Hace mucho tiempo, respondí una pregunta sobre NULL en Stack Exchange titulada "¿Por qué no deberíamos permitir NULL?" Tengo mi parte de manías y pasiones favoritas, y el miedo a los NULL está bastante arriba en mi lista. Un colega me dijo recientemente, después de expresar su preferencia por forzar una cadena vacía en lugar de permitir NULL:
"No me gusta lidiar con valores nulos en el código".
Lo siento, pero esa no es una buena razón. La forma en que la capa de presentación trata con cadenas vacías o valores NULL no debería ser el factor determinante para el diseño de la tabla y el modelo de datos. Y si está permitiendo una "falta de valor" en alguna columna, ¿le importa desde un punto de vista lógico si la "falta de valor" está representada por una cadena de longitud cero o NULL? O peor aún, ¿un valor simbólico como 0 o -1 para números enteros, o 1900-01-01 para fechas?
Itzik Ben-Gan escribió recientemente una serie completa sobre NULL, y recomiendo encarecidamente leerlo todo:
- Complejidades NULL:Parte 1
- Complejidades NULL - Parte 2
- Complejidades NULL:parte 3, características estándar faltantes y alternativas de T-SQL
- Complejidades NULL - Parte 4, Restricción única estándar faltante
Pero mi objetivo aquí es un poco menos complicado que eso, después de que el tema surgió en una pregunta diferente de Stack Exchange:"Agregar un campo automático ahora a una tabla existente". Allí, el usuario estaba agregando una nueva columna a una tabla existente, con la intención de completarla automáticamente con la fecha/hora actual. Se preguntaron si deberían dejar valores NULL en esa columna para todas las filas existentes o establecer un valor predeterminado (como 1900-01-01, presumiblemente, aunque no fueron explícitos).
Puede ser fácil para alguien que sepa filtrar filas antiguas en función de un valor de token; después de todo, ¿cómo podría alguien creer que se fabricó o compró algún tipo de accesorio Bluetooth el 1900-01-01? Bueno, he visto esto en los sistemas actuales donde usan una fecha que suena arbitraria en las vistas para actuar como un filtro mágico, presentando solo filas donde se puede confiar en el valor. De hecho, en todos los casos que he visto hasta ahora, la fecha en la cláusula WHERE es la fecha/hora en que se agregó la columna (o su restricción predeterminada). Lo cual está bien; tal vez no sea la mejor manera de resolver el problema, pero es a camino.
Sin embargo, si no está accediendo a la tabla a través de la vista, esta implicación de un conocido El valor aún puede causar problemas lógicos y relacionados con los resultados. El problema lógico es simplemente que alguien que interactúa con la tabla debe saber que 1900-01-01 es un valor simbólico falso que representa "desconocido" o "no relevante". Para un ejemplo del mundo real, ¿cuál fue la velocidad de lanzamiento promedio, en segundos, para un mariscal de campo que jugó en la década de 1970, antes de que midiéramos o rastreáramos tal cosa? ¿Es 0 un buen valor simbólico para "desconocido"? ¿Qué tal -1? ¿O 100? Volviendo a las fechas, si un paciente sin identificación ingresa en el hospital y está inconsciente, ¿qué debe ingresar como fecha de nacimiento? No creo que 1900-01-01 sea una buena idea, y ciertamente no fue una buena idea cuando era más probable que fuera una fecha de nacimiento real.
Implicaciones de rendimiento de los valores de token
Desde una perspectiva de rendimiento, los valores falsos o "token" como 1900-01-01 o 9999-21-31 pueden presentar problemas. Veamos un par de estos con un ejemplo basado libremente en la pregunta reciente mencionada anteriormente. Tenemos una tabla de Widgets y, después de algunas devoluciones de garantía, decidimos agregar una columna EnteredService donde ingresaremos la fecha/hora actual para nuevas filas. En un caso, dejaremos todas las filas existentes como NULL y, en el otro, actualizaremos el valor a nuestra fecha mágica 1900-01-01. (Dejaremos cualquier tipo de compresión fuera de la conversación por ahora).
CREATE TABLE dbo.Widgets_NULL
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WNULL PRIMARY KEY (WidgetID)
);
CREATE TABLE dbo.Widgets_Token
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WToken PRIMARY KEY (WidgetID)
); Ahora insertaremos las mismas 100.000 filas en cada tabla:
INSERT dbo.Widgets_NULL(Description)
OUTPUT inserted.Description INTO dbo.Widgets_Token(Description)
SELECT TOP (100000) LEFT(OBJECT_DEFINITION(o.object_id), 250)
FROM master.sys.all_objects AS o
CROSS JOIN (SELECT TOP (50) * FROM master.sys.all_objects) AS o2
WHERE o.[type] IN (N'P',N'FN',N'V')
AND OBJECT_DEFINITION(o.object_id) IS NOT NULL; Luego podemos agregar la nueva columna y actualizar el 10 % de los valores existentes con una distribución de fechas actuales, y el otro 90 % a nuestra fecha de token solo en una de las tablas:
ALTER TABLE dbo.Widgets_NULL ADD EnteredService datetime;
ALTER TABLE dbo.Widgets_Token ADD EnteredService datetime;
GO
UPDATE dbo.Widgets_NULL
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = '19000101'
WHERE WidgetID <= 90000; Finalmente, podemos agregar índices:
CREATE INDEX IX_EnteredService ON dbo.Widgets_NULL (EnteredService); CREATE INDEX IX_EnteredService ON dbo.Widgets_Token(EnteredService);
Espacio utilizado
Siempre escucho "el espacio en disco es barato" cuando hablamos de opciones de tipo de datos, fragmentación y valores de token frente a NULL. Mi preocupación no es tanto con el espacio en disco que ocupan estos valores adicionales sin sentido. Es más que, cuando se consulta la tabla, se está desperdiciando memoria. Aquí podemos tener una idea rápida de cuánto espacio consumen nuestros valores de token antes y después de agregar la columna y el índice:
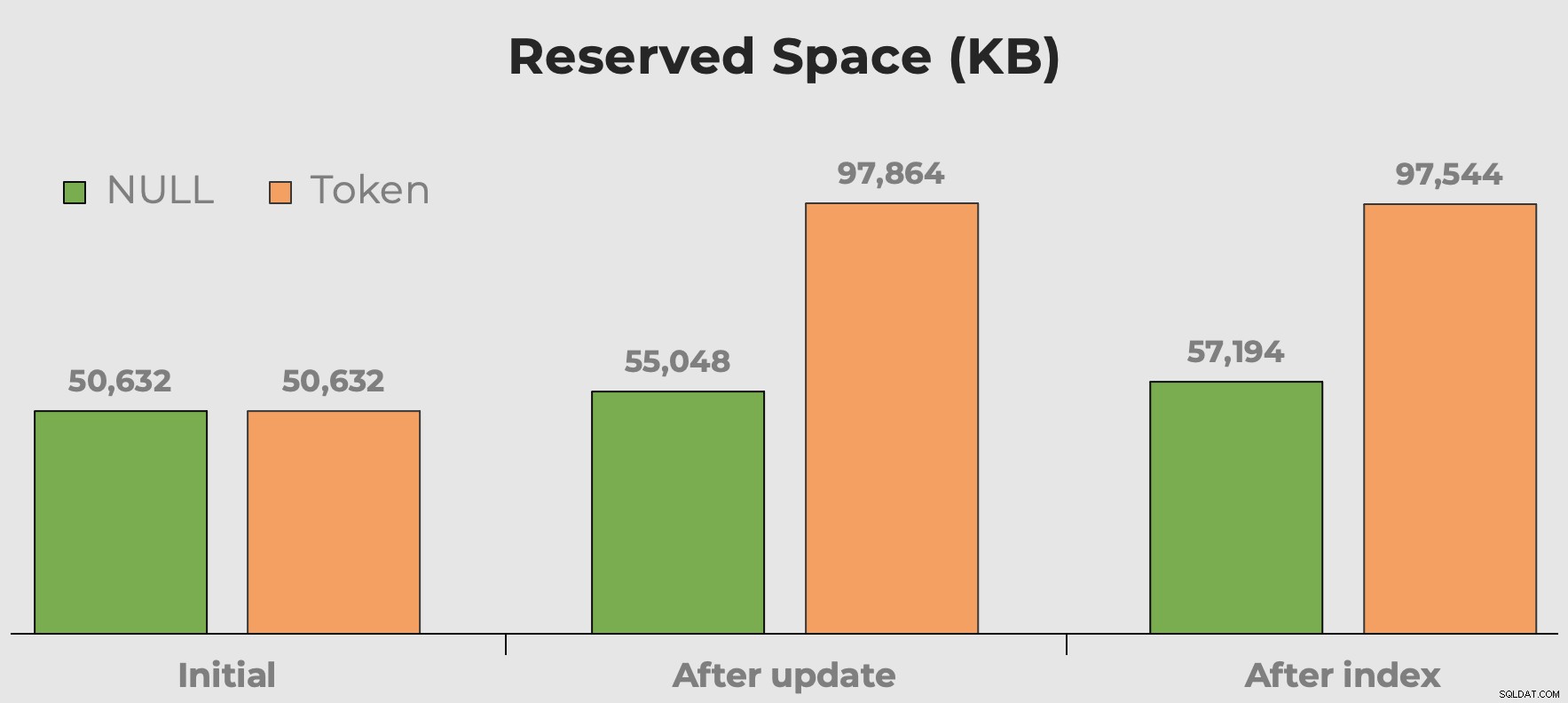 Espacio reservado de la tabla después de agregar una columna y agregar un índice. El espacio casi se duplica con los valores de los tokens.
Espacio reservado de la tabla después de agregar una columna y agregar un índice. El espacio casi se duplica con los valores de los tokens.
Ejecución de consultas
Inevitablemente, alguien hará suposiciones sobre los datos de la tabla y realizará consultas en la columna EnteredService como si todos los valores fueran legítimos. Por ejemplo:
SELECT COUNT(*) FROM dbo.Widgets_Token
WHERE EnteredService <= '20210101';
SELECT COUNT(*) FROM dbo.Widgets_NULL
WHERE EnteredService <= '20210101'; Los valores de los tokens pueden alterar las estimaciones en algunos casos pero, lo que es más importante, producirán resultados incorrectos (o al menos inesperados). Aquí está el plan de ejecución para la consulta contra la tabla con valores de token:
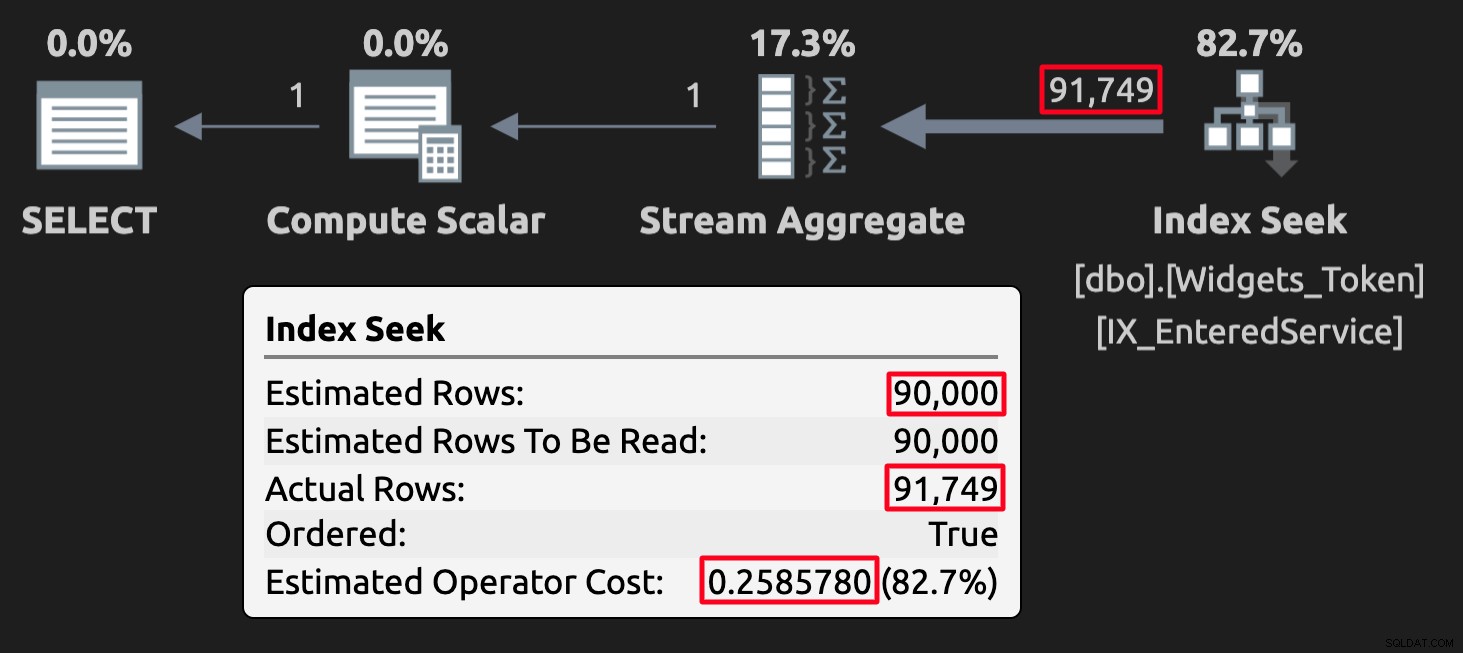 Plan de ejecución para la tabla de tokens; tenga en cuenta el alto costo.
Plan de ejecución para la tabla de tokens; tenga en cuenta el alto costo.
Y aquí está el plan de ejecución para la consulta contra la tabla con NULL:
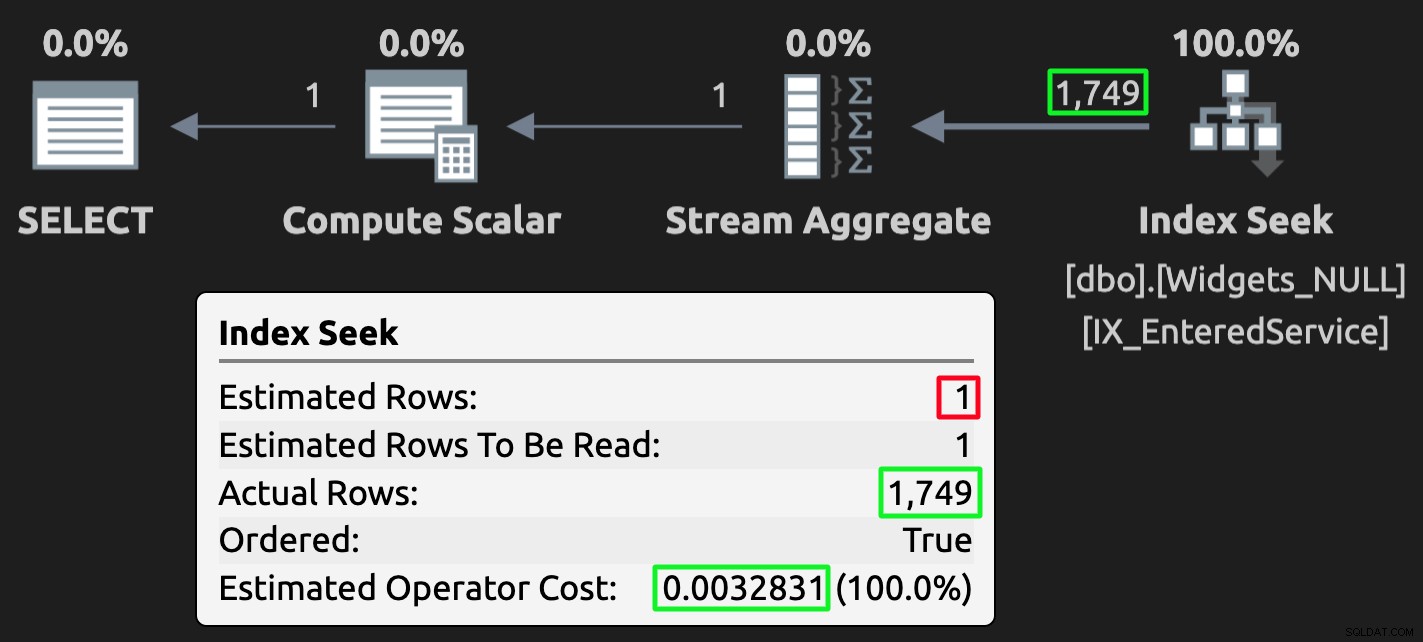 Plan de ejecución para la tabla NULL; estimación incorrecta, pero mucho menor costo.
Plan de ejecución para la tabla NULL; estimación incorrecta, pero mucho menor costo.
Lo mismo sucedería a la inversa si la consulta pidiera>={alguna fecha} y se usara 9999-12-31 como el valor mágico que representa desconocido.
Nuevamente, para las personas que saben que los resultados son incorrectos específicamente porque ha usado valores de token, esto no es un problema. Pero todos los demás que no saben eso, incluidos futuros colegas, otros herederos y mantenedores del código, e incluso usted en el futuro con problemas de memoria, probablemente van a tropezar.
Conclusión
La elección de permitir valores NULL en una columna (o evitar los valores NULL por completo) no debe reducirse a una decisión ideológica o basada en el miedo. Hay desventajas reales y tangibles en la arquitectura de su modelo de datos para asegurarse de que ningún valor pueda ser NULO, o en el uso de valores sin sentido para representar algo que fácilmente podría no haberse almacenado en absoluto. No estoy sugiriendo que todas las columnas de su modelo deban permitir valores NULL; solo que no te opongas a la idea de NULL.



