La concatenación agrupada es un problema común en SQL Server, sin funciones directas e intencionales que la admitan (como XMLAGG en Oracle, STRING_AGG o ARRAY_TO_STRING(ARRAY_AGG()) en PostgreSQL y GROUP_CONCAT en MySQL). Se ha solicitado, pero aún no ha tenido éxito, como se evidencia en estos elementos de Connect:
- Conexión n.° 247118:SQL necesita la versión de la función MySQL group_Concat (pospuesta)
- Conexión n.° 728969:funciones de conjuntos ordenados:cláusula DENTRO DEL GRUPO (cerrado porque no se solucionará)
** ACTUALIZACIÓN Enero 2017 ** :STRING_AGG() estará en SQL Server 2017; lea sobre esto aquí, aquí y aquí.
¿Qué es la concatenación agrupada?
Para la concatenación agrupada no iniciada es cuando desea tomar varias filas de datos y comprimirlas en una sola cadena (generalmente con delimitadores como comas, tabulaciones o espacios). Algunos podrían llamar a esto una "unión horizontal". Un ejemplo visual rápido que demuestra cómo comprimiríamos una lista de mascotas pertenecientes a cada miembro de la familia, desde la fuente normalizada hasta la salida "aplanada":
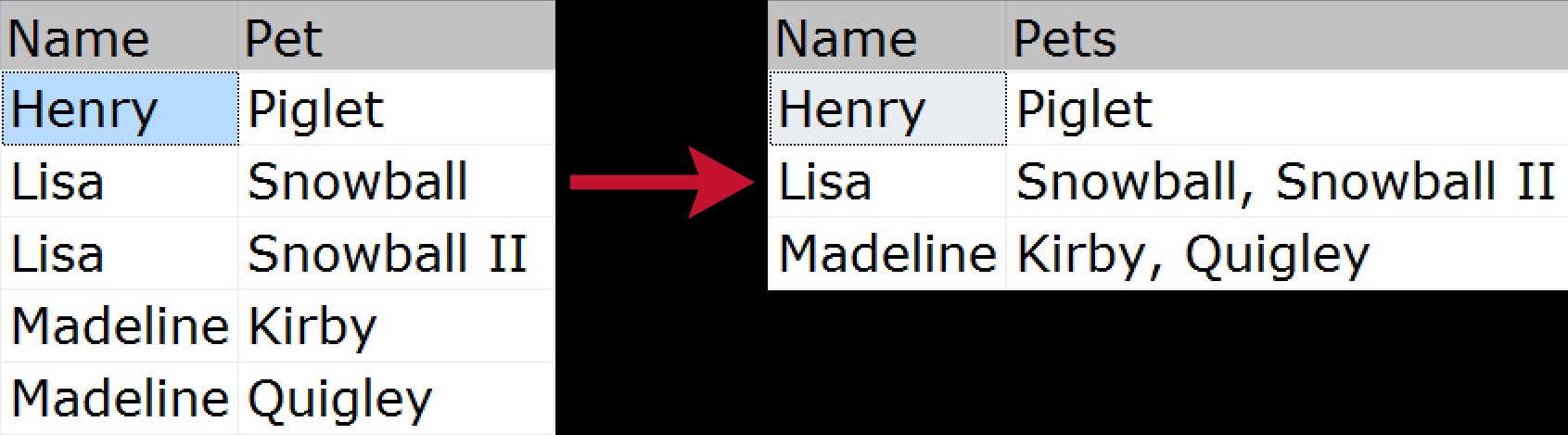
Ha habido muchas formas de resolver este problema a lo largo de los años; Estos son solo algunos, basados en los siguientes datos de muestra:
CREATE TABLE dbo.FamilyMemberPets ( Name SYSNAME, Pet SYSNAME, PRIMARY KEY(Name,Pet) ); INSERT dbo.FamilyMemberPets(Name,Pet) VALUES (N'Madeline',N'Kirby'), (N'Madeline',N'Quigley'), (N'Henry', N'Piglet'), (N'Lisa', N'Snowball'), (N'Lisa', N'Snowball II');
No voy a mostrar una lista exhaustiva de todos los enfoques de concatenación agrupada jamás concebidos, ya que quiero centrarme en algunos aspectos de mi enfoque recomendado, pero quiero señalar algunos de los más comunes:
FDU escalar
CREATE FUNCTION dbo.ConcatFunction
(
@Name SYSNAME
)
RETURNS NVARCHAR(MAX)
WITH SCHEMABINDING
AS
BEGIN
DECLARE @s NVARCHAR(MAX);
SELECT @s = COALESCE(@s + N', ', N'') + Pet
FROM dbo.FamilyMemberPets
WHERE Name = @Name
ORDER BY Pet;
RETURN (@s);
END
GO
SELECT Name, Pets = dbo.ConcatFunction(Name)
FROM dbo.FamilyMemberPets
GROUP BY Name
ORDER BY Name; Nota:hay una razón por la que no hacemos esto:
SELECT DISTINCT Name, Pets = dbo.ConcatFunction(Name) FROM dbo.FamilyMemberPets ORDER BY Name;
Con DISTINCT , la función se ejecuta para cada fila, luego se eliminan los duplicados; con GROUP BY , los duplicados se eliminan primero.
Tiempo de ejecución de lenguaje común (CLR)
Esto usa el GROUP_CONCAT_S función encontrada en https://groupconcat.codeplex.com/:
SELECT Name, Pets = dbo.GROUP_CONCAT_S(Pet, 1) FROM dbo.FamilyMemberPets GROUP BY Name ORDER BY Name;
CTE recursivo
Hay varias variaciones de esta recursividad; este saca un conjunto de nombres distintos como ancla:
;WITH x as
(
SELECT Name, Pet = CONVERT(NVARCHAR(MAX), Pet),
r1 = ROW_NUMBER() OVER (PARTITION BY Name ORDER BY Pet)
FROM dbo.FamilyMemberPets
),
a AS
(
SELECT Name, Pet, r1 FROM x WHERE r1 = 1
),
r AS
(
SELECT Name, Pet, r1 FROM a WHERE r1 = 1
UNION ALL
SELECT x.Name, r.Pet + N', ' + x.Pet, x.r1
FROM x INNER JOIN r
ON r.Name = x.Name
AND x.r1 = r.r1 + 1
)
SELECT Name, Pets = MAX(Pet)
FROM r
GROUP BY Name
ORDER BY Name
OPTION (MAXRECURSION 0); Cursores
No hay mucho que decir aquí; los cursores generalmente no son el enfoque óptimo, pero esta puede ser su única opción si está atascado en SQL Server 2000:
DECLARE @t TABLE(Name SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name));
INSERT @t(Name, Pets)
SELECT Name, N''
FROM dbo.FamilyMemberPets GROUP BY Name;
DECLARE @name SYSNAME, @pet SYSNAME, @pets NVARCHAR(MAX);
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR SELECT Name, Pet
FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
OPEN c;
FETCH c INTO @name, @pet;
WHILE @@FETCH_STATUS = 0
BEGIN
UPDATE @t SET Pets += N', ' + @pet
WHERE Name = @name;
FETCH c INTO @name, @pet;
END
CLOSE c; DEALLOCATE c;
SELECT Name, Pets = STUFF(Pets, 1, 1, N'')
FROM @t
ORDER BY Name;
GO Actualización peculiar
Algunas personas *adoran* este enfoque; No entiendo la atracción en absoluto.
DECLARE @Name SYSNAME, @Pets NVARCHAR(MAX);
DECLARE @t TABLE(Name SYSNAME, Pet SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name, Pet));
INSERT @t(Name, Pet)
SELECT Name, Pet FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
UPDATE @t SET @Pets = Pets = COALESCE(
CASE COALESCE(@Name, N'')
WHEN Name THEN @Pets + N', ' + Pet
ELSE Pet END, N''),
@Name = Name;
SELECT Name, Pets = MAX(Pets)
FROM @t
GROUP BY Name
ORDER BY Name; PARA RUTA XML
Fácilmente mi método preferido, al menos en parte porque es la única forma de *garantizar* el pedido sin usar un cursor o CLR. Dicho esto, esta es una versión muy cruda que no aborda un par de otros problemas inherentes que discutiré más adelante:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N'')), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
He visto a mucha gente asumir erróneamente que el nuevo CONCAT() La función introducida en SQL Server 2012 fue la respuesta a estas solicitudes de funciones. Esa función solo está destinada a operar contra columnas o variables en una sola fila; no se puede usar para concatenar valores entre filas.
Más información sobre FOR XML PATH
FOR XML PATH('') por sí solo no es lo suficientemente bueno:tiene problemas conocidos con la entidadización XML. Por ejemplo, si actualiza uno de los nombres de mascotas para incluir un paréntesis HTML o un ampersand:
UPDATE dbo.FamilyMemberPets SET Pet = N'Qui>gle&y' WHERE Pet = N'Quigley';
Estos se traducen a entidades seguras para XML en algún lugar del camino:
Qui>gle&y
Así que siempre uso PATH, TYPE).value() , de la siguiente manera:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
También uso siempre NVARCHAR , porque nunca se sabe cuándo alguna columna subyacente contendrá Unicode (o se cambiará más tarde para que lo haga).
Puede ver las siguientes variedades dentro de .value() , o incluso otros:
... TYPE).value(N'.', ... ... TYPE).value(N'(./text())[1]', ...
Estos son intercambiables, y todos representan en última instancia la misma cadena; las diferencias de rendimiento entre ellos (más abajo) fueron insignificantes y posiblemente completamente no deterministas.
Otro problema con el que puede encontrarse son ciertos caracteres ASCII que no se pueden representar en XML; por ejemplo, si la cadena contiene el carácter 0x001A (CHAR(26) ), recibirá este mensaje de error:
FOR XML no pudo serializar los datos para el nodo 'NoName' porque contiene un carácter (0x001A) que no está permitido en XML. Para recuperar estos datos usando FOR XML, conviértalos a tipo de datos binario, varbinary o de imagen y use la directiva BINARY BASE64.
Esto me parece bastante complicado, pero espero que no tenga que preocuparse porque no está almacenando datos como estos o al menos no está tratando de usarlos en una concatenación agrupada. Si es así, es posible que deba recurrir a uno de los otros enfoques.
Rendimiento
Los datos de muestra anteriores facilitan la prueba de que todos estos métodos hacen lo que esperamos, pero es difícil compararlos de manera significativa. Así que llené la tabla con un conjunto mucho más grande:
TRUNCATE TABLE dbo.FamilyMemberPets; INSERT dbo.FamilyMemberPets(Name,Pet) SELECT o.name, c.name FROM sys.all_objects AS o INNER JOIN sys.all_columns AS c ON o.[object_id] = c.[object_id] ORDER BY o.name, c.name;
Para mí, fueron 575 objetos, con un total de 7080 filas; el objeto más ancho tenía 142 columnas. Ahora, de nuevo, es cierto que no me propuse comparar todos los enfoques concebidos en la historia de SQL Server; solo los pocos aspectos destacados que publiqué anteriormente. Estos fueron los resultados:
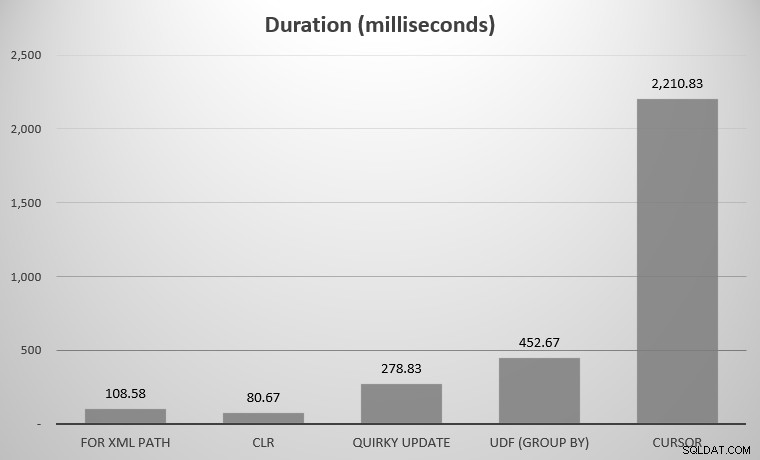
Puede notar que faltan un par de contendientes; el UDF usando DISTINCT y el CTE recursivo estaban tan fuera de serie que sesgarían la escala. Estos son los resultados de los siete enfoques en forma tabular:
| Enfoque | Duración (milisegundos) |
|---|---|
| PARA LA RUTA XML | 108.58 |
| CLR | 80.67 |
| Actualización peculiar | 278,83 |
| UDF (GRUPO POR) | 452,67 |
| UDF (DISTINTO) | 5.893,67 |
| Cursores | 2.210,83 |
| CTE recursivo | 70.240,58 |
Duración promedio, en milisegundos, para todos los enfoques
También tenga en cuenta que las variaciones en FOR XML PATH se probaron de forma independiente pero mostraron diferencias muy pequeñas, así que simplemente los combiné para obtener el promedio. Si realmente quieres saberlo, el .[1] la notación funcionó más rápido en mis pruebas; YMMV.
Conclusión
Si no está en una tienda donde CLR es un obstáculo de alguna manera, y especialmente si no solo está tratando con nombres simples u otras cadenas, definitivamente debería considerar el proyecto CodePlex. No intente reinventar la rueda, no intente trucos y trucos poco intuitivos para hacer CROSS APPLY u otras construcciones funcionan un poco más rápido que los enfoques que no son CLR anteriores. Simplemente tome lo que funciona y conéctelo. Y diablos, dado que también obtiene el código fuente, puede mejorarlo o ampliarlo si lo desea.
Si CLR es un problema, entonces FOR XML PATH es probablemente tu mejor opción, pero aún así deberás tener cuidado con los personajes engañosos. Si está atascado en SQL Server 2000, su única opción factible es la UDF (o un código similar que no esté envuelto en una UDF).
La próxima vez
Un par de cosas que quiero explorar en una publicación de seguimiento:eliminar duplicados de la lista, ordenar la lista por algo que no sea el valor en sí mismo, casos en los que poner cualquiera de estos enfoques en un UDF puede ser doloroso y casos de uso práctico para esta funcionalidad.