En mi última publicación, comencé una serie para cubrir los controles de salud proactivos que son vitales para su servidor SQL. Comenzamos con el espacio en disco y en esta publicación discutiremos las tareas de mantenimiento. Una de las responsabilidades fundamentales de un DBA es garantizar que las siguientes tareas de mantenimiento se ejecuten regularmente:
- Copias de seguridad
- Comprobaciones de integridad
- Mantenimiento de índice
- Actualizaciones de estadísticas
Mi apuesta es que ya tiene puestos de trabajo para administrar estas tareas. Y también apostaría a que tiene notificaciones configuradas para enviarle un correo electrónico a usted y a su equipo si falla un trabajo. Si ambos son ciertos, entonces ya está siendo proactivo con respecto al mantenimiento. Y si no está haciendo ambas cosas, eso es algo que debe solucionar ahora mismo, por ejemplo, deje de leer esto, descargue los guiones de Ola Hallengren, prográmelos y asegúrese de configurar las notificaciones. (Otra alternativa específica para el mantenimiento de índices, que también recomendamos a los clientes, es SQL Sentry Fragmentation Manager).
Si no sabe si sus trabajos están configurados para enviarle un correo electrónico si fallan, utilice esta consulta:
SELECT [Name], [Description] FROM [dbo].[sysjobs] WHERE [enabled] = 1 AND [notify_level_email] NOT IN (2,3) ORDER BY [Name];
Sin embargo, ser proactivo en el mantenimiento va un paso más allá. Más allá de asegurarse de que sus trabajos se ejecuten, necesita saber cuánto tardan. Puede usar las tablas del sistema en msdb para monitorear esto:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
CASE [h].[run_status]
WHEN 0 THEN 'Failed'
WHEN 1 THEN 'Succeeded'
WHEN 2 THEN 'Retry'
WHEN 3 THEN 'Cancelled'
WHEN 4 THEN 'In Progress'
END AS [ExecutionStatus],
[h].[message] AS [MessageGenerated]
FROM [msdb].[dbo].[sysjobhistory] [h]
INNER JOIN [msdb].[dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [j].[name] = 'DatabaseBackup - SYSTEM_DATABASES – FULL'
AND [step_id] = 0
ORDER BY [RunDate]; O, si está utilizando los scripts de Ola y la información de registro, puede consultar su tabla CommandLog:
SELECT [DatabaseName], [CommandType], [StartTime], [EndTime], DATEDIFF(MINUTE, [StartTime], [EndTime]) AS [Duration_Minutes] FROM [master].[dbo].[CommandLog] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'BACKUP DATABASE%' ORDER BY [StartTime];
El script anterior enumera la duración de la copia de seguridad para cada copia de seguridad completa de la base de datos AdventureWorks2014. Puede esperar que la duración de las tareas de mantenimiento aumente lentamente con el tiempo, a medida que las bases de datos crezcan. Como tal, está buscando grandes aumentos o disminuciones inesperadas en la duración. Por ejemplo, tenía un cliente con una duración promedio de copia de seguridad de menos de 30 minutos. De repente, las copias de seguridad comenzaron a tardar más de una hora. La base de datos no había cambiado significativamente en tamaño, no había cambiado la configuración de la instancia o la base de datos, nada había cambiado con la configuración del hardware o del disco. Unas semanas más tarde, la duración de la copia de seguridad se redujo a menos de media hora. Un mes después de eso, volvieron a subir. Eventualmente correlacionamos el cambio en la duración de la copia de seguridad con las conmutaciones por error entre los nodos del clúster. En un nodo, las copias de seguridad tardaron menos de media hora. Por otro, tardaron más de una hora. Una pequeña investigación sobre la configuración de las NIC y la estructura SAN y pudimos identificar el problema.
También es importante comprender el tiempo promedio de ejecución de las operaciones CHECKDB. Esto es algo de lo que Paul habla en nuestro Evento de inmersión de alta disponibilidad y recuperación ante desastres:debe saber cuánto tarda normalmente CHECKDB en ejecutarse, de modo que si encuentra corrupción y ejecuta una verificación en toda la base de datos, sepa cuánto tiempo debería tomar para CHECKDB para completar. Cuando su jefe pregunta:"¿Cuánto falta para que sepamos el alcance del problema?" podrá proporcionar una respuesta cuantitativa de la cantidad mínima de tiempo que deberá esperar. Si CHECKDB tarda más de lo normal, entonces sabrá que se encontró algo (lo que no necesariamente debe ser corrupción; siempre debe dejar que finalice la verificación).
Ahora, si está administrando cientos de bases de datos, no desea ejecutar la consulta anterior para cada base de datos o cada trabajo. En su lugar, es posible que desee encontrar trabajos que se encuentren fuera de la duración promedio en un cierto porcentaje, que puede obtener mediante esta consulta:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
[avdur].[Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
INNER JOIN
(
SELECT
[j].[name] AS [JobName],
AVG((([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60))
AS [Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [step_id] = 0
AND CONVERT(DATE, RTRIM(h.run_date)) >= DATEADD(DAY, -60, GETDATE())
GROUP BY [j].[name]
) AS [avdur]
ON [avdur].[JobName] = [j].[name]
WHERE [step_id] = 0
AND (([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
> ([avdur].[Avg_RunDuration_Minutes] + ([avdur].[Avg_RunDuration_Minutes] * .25))
ORDER BY [j].[name], [RunDate]; Esta consulta enumera los trabajos que tardaron un 25% más que el promedio. La consulta requerirá algunos ajustes para proporcionar la información específica que desea:algunos trabajos con una duración pequeña (por ejemplo, menos de 5 minutos) aparecerán si solo toman unos minutos adicionales, eso podría no ser una preocupación. Sin embargo, esta consulta es un buen comienzo y se da cuenta de que hay muchas formas de encontrar desviaciones:también puede comparar cada ejecución con la anterior y buscar trabajos que demoraron un cierto porcentaje más que el anterior.
Obviamente, la duración del trabajo es el identificador más lógico para problemas potenciales, ya sea un trabajo de copia de seguridad, una verificación de integridad o el trabajo que elimina la fragmentación y actualiza las estadísticas. Descubrí que la mayor variación en la duración suele estar en las tareas para eliminar la fragmentación y actualizar las estadísticas. Dependiendo de sus umbrales de reorganización versus reconstrucción, y la volatilidad de sus datos, puede pasar días con reorganizaciones en su mayoría, y luego, de repente, un par de reconstrucciones de índice se activan para tablas grandes, donde esas reconstrucciones alteran por completo la duración promedio. Es posible que desee cambiar los umbrales de algunos índices o ajustar el factor de relleno para que las reconstrucciones se produzcan con mayor o menor frecuencia, según el índice y el nivel de fragmentación. Para realizar estos ajustes, debe observar la frecuencia con la que se reconstruye o reorganiza cada índice, lo que solo puede hacer si está utilizando los scripts de Ola e iniciando sesión en la tabla CommandLog, o si implementó su propia solución y está iniciando sesión. cada reorganización o reconstrucción. Para ver esto usando la tabla CommandLog, puede comenzar comprobando qué índices se modifican con más frecuencia:
SELECT [DatabaseName], [ObjectName], [IndexName], COUNT(*) FROM [master].[dbo].[CommandLog] [c] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'ALTER INDEX%' GROUP BY [DatabaseName], [ObjectName], [IndexName] ORDER BY COUNT(*) DESC;
A partir de este resultado, puede comenzar a ver qué tablas (y, por lo tanto, índices) tienen la mayor volatilidad y luego determinar si es necesario ajustar el umbral para la reorganización frente a la reconstrucción o modificar el factor de relleno.
Haciendo la vida más fácil
Ahora, existe una solución más fácil que escribir sus propias consultas, siempre y cuando utilice SQL Sentry Event Manager (EM). La herramienta supervisa todos los trabajos del Agente configurados en una instancia y, al utilizar la vista de calendario, puede ver rápidamente qué trabajos fallaron, se cancelaron o duraron más de lo habitual:
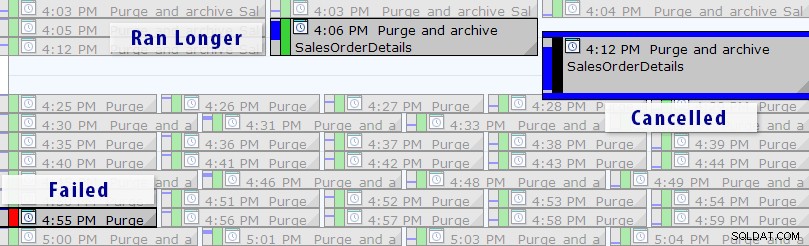 Vista de calendario de SQL Sentry Event Manager (con etiquetas añadidas en Photoshop)
Vista de calendario de SQL Sentry Event Manager (con etiquetas añadidas en Photoshop)
También puede profundizar en ejecuciones individuales para ver cuánto tiempo tardó en ejecutarse un trabajo, y también hay prácticos gráficos de tiempo de ejecución que le permiten visualizar rápidamente cualquier patrón en anomalías de duración o condiciones de falla. En este caso, puedo ver que aproximadamente cada 15 minutos, la duración del tiempo de ejecución de este trabajo específico aumentó casi un 400 %:
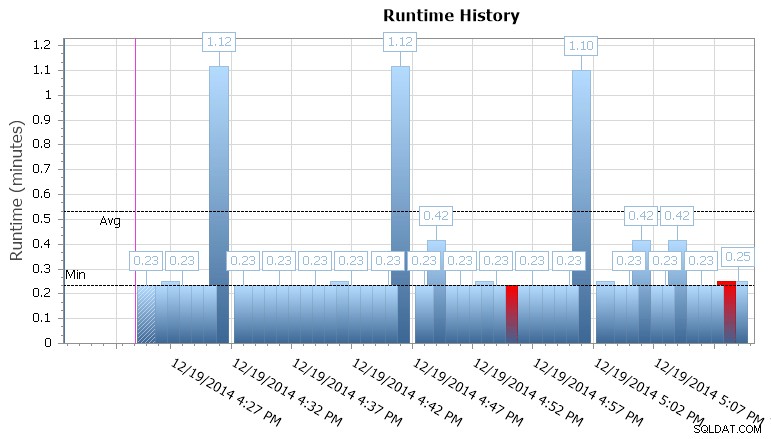 Gráfico de tiempo de ejecución de SQL Sentry Event Manager
Gráfico de tiempo de ejecución de SQL Sentry Event Manager
Esto me da una pista de que debería buscar otros trabajos programados que pueden estar causando algunos problemas de simultaneidad aquí. Podría volver a alejar el calendario para ver qué otros trabajos se están ejecutando al mismo tiempo, o puede que ni siquiera necesite mirar para reconocer que se trata de un trabajo de creación de informes o copia de seguridad que se ejecuta en esta base de datos.
Resumen
Apuesto a que la mayoría de ustedes ya tienen los trabajos de mantenimiento necesarios y que también tienen notificaciones configuradas para fallas en los trabajos. Si no está familiarizado con las duraciones promedio de sus trabajos, ese es su próximo paso para ser proactivo. Nota:es posible que también deba verificar para ver cuánto tiempo está reteniendo el historial de trabajo. Cuando busco desviaciones en la duración del trabajo, prefiero mirar los datos de unos pocos meses, en lugar de unas pocas semanas. No necesita memorizar esos tiempos de ejecución, pero una vez que haya verificado que está manteniendo suficientes datos para tener el historial para usar en la investigación, comience a buscar variaciones de forma regular. En un escenario ideal, el mayor tiempo de ejecución puede alertarlo sobre un posible problema, lo que le permite abordarlo antes de que ocurra un problema en su entorno de producción.



