Cámaras, puertas giratorias, ascensores, sensores de temperatura, alarmas:todos estos dispositivos producen una gran cantidad de señales interconectadas que están relacionadas con los eventos que suceden a nuestro alrededor. Ahora imagina que eres la persona que necesita realizar un seguimiento de los estados, producir informes en tiempo real y hacer predicciones basadas en todos estos datos de señales. Para hacer esto, primero necesita almacenar esos datos. Un modelo de datos que admita dicho procesamiento de señales es el tema del artículo de hoy.
La forma más sencilla de almacenar señales entrantes sería simplemente almacenar una representación textual de ellas en una lista enorme. Este enfoque nos permitiría realizar inserciones rápidamente, pero las actualizaciones serían problemáticas. Además, dicho modelo no se normalizaría y, por lo tanto, no iremos en esa dirección.
Crearemos un modelo de datos normalizados que podría usarse para almacenar los datos generados por diferentes dispositivos y también definir cómo se relacionan los dispositivos. Dicho modelo almacenaría de manera eficiente todo lo que necesitamos y también podría usarse para análisis y análisis predictivo.
Modelo de datos
El modelo de datos de procesamiento de señales
El modelo consta de tres áreas temáticas:
ComplexesInstallations & DevicesSignals & Events
Describiremos cada una de estas áreas temáticas en el orden en que aparecen.
Complejos
Mientras creaba este modelo de datos, supuse que lo usaríamos para rastrear lo que sucede en complejos más grandes. Los complejos varían en tamaño desde una habitación individual hasta un centro comercial. Es importante que cada complejo tenga al menos un dispositivo/sensor, pero probablemente tendrá muchos más.
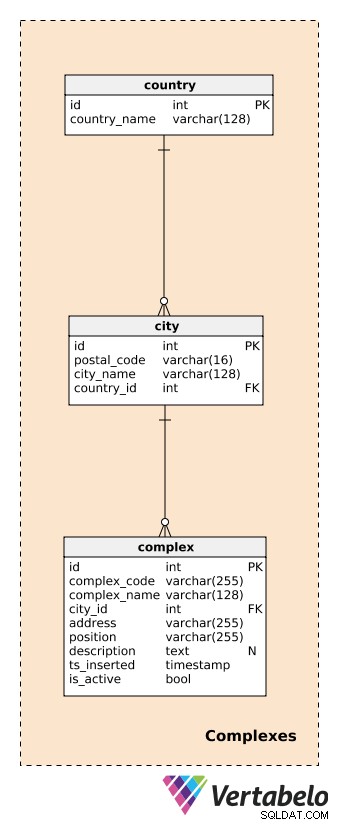
Antes de describir complejos, necesitamos definir las tablas que manejan países y ciudades. Estos proporcionarán una descripción bastante detallada de la ubicación de cada complejo.
Para cada country , almacenaremos su ÚNICO country_name; para cada city , almacenaremos la combinación ÚNICA de postal_code , city_name y country_id . No entraré en detalles aquí, y supondremos que cada ciudad tiene un solo código postal. En realidad, la mayoría de las ciudades tendrán más de un código postal; en ese caso, podemos usar el código principal de cada ciudad.
Un complex es el edificio o ubicación real donde se instalan los dispositivos de generación de datos. Como se mencionó anteriormente, los complejos pueden variar desde una sola habitación o una estación de medición hasta lugares mucho más grandes como estacionamientos, centros comerciales, cines, etc. Son el tema de nuestro análisis. Queremos poder hacer un seguimiento de lo que sucede a nivel complejo en tiempo real y, posteriormente, producir informes y análisis. Para cada complejo, definiremos un:
complex_code– Un identificador ÚNICO para cada complejo. Si bien tenemos un atributo de clave principal independiente (id) para esta tabla, podemos esperar que heredaremos otro código de identificación para cada complejo de otro sistema.complex_name– Un nombre usado para describir ese complejo. En el caso de centros comerciales y cines, este podría ser su nombre actual y conocido; para una estación de medición, podríamos usar un nombre genérico.city_id– Una referencia a la ciudad donde se encuentra el complejo.address– La dirección física de ese complejo.position– La posición del complejo (es decir, las coordenadas geográficas) definidas en formato de texto.description– Una descripción textual que describa más de cerca este complejo.ts_inserted– Una marca de tiempo cuando se insertó este registro.is_active– Un valor booleano que indica si este complejo aún está activo o no.
Instalaciones y Dispositivos
Ahora nos estamos acercando al corazón de nuestro modelo. Es probable que tengamos varios dispositivos instalados en cada complejo. Es casi seguro que también agruparemos estos dispositivos en función de su propósito, p. podríamos poner cámaras, sensores de puerta y un motor que se usa para abrir y cerrar una puerta en un grupo porque funcionan juntos.
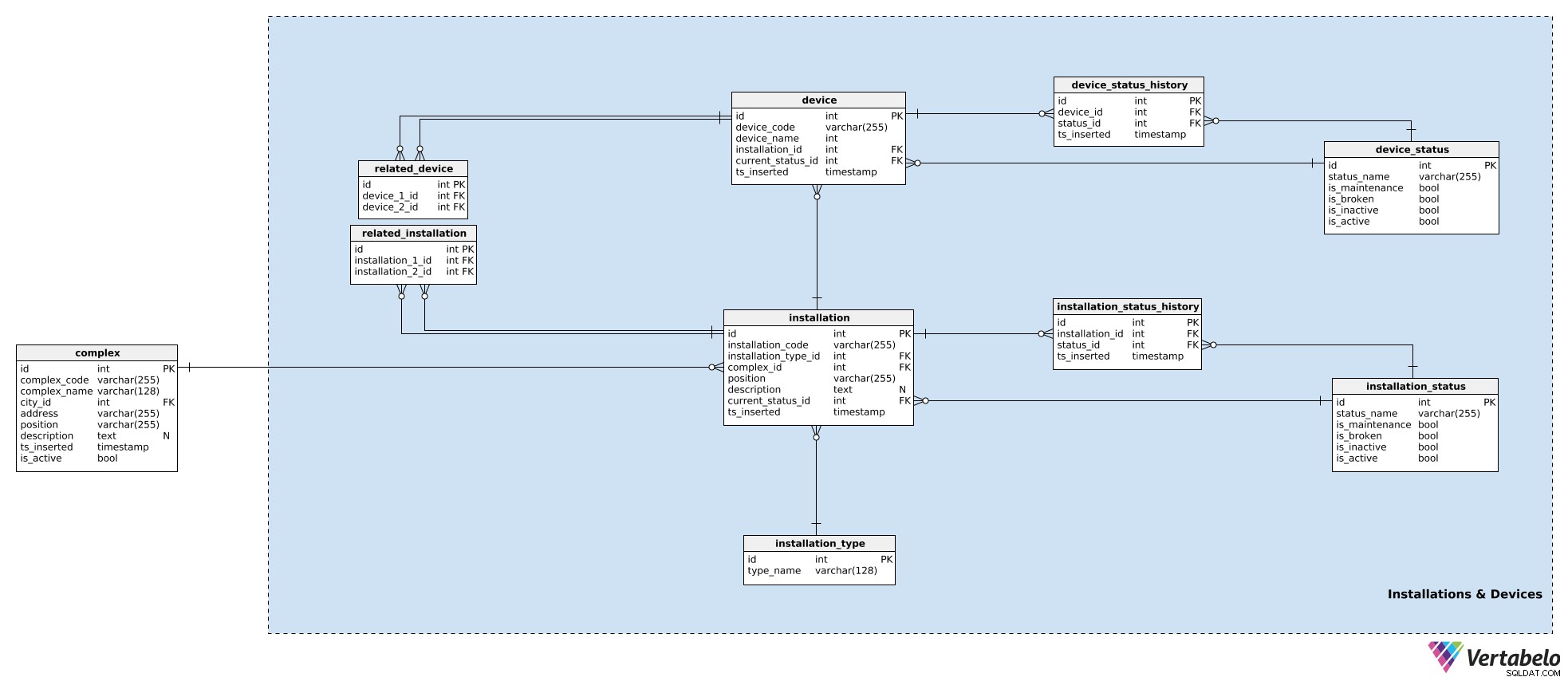
En nuestro modelo, los dispositivos que funcionan juntos en un complejo se agrupan en instalaciones. Estos podrían ser para puertas de entrada, escaleras mecánicas, sensores de temperatura, etc. Para cada instalación, almacenaremos los siguientes detalles en la installation tabla:
installation_code– Un código ÚNICO utilizado para indicar esa instalación.installation type_id– Una referencia alinstallation_typediccionario. Este diccionario almacena solo untype_nameÚNICO atributo que describe el tipo, p. escalera mecánica, ascensor.complex_id– Una referencia alcomplexa la que pertenece esa instalación.position– Las coordenadas, en formato textual, de esa instalación dentro del complejo.description– Una descripción textual de esa instalación.current_status_id– Una referencia al estado actual (delinstallation_statustabla) de esa instalación.ts_inserted– Una marca de tiempo cuando se insertó este registro en nuestro sistema.
Ya hemos mencionado los estados de instalación. Una lista de todos los estados posibles se almacena en installation_status diccionario. Cada estado se define ÚNICAMENTE por su status_name . Además de eso, almacenaremos banderas que indiquen si ese estado, cuando se usa, implica que la instalación is_broken , is_inactive , is_maintenance , o is_active . Solo se debe establecer una de estas banderas a la vez.
Ya hemos asignado un estado actual a la instalación. Si vamos a realizar un seguimiento de lo que sucede con el dispositivo, también debemos almacenar su historial. Para hacer eso, usaremos una tabla más, installation_status_history . Para cada registro aquí, almacenaremos referencias a la instalación y el estado relacionados, así como el momento (ts_inserted ) cuando se asignó ese estado.
Las instalaciones forman parte de nuestros complejos. Si bien cada instalación es una sola entidad, aún podría estar relacionada con otras instalaciones. (Por ejemplo, un sistema de video en la entrada principal de un centro comercial obviamente está relacionado con las puertas principales del centro comercial:la cámara verá primero a las personas y luego se abrirán las puertas). Si queremos realizar un seguimiento de estas relaciones, las almacenaremos en la related_installation mesa. Tenga en cuenta que esta tabla contiene solo pares ÚNICOS de dos claves, ambas con referencia a la installation mesa.
La misma lógica se utiliza para almacenar dispositivos. Los dispositivos son piezas únicas de hardware que producen las señales que nos interesan. Mientras que las instalaciones pertenecen a complejos, los dispositivos pertenecen a instalaciones. Para cada device , almacenaremos:
device_code– Una forma ÚNICA de indicar cada dispositivo.device_name– Un nombre para este dispositivo.installation_id– Una referencia a la instalación a la que pertenece este dispositivo.current_status_id– El estado actual del dispositivo.ts_inserted– Una marca de tiempo cuando se insertó este registro.
Los estados se manejan de la misma manera. Usaremos el device_status tabla para almacenar una lista de todos los estados posibles del dispositivo. Esta tabla tiene la misma estructura que installation_status y los atributos se utilizan de la misma manera. La razón de tener los dos diccionarios de estado separados es que los dispositivos y sus instalaciones pueden tener diferentes estados, al menos en el nombre.
El estado actual se almacena en el device.current_status_id atributo y el historial de estado se almacena en el device_status_history mesa. Para cada registro aquí, almacenaremos las relaciones con el dispositivo y el estado, así como el momento en que se insertó este registro.
La última tabla en esta área temática es related_device mesa. Si bien es bastante obvio que todos los dispositivos dentro de la misma instalación están estrechamente relacionados, quiero tener la opción de relacionar dos dispositivos que pertenezcan a cualquier instalación. Lo haremos almacenando sus dos ID de dispositivo en esta tabla.
Señales y Eventos
Ahora estamos listos para el corazón de todo el modelo.
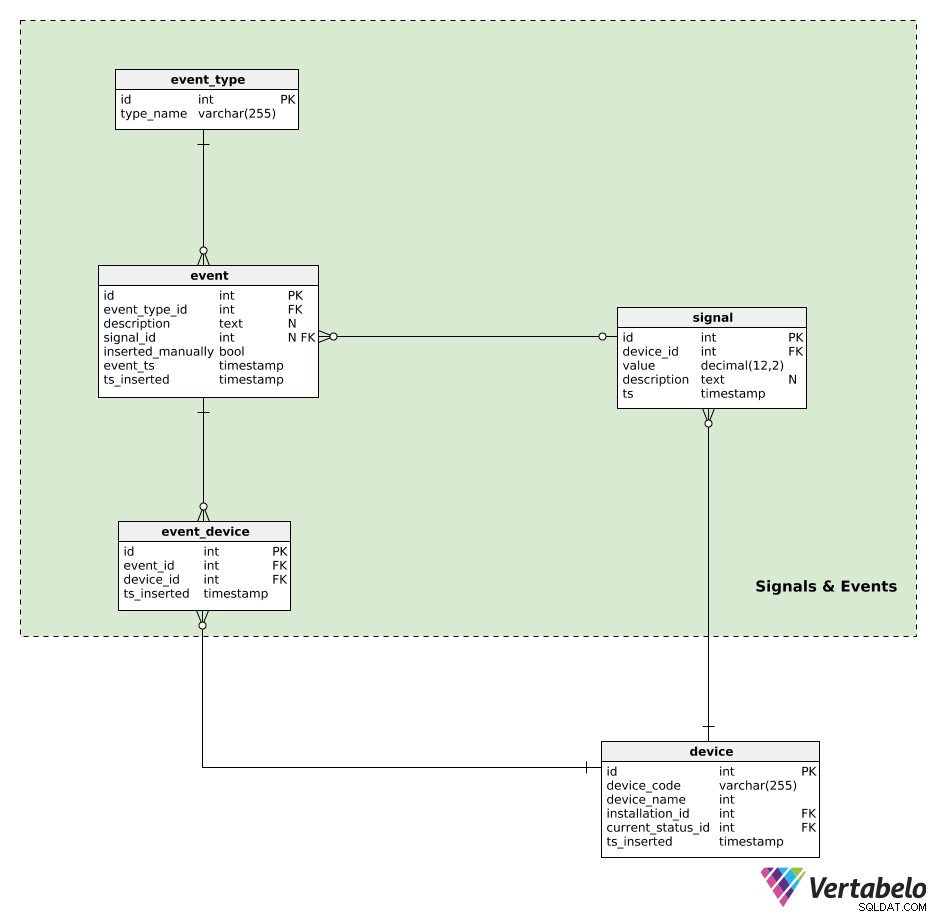
Los dispositivos generan señales. Todos los datos de la señal se guardan en la signal mesa. Para cada señal, almacenaremos:
device_id– Una referencia al dispositivo que generó esa señal.value– El valor numérico de esa señal.description– Un valor textual que podría contener cualquier parámetro adicional (por ejemplo, tipo de señal, valores, unidad de medida utilizada) relacionado con esa única señal. Estos datos se almacenan en un formato similar a JSON.ts– Una marca de tiempo cuando esta señal se insertó en la tabla.
Podemos esperar que esta tabla tenga un uso extremadamente intenso, con una gran cantidad de inserciones realizadas por segundo. Por lo tanto, el mantenimiento de la base de datos debe centrarse en realizar un seguimiento del tamaño de esta tabla.
Lo último que quiero hacer es agregar eventos a nuestro modelo de datos. Los eventos pueden ser generados automáticamente por una señal o insertados manualmente. Un evento generado automáticamente podría ser "puerta abierta durante 5 minutos", mientras que un evento insertado manualmente podría ser "el dispositivo tuvo que apagarse debido a esta señal". La idea general es almacenar acciones que ocurrieron como resultado del comportamiento del dispositivo. Posteriormente, podríamos usar estos eventos mientras realizamos un análisis del comportamiento del dispositivo.
Los eventos serán granulados por event_type . Cada tipo se define ÚNICAMENTE por su type_name .
Todos los eventos generados automáticamente o insertados manualmente se registran en el event mesa. Para cada registro aquí, almacenaremos:
event_type_id– Una referencia al tipo de evento relacionado.description– Una descripción textual de ese evento.signal_id– Una referencia a la señal, si la hay, que provocó el evento.inserted_manually– Una bandera que indica si este registro se insertó manualmente o no.event_tsyts_inserted–Marcas de tiempo cuando realmente ocurrió este evento y cuando se insertó un registro del mismo. Estos dos pueden diferir, especialmente cuando los registros de eventos se insertan manualmente.
La última tabla de nuestro modelo es event_device mesa. Esta tabla se utiliza para relacionar eventos con todos los dispositivos que estuvieron involucrados. Para cada registro, almacenaremos el par ÚNICO event_id – device_id y la marca de tiempo cuando se insertó el registro.
¿Qué opinas sobre nuestro modelo de datos de procesamiento de señales?
Hoy, analizamos un modelo de datos simplificado que podríamos usar para rastrear señales de un conjunto de dispositivos instalados en diferentes ubicaciones. El modelo en sí debería ser suficiente para almacenar todo lo que necesitamos para rastrear estados y realizar análisis. Aún así, muchas mejoras son posibles. ¿Qué podríamos agregar? Cuéntanos en los comentarios a continuación.