podemos monitorear el estado desde la sección Actividad.
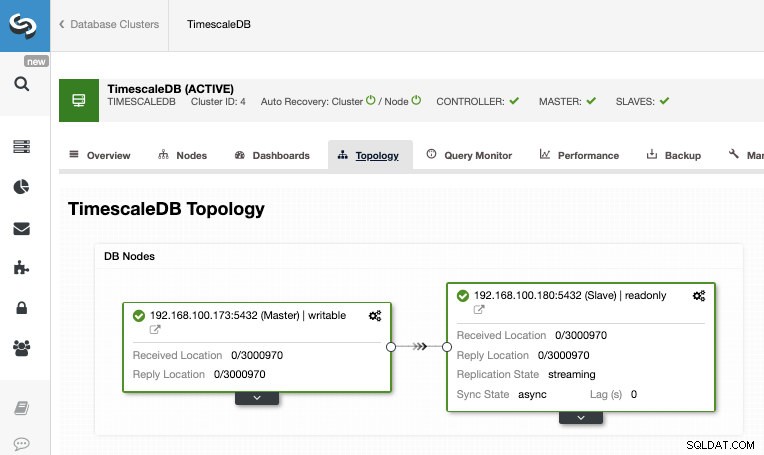
Una vez finalizado el trabajo, deberíamos tener configurada la replicación de transmisión y podemos verificar la nueva topología en la sección Vista de topología de ClusterControl.
Al usar ClusterControl, también puede realizar varias tareas de administración en su TimescaleDB, como respaldo, monitoreo y alerta, conmutación por error automática, agregar nodos, agregar balanceadores de carga y aún más.
Conmutación por error
Como pudimos ver, TimescaleDB utiliza un flujo de registros de escritura anticipada (WAL) para mantener sincronizadas las bases de datos en espera. Si el servidor principal falla, el standby contiene casi todos los datos del servidor principal y puede convertirse rápidamente en el nuevo servidor de base de datos principal. Esto puede ser síncrono o asíncrono y solo se puede hacer para todo el servidor de la base de datos.
Para garantizar de forma eficaz una alta disponibilidad, no basta con tener una arquitectura maestra en espera. También debemos habilitar alguna forma automática de conmutación por error, de modo que si algo falla, podamos tener el menor retraso posible para reanudar la funcionalidad normal.
TimescaleDB no incluye un mecanismo automático de conmutación por error para identificar fallas en la base de datos maestra y notificar al esclavo para que tome posesión, por lo que requerirá un poco de trabajo por parte del DBA. También tendrá un solo servidor en funcionamiento, por lo que se debe volver a crear la arquitectura maestra-en espera, para que volvamos a la misma situación normal que teníamos antes del problema.
ClusterControl incluye una función de conmutación por error automática para TimescaleDB para mejorar el tiempo medio de reparación (MTTR) en su entorno de alta disponibilidad. En caso de falla, ClusterControl promoverá el esclavo más avanzado a maestro y reconfigurará los esclavos restantes para conectarse al nuevo maestro. HAProxy también se puede implementar automáticamente para ofrecer un punto final de base de datos único a las aplicaciones, de modo que no se vean afectadas por un cambio en el servidor maestro.
Limitaciones
Recursos relacionados ClusterControl para TimescaleDB Cómo implementar fácilmente TimescaleDB PostgreSQL Streaming Replication:una inmersión profundaTenemos algunas limitaciones bien conocidas cuando usamos Streaming Replication:
- No podemos replicar en una versión o arquitectura diferente
- No podemos cambiar nada en el servidor en espera
- No tenemos mucha granularidad sobre lo que podemos replicar
Entonces, para superar estas limitaciones, tenemos la función de replicación lógica. Para saber más sobre este tipo de replicación, puedes consultar el siguiente blog.
Conclusión
Una topología maestra en espera tiene muchos usos diferentes, como análisis, copia de seguridad, alta disponibilidad, conmutación por error. En cualquier caso, es necesario comprender cómo funciona la replicación de transmisión en TimescaleDB. También es útil tener un sistema para administrar todo el clúster y brindarle la posibilidad de crear esta topología de una manera fácil. En este blog, vimos cómo lograrlo usando ClusterControl y revisamos algunos conceptos básicos sobre la replicación de transmisión.



