Introducción
Rebobinado son específicos de los operadores en el lado interior de una combinación o aplicación de bucles anidados. La idea es reutilizar los resultados calculados previamente de parte de un plan de ejecución donde sea seguro hacerlo.
El ejemplo canónico de un operador de plan que puede rebobinar es el perezoso Table Spool . Su razón de ser es almacenar en caché las filas de resultados de un subárbol del plan, luego reproducir esas filas en iteraciones posteriores si los parámetros de bucle correlacionados no se modifican. Reproducir filas puede ser más económico que volver a ejecutar el subárbol que las generó. Para obtener más información sobre estos spools de rendimiento ver mi artículo anterior.
La documentación dice que solo los siguientes operadores pueden rebobinar:
- Carrete de mesa
- Bobina de recuento de filas
- Spool de índice no agrupado
- Función con valores de tabla
- Ordenar
- Consulta remota
- Afirmar y Filtro operadores con una expresión de inicio
Los primeros tres elementos suelen ser carretes de rendimiento, aunque pueden introducirse por otras razones (cuando pueden ser ansiosos y perezosos).
Funciones con valores de tabla use una variable de tabla, que se puede usar para almacenar en caché y reproducir resultados en circunstancias adecuadas. Si le interesan los rebobinados de funciones con valores de tabla, consulte mis preguntas y respuestas en Stack Exchange para administradores de bases de datos.
Con esos fuera del camino, este artículo es exclusivamente sobre Tipos y cuándo pueden rebobinar.
Ordenar rebobinados
Las clasificaciones usan almacenamiento (memoria y tal vez disco si se derraman), por lo que tienen una instalación capaz de almacenar filas entre iteraciones de bucle. En particular, la salida clasificada puede, en principio, reproducirse (rebobinarse).
Aún así, la respuesta corta a la pregunta del título, "¿Rebobinar ordena?" es:
Sí, pero no lo verás muy a menudo.
Tipos de clasificación
Las ordenaciones vienen en muchos tipos diferentes internamente, pero para nuestros propósitos actuales solo hay dos:
- Ordenación en memoria (
CQScanInMemSortNew).- Siempre en memoria; no se puede derramar al disco.
- Utiliza la ordenación rápida de la biblioteca estándar.
- Máximo de 500 filas y dos páginas de 8 KB en total.
- Todas las entradas deben ser constantes de tiempo de ejecución. Por lo general, esto significa que todo el subárbol de clasificación debe constar de solo Escaneo constante y/o Calcular escalar operadores.
- Solo se distingue explícitamente en planes de ejecución cuando plan detallado está habilitado (indicador de seguimiento 8666). Esto agrega propiedades adicionales a Ordenar operador, uno de los cuales es "InMemory=[0|1]".
- Todos los demás tipos.
(Ambos tipos de Ordenar el operador incluye su Top N Sort y Clasificación distinta variantes).
Comportamientos de rebobinado
-
Ordenaciones en memoria siempre puede rebobinar cuando es seguro. Si no hay parámetros de bucle correlacionados, o los valores de los parámetros no se modifican con respecto a la iteración inmediatamente anterior, este tipo de clasificación puede reproducir sus datos almacenados en lugar de volver a ejecutar los operadores debajo de él en el plan de ejecución.
-
Ordenes no en memoria puede rebobinar cuando sea seguro, pero solo si Ordenar el operador contiene como máximo una fila . Tenga en cuenta una clasificación input puede proporcionar una fila en algunas iteraciones, pero no en otras. Por lo tanto, el comportamiento del tiempo de ejecución puede ser una mezcla compleja de rebobinados y reenlaces. Depende completamente de cuántas filas se proporcionen al Ordenar en cada iteración en tiempo de ejecución. Por lo general, no se puede predecir qué Ordenar hará en cada iteración al inspeccionar el plan de ejecución.
La palabra "seguro" en las descripciones anteriores significa:No se produjo un cambio en el parámetro o no hubo operadores debajo de Ordenar tener una dependencia del valor modificado.
Nota importante sobre los planes de ejecución
Los planes de ejecución no siempre informan sobre rebobinados (y reenlaces) correctamente para Ordenar operadores. El operador informará un rebobinado si alguno de los parámetros correlacionados no ha cambiado y un reenlace en caso contrario.
Para clasificaciones que no están en la memoria (con mucho, las más comunes), un rebobinado informado solo reproducirá los resultados de clasificación almacenados si hay como máximo una fila en el búfer de salida de clasificación. De lo contrario, la ordenación informará un rebobinado, pero el subárbol aún se volverá a ejecutar por completo (un reenlace).
Para verificar cuántos rebobinados informados fueron rebobinados reales, verifique el Número de ejecuciones propiedad en operadores debajo de Ordenar .
Historia y mi explicacion
El Ordenar El comportamiento de rebobinado del operador puede parecer extraño, pero ha sido así desde (al menos) SQL Server 2000 hasta SQL Server 2019 inclusive (así como Azure SQL Database). No he podido encontrar ninguna explicación o documentación oficial al respecto.
Mi opinión personal es que Ordenar los rebobinados son bastante costosos debido a la maquinaria de clasificación subyacente, incluidas las instalaciones de derrames, y el uso de transacciones del sistema en tempdb .
En la mayoría de los casos, el optimizador hará mejor en introducir un spool de rendimiento explícito cuando detecta la posibilidad de duplicar parámetros de bucle correlacionados. Los spools son la forma menos costosa de almacenar en caché los resultados parciales.
Es posible que reproducir un Ordenar el resultado solo sería más rentable que un Spool cuando el Ordenar contiene como máximo una fila. Después de todo, clasificar una fila (¡o ninguna fila!) en realidad no implica ninguna clasificación, por lo que se puede evitar gran parte de la sobrecarga.
Pura especulación, pero alguien tenía que preguntar, así que ahí está.
Demostración 1:Rebobinados imprecisos
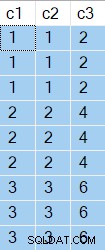
Este primer ejemplo presenta dos variables de tabla. El primero contiene tres valores duplicados tres veces en la columna c1 . La segunda tabla contiene dos filas para cada coincidencia en c2 = c1 . Las dos filas coincidentes se distinguen por un valor en la columna c3 .
La tarea es devolver la fila de la segunda tabla con el c3 más alto valor para cada coincidencia en c1 = c2 . El código es probablemente más claro que mi explicación:
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
INSERT @T2
(c2, c3)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(3, 5),
(3, 6);
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
CROSS APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
El NO_PERFORMANCE_SPOOL hay una sugerencia para evitar que el optimizador introduzca un spool de rendimiento. Esto puede suceder con las variables de la tabla cuando, p. el indicador de seguimiento 2453 está habilitado o la compilación diferida de la variable de tabla está disponible, por lo que el optimizador puede ver la verdadera cardinalidad de la variable de tabla (pero no la distribución del valor).
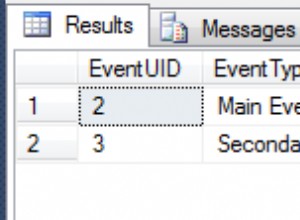
Los resultados de la consulta muestran el c2 y c3 los valores devueltos son los mismos para cada c1 distinto valor:
El plan de ejecución real para la consulta es:
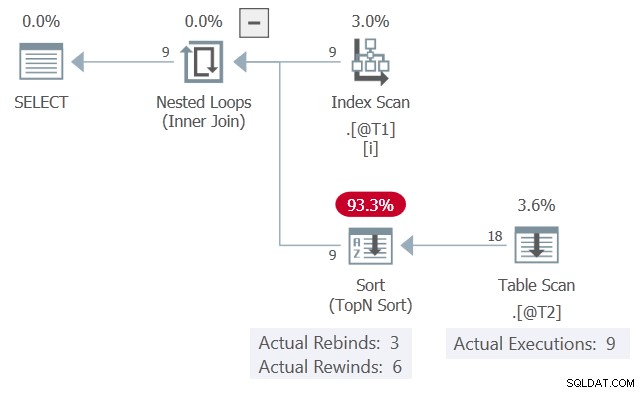
El c1 los valores, presentados en orden, coinciden con la iteración anterior 6 veces y cambian 3 veces. El Ordenar reporta esto como 6 rebobinados y 3 reenlaces.
Si esto fuera cierto, el Table Scan solo se ejecutaría 3 veces. El Ordenar reproduciría (rebobinaría) sus resultados en las otras 6 ocasiones.
Tal como está, podemos ver el Table Scan se ejecutó 9 veces, una por cada fila de la tabla @T1 . No hubo rebobinados aquí .
Demostración 2:Ordenar rebobinados
El ejemplo anterior no permitía Ordenar para rebobinar porque (a) no es una clasificación en memoria; y (b) en cada iteración del ciclo, el Sort contenía dos filas. Plan Explorer muestra un total de 18 filas del Escaneo de tabla , dos filas en cada una de las 9 iteraciones.
Modifiquemos el ejemplo ahora para que solo haya uno fila en la tabla @T2 para cada fila coincidente de @T1 :
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- Only one matching row per iteration now
INSERT @T2
(c2, c3)
VALUES
--(1, 1),
(1, 2),
--(2, 3),
(2, 4),
--(3, 5),
(3, 6);
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
CROSS APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
Los resultados son los mismos que se mostraron anteriormente porque mantuvimos la fila coincidente que se clasificó más alta en la columna c3 . El plan de ejecución también es superficialmente similar, pero con una diferencia importante:
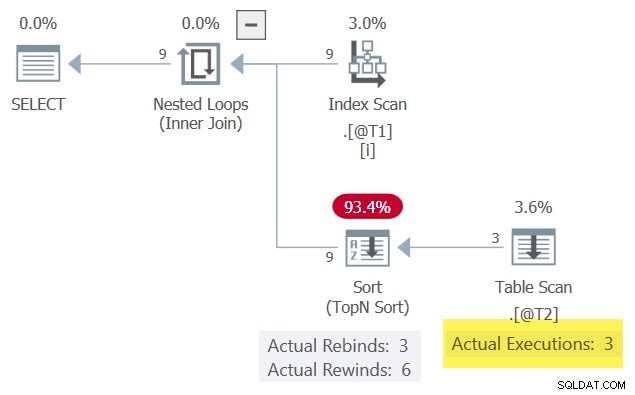
Con una fila en el Ordenar en cualquier momento, puede rebobinar cuando el parámetro correlacionado c1 no cambia. El escaneo de tablas como resultado, solo se ejecuta 3 veces.
Observe el Orden produce más filas (9) de lo que recibe (3). Esta es una buena indicación de que un Sort ha logrado almacenar en caché un conjunto de resultados una o más veces:un rebobinado exitoso.
Demostración 3:Rebobinar nada
Mencioné antes que un Sort no en memoria puede rebobinar cuando contiene como máximo una fila.
Para ver eso en acción con cero filas , cambiamos a un OUTER APPLY y no ponga filas en la tabla @T2 . Por razones que se harán evidentes en breve, también dejaremos de proyectar la columna c2 :
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- No rows added to table @T2
-- No longer projecting c2
SELECT
T1.c1,
--CA.c2,
CA.c3
FROM @T1 AS T1
OUTER APPLY
(
SELECT TOP (1)
--T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
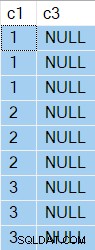
Los resultados ahora tienen NULL en la columna c3 como se esperaba:
El plan de ejecución es:
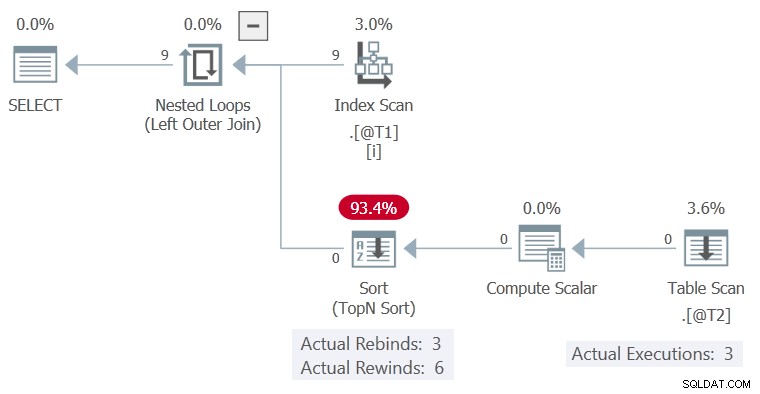
El Ordenar fue capaz de rebobinar sin filas en su búfer, por lo que el Exploración de tabla solo se ejecutó 3 veces, cada vez la columna c1 valor cambiado.
Demostración 4:¡Rebobinado máximo!
Al igual que los demás operadores que admiten rebobinados, un Ordenar solo reenlazará su subárbol si un parámetro correlacionado ha cambiado y el subárbol depende de ese valor de alguna manera.
Restaurando la columna c2 la proyección a la demostración 3 mostrará esto en acción:
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- Still no rows in @T2
-- Column c2 is back!
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
OUTER APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
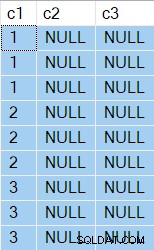
Los resultados ahora muestran dos NULL columnas por supuesto:
El plan de ejecución es bastante diferente:
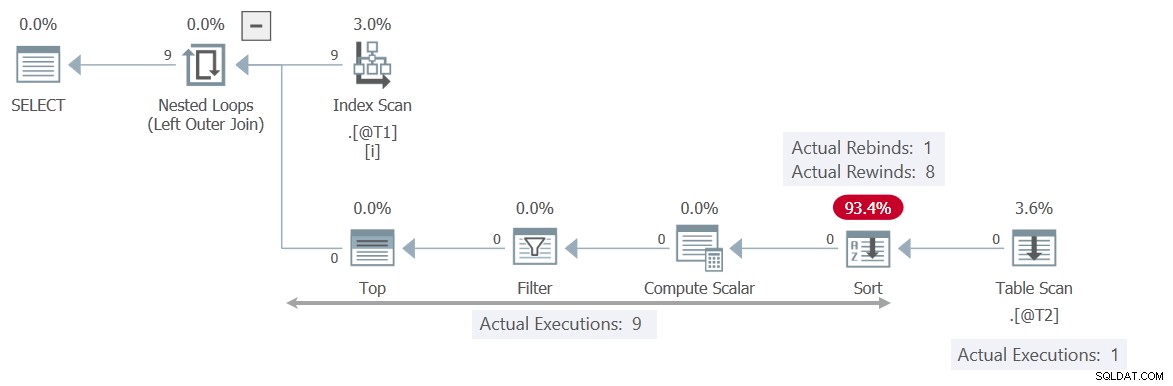
Esta vez, el Filtro contiene el control T2.c2 = T1.c1 , realizando el Table Scan independiente del valor actual del parámetro correlacionado c1 . El Ordenar puede rebobinar con seguridad 8 veces, lo que significa que el escaneo solo se ejecuta una vez .
Demostración 5:Clasificación en memoria
El siguiente ejemplo muestra una Ordenación en memoria operador:
DECLARE @T table (v integer NOT NULL);
INSERT @T
(v)
VALUES
(1), (2), (3),
(4), (5), (6);
SELECT
T.v,
OA.i
FROM @T AS T
OUTER APPLY
(
SELECT TOP (1)
X.i
FROM
(
VALUES
(REPLICATE('Z', 1390)),
('0'), ('1'), ('2'), ('3'), ('4'),
('5'), ('6'), ('7'), ('8'), ('9')
) AS X (i)
ORDER BY NEWID()
) AS OA
OPTION (NO_PERFORMANCE_SPOOL); Los resultados que obtenga variarán de una ejecución a otra, pero aquí hay un ejemplo:
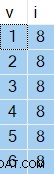
Lo interesante son los valores en la columna i siempre será el mismo, a pesar del ORDER BY NEWID() cláusula.
Probablemente ya habrá adivinado que la razón de esto es el Ordenar resultados de almacenamiento en caché (rebobinado). El plan de ejecución muestra el Análisis constante ejecutándose solo una vez, produciendo 11 filas en total:
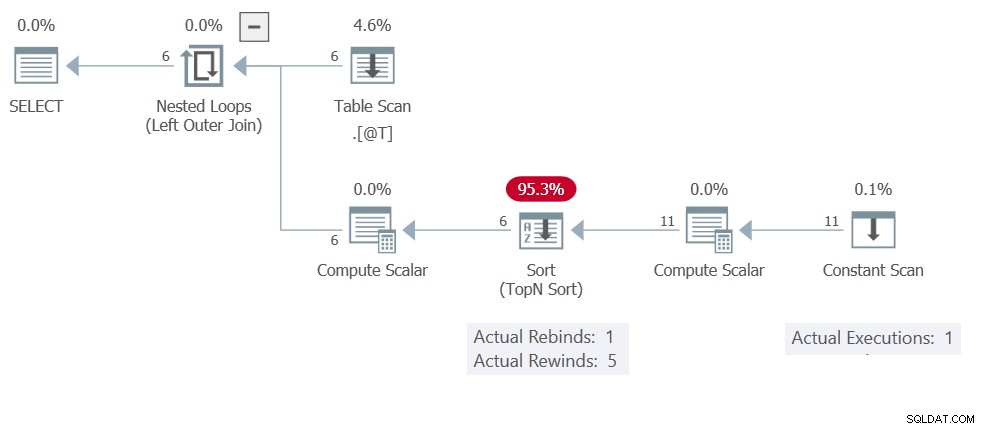
Este Orden solo tiene Calcular de cálculo y Escaneo constante operadores en su entrada por lo que es una Ordenación en memoria . Recuerde, estos no están limitados a una sola fila como máximo:pueden acomodar 500 filas y 16 KB.
Como se mencionó anteriormente, no es posible ver explícitamente si un Ordenar está en memoria o no mediante la inspección de un plan de ejecución regular. Necesitamos salida detallada del plan de presentación , habilitado con el indicador de seguimiento no documentado 8666. Con eso habilitado, aparecen propiedades adicionales del operador:
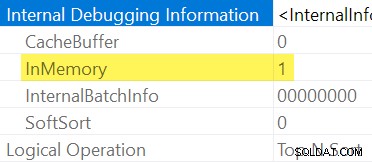
Cuando no es práctico usar indicadores de seguimiento no documentados, puede inferir que un Ordenar es "InMemory" por su Fracción de memoria de entrada siendo cero, y Uso de memoria los elementos no están disponibles en el plan de presentación posterior a la ejecución (en las versiones de SQL Server que admiten esa información).
Volviendo al plan de ejecución:no hay parámetros correlacionados, por lo que Ordenar es libre de rebobinar 5 veces, lo que significa que el Escaneo constante solo se ejecuta una vez. Siéntete libre de cambiar el TOP (1) a TOP (3) o lo que quieras El rebobinado significa que los resultados serán los mismos (almacenados en caché/rebobinados) para cada fila de entrada.
Puede que le moleste ORDER BY NEWID() cláusula que no impide el rebobinado. Este es de hecho un punto controvertido, pero no se limita en absoluto a clases. Para una discusión más completa (advertencia:posible agujero de conejo), consulte estas preguntas y respuestas. La versión corta es que esta es una decisión de diseño de producto deliberada, optimizando el rendimiento, pero hay planes para hacer que el comportamiento sea más intuitivo con el tiempo.
Demostración 6:Sin clasificación en memoria
Esto es lo mismo que la demostración 5, excepto que la cadena replicada es un carácter más larga:
DECLARE @T table (v integer NOT NULL);
INSERT @T
(v)
VALUES
(1), (2), (3),
(4), (5), (6);
SELECT
T.v,
OA.i
FROM @T AS T
OUTER APPLY
(
SELECT TOP (1)
X.i
FROM
(
VALUES
-- 1391 instead of 1390
(REPLICATE('Z', 1391)),
('0'), ('1'), ('2'), ('3'), ('4'),
('5'), ('6'), ('7'), ('8'), ('9')
) AS X (i)
ORDER BY NEWID()
) AS OA
OPTION (NO_PERFORMANCE_SPOOL);
Nuevamente, los resultados variarán según la ejecución, pero aquí hay un ejemplo. Observe la i los valores ya no son todos iguales:

El carácter adicional es suficiente para impulsar el tamaño estimado de los datos ordenados a más de 16 KB. Esto significa una clasificación en memoria no se puede utilizar y los rebobinados desaparecen.
El plan de ejecución es:
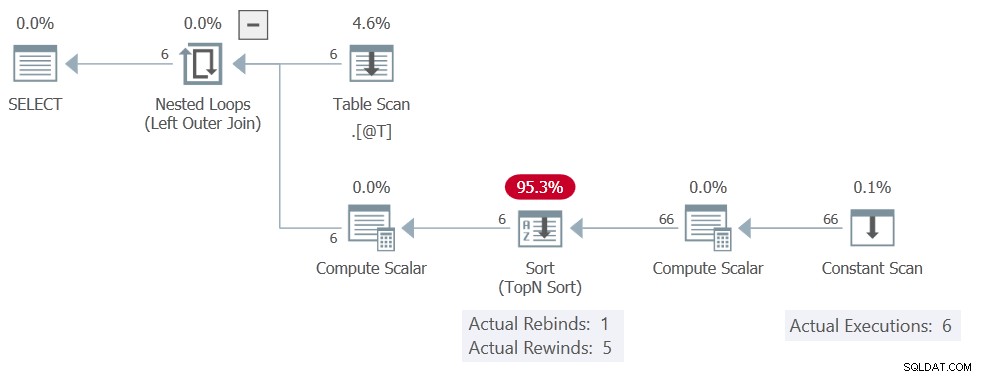
El Ordenar todavía informes 5 rebobinados, pero el Constant Scan se ejecuta 6 veces, lo que significa que realmente no se produjeron rebobinados. Produce las 11 filas en cada una de las 6 ejecuciones, dando un total de 66 filas.
Resumen y pensamientos finales
No verá un Ordenar operador de verdad rebobinando muy a menudo, aunque lo verás diciendo que lo hizo bastante.
Recuerde, una clasificación normal solo puede rebobinar si es seguro y hay un máximo de una fila en la ordenación en ese momento. Ser "seguro" significa que no hay cambios en los parámetros de correlación de bucle o nada por debajo del Ordenar se ve afectado por los cambios de parámetros.
Una clasificación en memoria puede operar en hasta 500 filas y 16 KB de datos provenientes de Constant Scan y Calcular escalar solo operadores. También se rebobinará solo cuando sea seguro (¡aparte de los errores del producto!) pero no se limita a un máximo de una fila.
Estos pueden parecer detalles esotéricos, y supongo que lo son. Dicho esto, me han ayudado a comprender un plan de ejecución y encontrar buenas mejoras de rendimiento más de una vez. Tal vez usted también encuentre útil la información algún día.
Esté atento a Tipos que producen más filas de las que tienen en su entrada!
Si desea ver un ejemplo más realista de Ordenar rebobina basado en una demostración que Itzik Ben-Gan proporcionó en la primera parte de su Partido más cercano series, consulte Coincidencia más cercana con Ordenar rebobinados.