Hay mucho que puedes decir sobre la historia y la importancia. Historia de un país, de una civilización, de cada uno de nosotros. Me encantan las citas y me gusta esta de Teddy Roosevelt (chico genial):
Cuanto más sepa sobre el pasado, mejor preparado estará para el futuro.¿Por qué me estoy poniendo poético (o tratando de hacerlo) sobre la historia en un blog sobre SQL Server? Porque la historia en SQL Server también es importante. Cuando existe un problema de rendimiento en SQL Server, es ideal solucionar el problema en vivo, pero en algunos casos, la información histórica puede proporcionar una prueba irrefutable, o al menos un punto de partida. Una gran fuente de información histórica en SQL Server es el ERRORLOG. Mencioné en mi publicación original, Problemas de rendimiento:el primer encuentro, que el ERRORLOG solía ser una ocurrencia tardía para mí. No más. Durante las auditorías de los clientes, siempre capturamos los ERRORLOG y, aunque se nos notifica cualquier alerta de gravedad alta (que se escribe en el registro), no es extraño encontrar otra información interesante en el registro. Nos preparamos para el futuro utilizando la información histórica de los registros; la información puede ayudarnos a solucionar un problema, o un problema potencial, antes de que se vuelva catastrófico.
Ver el REGISTRO DE ERRORES
En primer lugar, revisaremos algunas opciones para ver el ERROLOG. Si estoy conectado a una instancia, normalmente navego hasta ella a través de SSMS (Administración | Registros de SQL Server, hago clic con el botón derecho en un registro y selecciono Ver registro de SQL Server). Desde esta ventana, puedo desplazarme por el registro o usar las opciones de filtro o búsqueda para reducir el conjunto de resultados. También puedo ver varios archivos seleccionándolos en el panel de la izquierda.
Si estoy viendo los datos capturados en una de nuestras auditorías de salud, simplemente abro los archivos de registro en un editor de texto y los reviso (tengo la opción de ingresar al visor y cargarlos también). Los archivos de registro existen en la carpeta de registro (ubicación predeterminada:C:\Program Files\Microsoft SQL Server\MSSQL12.SQL2014\MSSQL\Log) si alguna vez quisiera verlos en el servidor. Muchos de ustedes pueden preferir ver y/o buscar en el registro utilizando el procedimiento no documentado sp_readerrorlog o el procedimiento almacenado extendido xp_readerrorlog.
Y, por último, si está interesado en PowerShell, también es una opción para leer el registro de esa manera (consulte esta publicación:Use PowerShell to Parse SQL Server 2012 Error Logs). El método depende de usted:use lo que sabe y lo que funciona para usted; es el contenido lo que realmente importa. Y recuerde que hay momentos en los que simplemente necesitará leer el registro para comprender el orden de los eventos, y hay otros momentos en los que puede buscar para encontrar un error específico o información.
¿Qué hay en el REGISTRO DE ERRORES?
Entonces, ¿qué información podemos encontrar en el ERRORLOG, además de errores? He enumerado muchos de los elementos que he encontrado más útiles a continuación. Tenga en cuenta que esta no es una lista exhaustiva (y estoy seguro de que muchos de ustedes tendrán sugerencias de lo que podría agregarse; ¡siéntanse libres de publicar un comentario y puedo actualizar esto!), pero nuevamente, esto es lo que estoy buscando primero cuando miro de forma proactiva una instancia.
- Si el servidor es físico o virtual (busque la entrada del fabricante del sistema)
- Banderas de rastreo habilitadas al inicio
- Dentro de la entrada de los parámetros de inicio del Registro, si se desplaza completamente hacia la derecha, verá si hay marcas de rastreo habilitadas:
 Banderas de rastreo habilitadas al inicio
Banderas de rastreo habilitadas al inicio
- Dentro de la entrada de los parámetros de inicio del Registro, si se desplaza completamente hacia la derecha, verá si hay marcas de rastreo habilitadas:
- Marcas de seguimiento habilitadas o deshabilitadas después de que se haya iniciado la instancia
- Si los usuarios (o una aplicación) habilitan o deshabilitan un indicador de seguimiento mediante DBCC TRACEON o DBCC TRACEOFF, aparece una entrada en el registro
- Número de núcleos y sockets detectados por SQL Server
- Siempre me gusta verificar que SQL Server vea todo el hardware disponible y, si no, es una señal de alerta para investigar más a fondo. Para ver un buen ejemplo, consulte la publicación de Jonathan, Problemas de rendimiento con SQL Server 0212 Enterprise Edition bajo licencia CAL, y la publicación de Glenn, Equilibrar sus licencias principales de SQL Server disponibles de manera uniforme en los nodos NUMA, que también incluye algunos TSQL útiles para consultar el registro.
- Tenga en cuenta que el texto de esta entrada varía entre las versiones de SQL Server.
- Cantidad de memoria detectada por SQL Server
- Nuevamente, quiero verificar que SQL Server vea toda la memoria disponible.
- Confirmación de que las páginas bloqueadas en la memoria (LPIM) están habilitadas
- Si bien esta opción está habilitada a través de la política de seguridad de Windows, puede confirmar que está habilitada buscando el mensaje "Uso de páginas bloqueadas en el administrador de memoria" en el registro.
- Tenga en cuenta que si tiene Trace Flag 834 en uso, entonces el mensaje no dirá páginas bloqueadas, dirá que se están usando páginas grandes para el grupo de búfer.
- Versión de CLR en uso
- Éxito o fracaso del registro del nombre principal del servicio (SPN)
- Cuánto tarda una base de datos en conectarse
- El registro registra cuándo se inicia la base de datos y cuándo está en línea; compruebo si alguna base de datos tarda demasiado en aparecer.
- Estado de los extremos de Service Broker y Database Mirroring:importante si utiliza cualquiera de las funciones
- Confirmación de que la inicialización instantánea de archivos (IFI) está habilitada*
- De manera predeterminada, esta información no se registra, pero si habilita Trace Flag 3004 (y 3605 para forzar la salida al registro), cuando cree o haga crecer un archivo de datos, verá mensajes en el registro para indicar si IFI está en uso o no.
- Estado de seguimientos de SQL
- Cuando inicia o detiene un seguimiento de SQL, se registra y miro si existe algún seguimiento más allá del seguimiento predeterminado (ya sea temporalmente o a largo plazo). Si está ejecutando una herramienta de monitoreo de terceros, como el Asesor de rendimiento de SQL Sentry, es posible que vea un seguimiento activo que siempre se está ejecutando, pero que solo captura eventos específicos, o puede ver un seguimiento que se inicia, se ejecuta durante un período breve y luego detener. No me preocupan uno o dos seguimientos adicionales, a menos que estén capturando muchos eventos, pero definitivamente presto atención cuando se ejecutan múltiples seguimientos.
- La última vez que se completó CHECKDB
- Este mensaje suele ser malinterpretado por las personas:cuando se inicia la instancia, lee la página de inicio de cada base de datos y anota cuándo CHECKDB se ejecutó correctamente por última vez. La mayoría de las personas no leen el mensaje completo:
 Fecha en que DBCC CHECKDB se completó con éxito por última vez
Fecha en que DBCC CHECKDB se completó con éxito por última vez La fecha de finalización de CHECKDB es el 11 de noviembre de 2012, pero la fecha de ERRORLOG es el 7 de julio de 2015. Es importante comprender que SQL Server no ejecute CHECKDB contra las bases de datos al inicio, verifica el valor dbcclastknowngood en la página de inicio (para ver cuándo se actualiza, consulte mi publicación, What Checks Update dbcclastknowngood. Además, si DBCC CHECKDB nunca se ejecutó contra una base de datos, entonces no hay entrada aparecerá para la base de datos aquí.
- Este mensaje suele ser malinterpretado por las personas:cuando se inicia la instancia, lee la página de inicio de cada base de datos y anota cuándo CHECKDB se ejecutó correctamente por última vez. La mayoría de las personas no leen el mensaje completo:
- Completar CHECKDB
- Cuando se ejecuta CHECKDB en una base de datos, el resultado se registra en el registro.
- Cambios en la configuración de la instancia
- Si cambia una configuración a nivel de instancia (p. ej., memoria máxima del servidor, umbral de costo para el paralelismo) mediante sp_configure o a través de la interfaz de usuario (tenga en cuenta que no registra quién lo cambió).
- Cambios en la configuración de la base de datos
- ¿Alguien habilitó AUTO_SHRINK? ¿Cambiar la opción RECUPERACIÓN a SIMPLE y luego volver a LLENO? Lo encontrará aquí.
- Cambios en el estado de la base de datos
- Si alguien desconecta una base de datos (o la conecta), esto se registra.
- Información de interbloqueo*
- Si necesita capturar información de punto muerto, no desea ejecutar un seguimiento, y está ejecutando SQL Server 2005 a 2008R2, use el indicador de seguimiento 1222 para escribir información de punto muerto en el registro en formato XML. Para aquellos de ustedes que usan SQL Server 2000 y versiones anteriores, pueden rastrear el indicador 1204 (este indicador de rastreo también está disponible en SQL Server 2005+, pero genera información mínima). Si está ejecutando SQL Server 2012 o superior, esto no es necesario, ya que la sesión de eventos system_health captura esta información (y también está allí en 2008 y 20082, pero tiene que extraerla del ring_buffer frente al objetivo event_file).
- Mensajes de FlushCache
- Si SQL Server vacía la caché porque el proceso del punto de control supera el intervalo de recuperación de la base de datos, verá un conjunto de mensajes de FlushCache en el registro (consulte esta publicación de Bob Dorr para obtener más información). No confunda estos mensajes con los que aparecen cuando ejecuta DBCC FREEPROCCACHE o DBCC FREESYSTEMCACHE:
 Mensaje después de ejecutar DBCC FREEPROCCACHE o DBCC FREESYSTEMCACHE
Mensaje después de ejecutar DBCC FREEPROCCACHE o DBCC FREESYSTEMCACHE
- Si SQL Server vacía la caché porque el proceso del punto de control supera el intervalo de recuperación de la base de datos, verá un conjunto de mensajes de FlushCache en el registro (consulte esta publicación de Bob Dorr para obtener más información). No confunda estos mensajes con los que aparecen cuando ejecuta DBCC FREEPROCCACHE o DBCC FREESYSTEMCACHE:
- Mensajes de descarga de AppDomain
- El registro también indica cuándo se crean AppDomains, y solo verá si está usando CLR. Si veo que AppDomain descarga mensajes debido a la presión de la memoria, es algo para investigar más a fondo.
Hay otra información en el registro que es útil, como el modo de autenticación en uso, si la Conexión de administración dedicada (DAC) está habilitada o no, etc. pero también puedo obtener eso de sys.configurations y lo verifico con las líneas base de instancia Mencioné anteriormente (Comprobaciones de estado proactivas de SQL Server, Parte 3:Configuración de instancias y bases de datos).
¿Qué no hay en el ERROLOG que podría esperar?
Esta es una lista corta, por ahora, ya que supongo que algunos de ustedes podrían haber encontrado otras cosas que pensaron que estarían en el registro pero no lo estaban...
- Agregar o eliminar archivos de base de datos o grupos de archivos
- Inicio o detención de sesiones de eventos extendidos
- Sin embargo, si implementa un activador DDL o una notificación de evento a nivel de servidor, puede registrar esta información. Consulte la publicación de Jonathan, Registro de cambios de eventos extendidos en el REGISTRO DE ERRORES, para obtener más detalles.
- La ejecución de DBCC DROPCLEANBUFFERS aparece en el REGISTRO DE ERRORES
Gestionar el registro
Recuerde que, de manera predeterminada, SQL Server solo conserva los seis (6) archivos de registro más recientes (además del archivo actual), y el archivo de registro se actualiza cada vez que SQL Server se reinicia. Como resultado, a veces puede tener archivos de registro extremadamente grandes que tardan un tiempo en abrirse y son difíciles de examinar. Por otro lado, si se encuentra con un caso en el que la instancia se reinicia un par de veces, es posible que pierda información importante. Se recomienda aumentar la cantidad de archivos retenidos a un valor mayor (p. ej., 30) y crear un trabajo de agente para pasar el archivo una vez por semana mediante sp_cycle_errorlog.
Además de administrar los archivos, puede determinar qué información se escribe en el registro. Una de las entradas más comunes que crean desorden en el REGISTRO DE ERRORES es la entrada de copia de seguridad correcta:
 Copia de seguridad completada con éxito
Copia de seguridad completada con éxito
Si tiene una instancia con numerosas bases de datos y se realizan copias de seguridad del registro de transacciones con cierta regularidad (por ejemplo, cada 15 minutos), verá que el registro se llena rápidamente de mensajes, lo que hace que sea más difícil encontrar un problema real. Afortunadamente, puede usar el indicador de rastreo 3226 para deshabilitar los mensajes de respaldo exitosos (los errores seguirán apareciendo en el registro y todas las entradas seguirán existiendo en msdb).
Otro conjunto de mensajes que abarrotan el registro son los mensajes de inicio de sesión exitosos. Esta es una opción que configura para la instancia en la pestaña Seguridad:
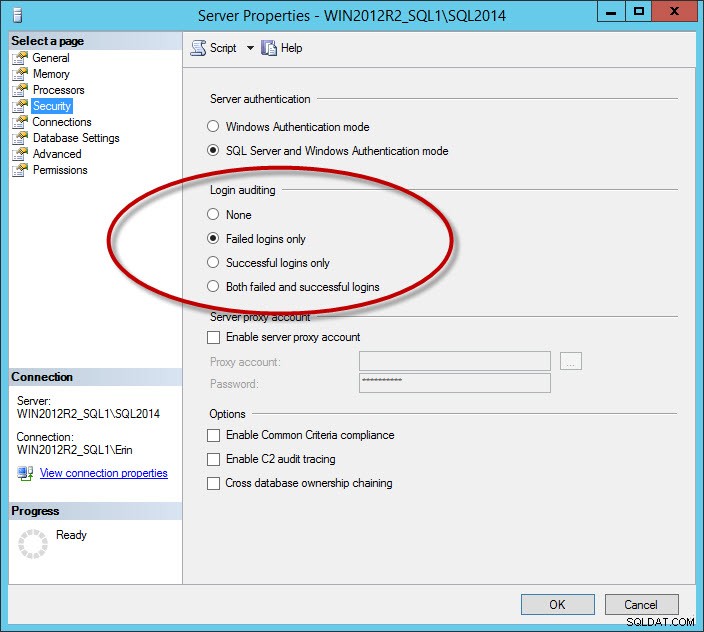 Opción de seguridad para registrar inicios de sesión exitosos y/o fallidos
Opción de seguridad para registrar inicios de sesión exitosos y/o fallidos
Si registra inicios de sesión exitosos o inicios de sesión fallidos y exitosos, puede tener archivos de registro muy grandes, incluso si transfiere los archivos diariamente (dependerá de cuántos usuarios se conecten). Recomiendo capturar solo los inicios de sesión fallidos. Para las empresas que tienen el requisito de registrar inicios de sesión exitosos, considere usar la función de auditoría, agregada en SQL Server 2008. Nota al margen:si cambia la configuración de auditoría de inicio de sesión, no tendrá efecto hasta que reinicie la instancia.
No subestimes el REGISTRO DE ERRORES
Como puede ver, hay información excelente en el ERRORLOG para que la use no solo cuando está solucionando problemas de rendimiento o investigando errores, sino también cuando está monitoreando una instancia de manera proactiva. Puede encontrar información en el registro que no se encuentra en ningún otro lugar; asegúrese de revisarlo regularmente y no dejarlo como una ocurrencia tardía.
Vea las otras partes de esta serie:
- Parte 1:Espacio en disco
- Parte 2:Mantenimiento
- Parte 3:Configuración de la instancia y la base de datos