¿Cómo se almacenan todos esos datos de opinión pública? Revisamos un modelo de datos de encuestas de opinión.
Todo el mundo quiere saber lo que piensa el público, desde políticos y empresas hasta personas que quieren saber lo que piensan los demás sobre un tema determinado. Este tipo de trabajo generalmente lo realizan agencias que se especializan en ese tipo de investigación.
Hoy, veremos un modelo de datos que una agencia de este tipo podría usar para almacenar todos los datos de encuestas relevantes, desde preguntas y respuestas predefinidas hasta los comentarios reales. Estos datos se usarían más tarde para crear varios informes. Entonces, comencemos.
Idea
Las encuestas se pueden crear en cualquier lugar. Podrían estar bien planificados e incluir una muestra representativa del público (basada en datos demográficos). O puede hacerlo en el acto, p. si desea predecir los resultados de las elecciones en función de una muestra (como una encuesta de salida), probablemente le preguntará a las personas en el colegio electoral cómo votaron.
Por otro lado, si desea crear la misma encuesta antes de las elecciones, probablemente seleccione una muestra y se comunique con las personas por teléfono o en persona. Por lo general, solo hay unas pocas preguntas para este tipo de encuesta, algunas para cubrir datos demográficos y otras para cubrir lo que realmente nos interesa.
Las encuestas también pueden ser mucho más complejas, p. si desea conocer la opinión pública sobre un determinado producto, abarcando desde su desempeño hasta su empaque.
En este artículo, no discutiré cómo seleccionar un grupo de muestra de personas; más bien, me centraré en la encuesta en sí, sus preguntas y las respuestas.
Modelo de datos
Modelo de datos de la agencia de opinión pública
El modelo consta de tres áreas temáticas:
PollsQuestions & AnswersResult
Describiremos cada área temática en el orden en que aparece.
Encuestas
Antes de comenzar a hacer preguntas, debemos definir lo que nos interesa. Definiremos encuestas y cuestionarios en esta sección, luego agregaremos preguntas y respuestas en la siguiente.
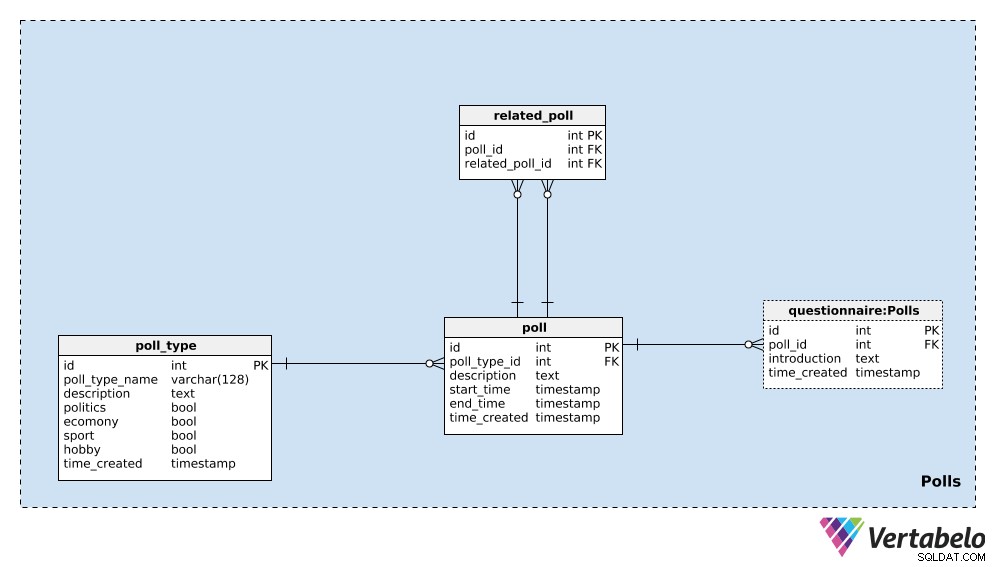
Comenzaremos con el poll_type diccionario. Podemos esperar que en su mayoría repitamos encuestas del mismo tipo. El tipo más común es probablemente las encuestas electorales, pero queremos poder agregar nuevos tipos de encuestas en el camino. Para cada tipo de encuesta, almacenaremos un ÚNICO poll_type_name y usa la description atributo para proporcionar detalles adicionales.
Cuatro banderas:politics , economy , sport y hobby – se utilizan para indicar el tipo de encuesta. Una encuesta podría cubrir uno o más de esos temas; si es necesario, podríamos dividir estas categorías en un diccionario separado y tener una relación de muchos a muchos entre ese diccionario y el poll_type mesa.
El último atributo de esta tabla es time_created . Denota el momento en que se inserta una fila en esta tabla.
Lo siguiente que debemos hacer es definir una única poll . Esta es una instancia única, p. “Elecciones presidenciales de Estados Unidos de 2020:encuesta de abril de 2020” . Para cada encuesta, almacenaremos los siguientes detalles:
poll_type_id– Una referencia alpoll_type.description– Todos los detalles relacionados con esta encuesta, en formato de texto.start_timeyend_time– Las horas de inicio y finalización definidas, durante las cuales se realiza esta encuesta.time_created– El momento real en que se creó esta encuesta.
Las encuestas se pueden relacionar entre sí. En el ejemplo de las “Elecciones presidenciales de Estados Unidos de 2020 – Encuesta de abril de 2020” , podríamos hacer la misma encuesta el próximo mes para ver las opiniones más actuales. Llamaríamos a esto “Elecciones presidenciales de Estados Unidos de 2020:encuesta de mayo de 2020” . Estas dos encuestas están relacionadas porque sus resultados muestran tendencias. Para establecer esa relación, usaremos la related_poll mesa en nuestro modelo. Contiene solo el par ÚNICO de poll_id – related_poll_id , que denota la encuesta y su predecesor.
Tenga en cuenta que podríamos usar esta tabla para almacenar todas las encuestas que están relacionadas de alguna manera, no solo las predecesoras/sucesoras. Si quisiéramos definir diferentes relaciones, necesitaríamos agregar otro diccionario, pero no seguiremos ese camino en este artículo.
La última tabla en esta área temática es el questionnaire mesa. En la mayoría de los casos, cada encuesta tendrá exactamente un cuestionario, pero quiero dejar la opción de que podamos tener más de uno si es necesario. Por lo tanto, he usado una tabla separada. En esta tabla, almacenaremos solo el ID de la encuesta relacionada (poll_id ), una introduction que describe ese cuestionario y la marca de tiempo cuando se insertó el registro (time_created ).
Preguntas y respuestas
Ahora estamos listos para crear todos los detalles del cuestionario. También podemos listar todas las preguntas que queremos hacer así como todas las respuestas predefinidas.
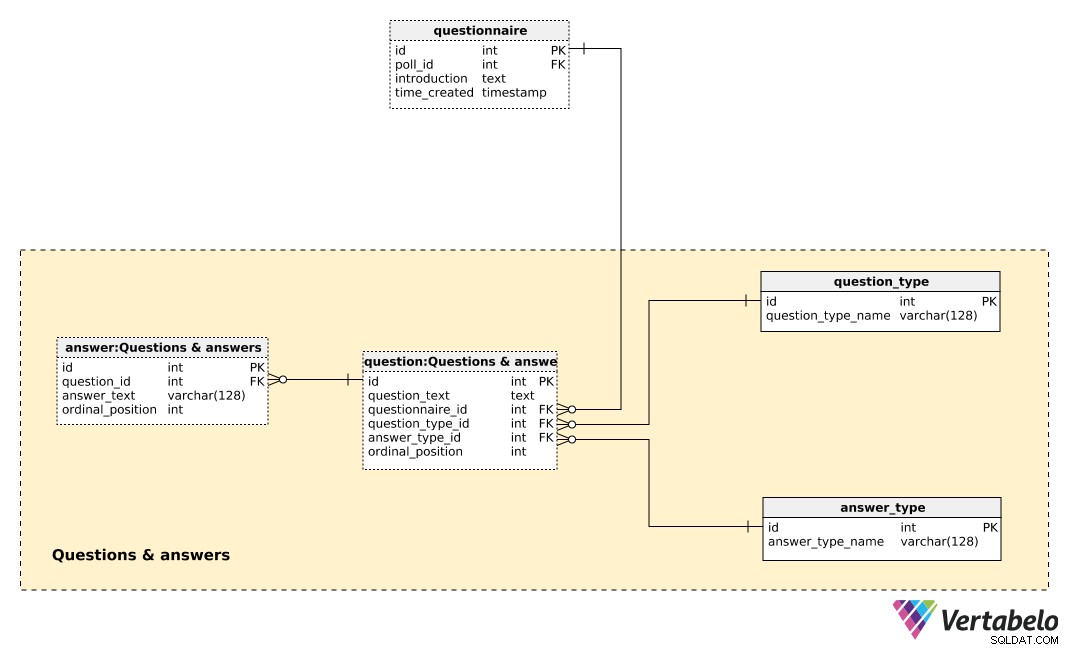
La tabla central en esta área temática es la question mesa. Cada pregunta está definida por los siguientes detalles:
question_text– Un texto que se mostrará a cada persona encuestada.questionnaire_id– Una referencia que indica el cuestionario de esta pregunta.question_type_id– Una referencia que indica elquestion_type, que se denota ÚNICAMENTE porquestion_type_name. Estas son básicamente categorías, p. “demografía”, “opinión”, “control”, etc. Estos nos permitirían separar las preguntas demográficas y de opinión y encontrar una correlación entre ellas.answer_type_id– Una referencia al tipo de respuesta que se utilizará para esta pregunta. Cadaanswer_typeestá definido ÚNICAMENTE poranswer_type_namey denota cómo se muestra la respuesta. Algunos tipos esperados son "abierto", "lista", "casilla de verificación" y "múltiple".ordinal_position– Este valor denota la posición de esta pregunta en el cuestionario. Junto con elquestionnaire_id, forma la clave alternativa de esta tabla.
Una lista de todas las respuestas predefinidas se almacena en la answer mesa. Si el tipo de pregunta no está abierto (es decir, la persona no ingresará el texto), tendremos un conjunto de respuestas predefinidas. Para cada respuesta, definiremos la pregunta a la que pertenece (question_id ), el answer_text , y la ordinal_position de esa respuesta dentro de esa pregunta. Una vez más, un par ÚNICO, esta vez question_id – ordinal_position – forma la clave alternativa de esta tabla.
Resultado
En las dos áreas temáticas anteriores, hemos definido todo lo que necesitamos para crear la encuesta y comenzar a hacer preguntas. Ahora necesitamos definir una estructura de datos para almacenar respuestas reales.
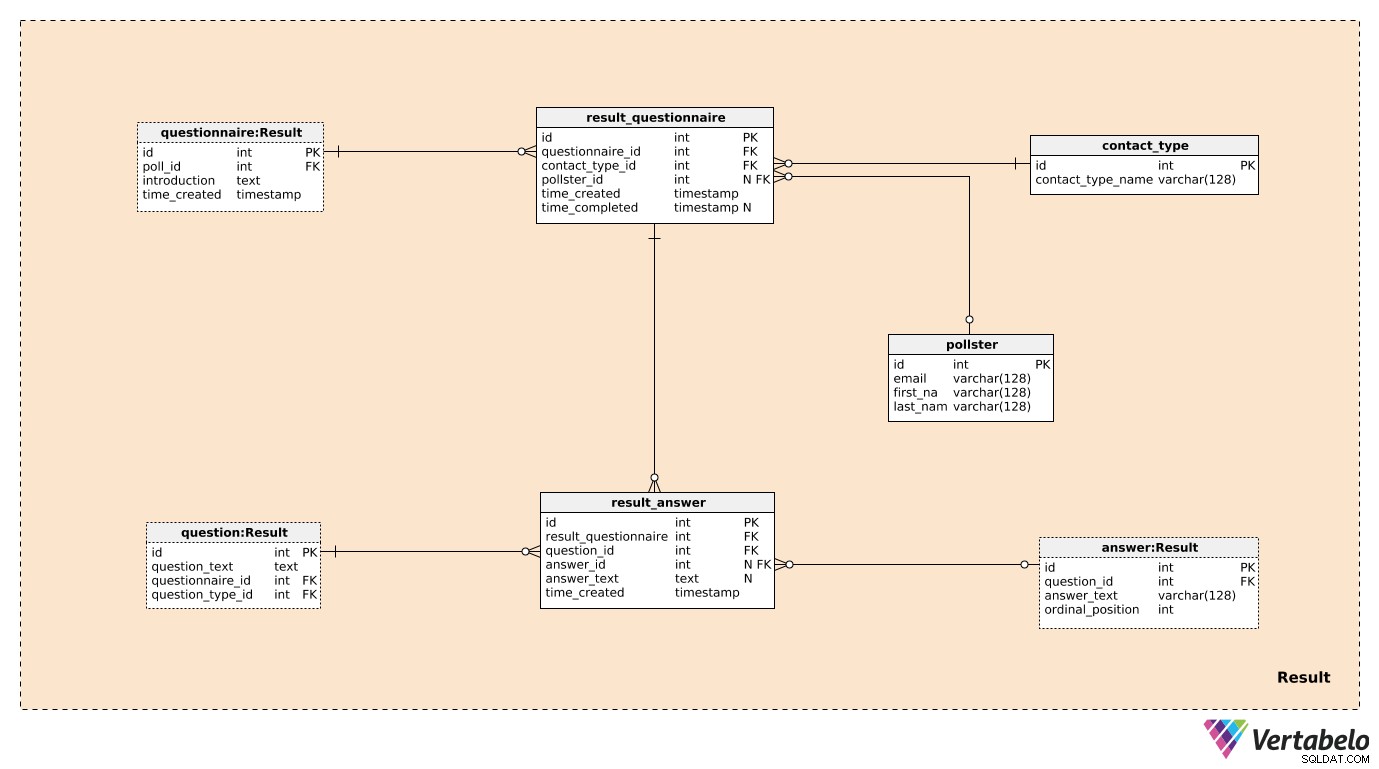
Tres de las siete tablas del Result área temática fueron mencionadas y descritas previamente. Estos son questionnaire , question y answer . Las cuatro tablas restantes se utilizan para almacenar lo que realmente nos interesa.
Crearemos un registro en el result_questionnaire tabla para cada persona que participa en la encuesta. El questionnaire_id proporcionarle a esus toda la información sobre la encuesta relevante. El contact_type_id es una referencia al contact_type diccionario. Los valores de esta tabla describen la forma en que hemos interactuado con esta persona. Estos valores están definidos ÚNICAMENTE por contact_type_name valor y podría ser algo así como "teléfono", "en persona", "correo electrónico", "formulario web", etc.
El pollster_id el atributo es una referencia al pollster tabla, que proporciona la información de quién realizó esa encuesta real. Para cada pollster , almacenaremos solo su correo electrónico ÚNICO y su first_name y last_name . El time_created El atributo indica la hora real en que se creó este registro, mientras que el time_completed se establecerá en el momento en que se complete esta encuesta. (Hasta ese momento, será NULL).
La última tabla del modelo es result_answer mesa. Como sugiere su nombre, aquí es donde almacenaremos las respuestas reales que obtuvimos de los encuestados. Para cada registro en esta tabla, tendremos:
result_questionnaire_id– Una referencia al cuestionario correspondiente.question_id– Una referencia que denota la pregunta respondida por esta respuesta.answer_id– Una referencia a la respuesta que se utilizó para responder a esta pregunta. Este atributo contendrá un valor NULL cuando la pregunta sea de tipo "abierto" (porque no había respuestas predefinidas para elegir).answer_text– El texto que se insertó para responder a esta pregunta. Este atributo contendrá un valor cuando la pregunta estaba "abierta"; en todos los demás casos, será NULL.time_created– La hora real en que se insertó esta respuesta en nuestro sistema.
Posibles mejoras
Hasta ahora, hemos cubierto cómo podemos almacenar datos de encuestas. No hemos discutido qué haríamos con los datos después de que se cierre la encuesta. Podemos esperar que no necesitemos los datos antiguos en el futuro, al menos no en nuestra base de datos operativa. Por lo tanto, podríamos hacer dos cosas:
- Almacene un resumen de la encuesta en una tabla separada en la base de datos operativa. Esto mantendría dicha información a nuestra disposición si quisiéramos ver qué sucedió con una encuesta similar.
- Almacene todos los datos de la encuesta en una base de datos de respaldo que tenga la misma estructura que la base de datos operativa. Esto nos permitiría acceder a los detalles cuando los necesitáramos.
También podríamos crear un almacén de datos para almacenar los resultados de las encuestas, pero eso no sería necesario si ya hubiéramos realizado las tareas descritas en los dos puntos.
¿Qué piensas de nuestro modelo de datos de encuestas de opinión?
Nos gustaría conocer su opinión sobre lo que podríamos cambiar para mejorar el modelo de datos de encuestas de opinión. ¿Tienes experiencia en la industria? ¿Crees que nos perdimos algo? ¿Añadirías o quitarías algo? Esperamos escuchar sus opiniones.



