Combinaciones que regresan
Usando una tabla de números o un CTE generador de números, seleccione 0 a 2^n - 1. Usando las posiciones de bits que contienen 1 en estos números para indicar la presencia o ausencia de los miembros relativos en la combinación, y eliminando aquellos que no tienen el número correcto de valores, debería poder devolver un conjunto de resultados con todas las combinaciones que desee.
WITH Nums (Num) AS (
SELECT Num
FROM Numbers
WHERE Num BETWEEN 0 AND POWER(2, @n) - 1
), BaseSet AS (
SELECT ind = Power(2, Row_Number() OVER (ORDER BY Value) - 1), *
FROM @set
), Combos AS (
SELECT
ComboID = N.Num,
S.Value,
Cnt = Count(*) OVER (PARTITION BY N.Num)
FROM
Nums N
INNER JOIN BaseSet S ON N.Num & S.ind <> 0
)
SELECT
ComboID,
Value
FROM Combos
WHERE Cnt = @k
ORDER BY ComboID, Value;
Esta consulta funciona bastante bien, pero pensé en una forma de optimizarla, extrayéndome de Ingenioso recuento de bits en paralelo para obtener primero el número correcto de artículos tomados a la vez. Esto funciona de 3 a 3,5 veces más rápido (tanto en CPU como en tiempo):
WITH Nums AS (
SELECT Num, P1 = (Num & 0x55555555) + ((Num / 2) & 0x55555555)
FROM dbo.Numbers
WHERE Num BETWEEN 0 AND POWER(2, @n) - 1
), Nums2 AS (
SELECT Num, P2 = (P1 & 0x33333333) + ((P1 / 4) & 0x33333333)
FROM Nums
), Nums3 AS (
SELECT Num, P3 = (P2 & 0x0f0f0f0f) + ((P2 / 16) & 0x0f0f0f0f)
FROM Nums2
), BaseSet AS (
SELECT ind = Power(2, Row_Number() OVER (ORDER BY Value) - 1), *
FROM @set
)
SELECT
ComboID = N.Num,
S.Value
FROM
Nums3 N
INNER JOIN BaseSet S ON N.Num & S.ind <> 0
WHERE P3 % 255 = @k
ORDER BY ComboID, Value;
Fui y leí la página de conteo de bits y pensé que esto podría funcionar mejor si no hago el % 255 sino que hago todo el camino con la aritmética de bits. Cuando tenga la oportunidad, probaré eso y veré cómo se acumula.
Mis reclamos de rendimiento se basan en las consultas que se ejecutan sin la cláusula ORDER BY. Para mayor claridad, lo que hace este código es contar la cantidad de bits de 1 establecidos en Num de los Numbers mesa. Esto se debe a que el número se usa como una especie de indexador para elegir qué elementos del conjunto están en la combinación actual, por lo que el número de bits de 1 será el mismo.
¡Espero que te guste!
Para que conste, esta técnica de usar el patrón de bits de números enteros para seleccionar miembros de un conjunto es lo que he acuñado como "Unión cruzada vertical". Da como resultado efectivamente la unión cruzada de múltiples conjuntos de datos, donde el número de conjuntos y uniones cruzadas es arbitrario. Aquí, el número de conjuntos es el número de elementos tomados a la vez.
En realidad, la unión cruzada en el sentido horizontal habitual (de agregar más columnas a la lista existente de columnas con cada unión) se vería así:
SELECT
A.Value,
B.Value,
C.Value
FROM
@Set A
CROSS JOIN @Set B
CROSS JOIN @Set C
WHERE
A.Value = 'A'
AND B.Value = 'B'
AND C.Value = 'C'
Mis consultas anteriores efectivamente "unión cruzada" tantas veces como sea necesario con una sola unión. Los resultados no están pivotados en comparación con las uniones cruzadas reales, claro, pero eso es un asunto menor.
Crítica de su código
En primer lugar, puedo sugerir este cambio en su UDF factorial:
ALTER FUNCTION dbo.Factorial (
@x bigint
)
RETURNS bigint
AS
BEGIN
IF @x <= 1 RETURN 1
RETURN @x * dbo.Factorial(@x - 1)
END
Ahora puede calcular conjuntos de combinaciones mucho más grandes, además de que es más eficiente. Incluso podría considerar usar decimal(38, 0) para permitir cálculos intermedios más grandes en sus cálculos combinados.
En segundo lugar, su consulta dada no devuelve los resultados correctos. Por ejemplo, usando mis datos de prueba de las pruebas de rendimiento a continuación, el conjunto 1 es el mismo que el conjunto 18. Parece que su consulta toma una franja deslizante que se envuelve:cada conjunto siempre tiene 5 miembros adyacentes, con un aspecto similar a este (giré para que sea más fácil de ver):
1 ABCDE
2 ABCD Q
3 ABC PQ
4 AB OPQ
5 A NOPQ
6 MNOPQ
7 LMNOP
8 KLMNO
9 JKLMN
10 IJKLM
11 HIJKL
12 GHIJK
13 FGHIJ
14 EFGHI
15 DEFGH
16 CDEFG
17 BCDEF
18 ABCDE
19 ABCD Q
Compara el patrón de mis consultas:
31 ABCDE
47 ABCD F
55 ABC EF
59 AB DEF
61 A CDEF
62 BCDEF
79 ABCD G
87 ABC E G
91 AB DE G
93 A CDE G
94 BCDE G
103 ABC FG
107 AB D FG
109 A CD FG
110 BCD FG
115 AB EFG
117 A C EFG
118 BC EFG
121 A DEFG
...
Solo para llevar el patrón de bits -> índice de combinación a casa para cualquier persona interesada, observe que 31 en binario =11111 y el patrón es ABCDE. 121 en binario es 1111001 y el patrón es A__DEFG (mapeado hacia atrás).
Resultados de rendimiento con una tabla de números reales
Realicé algunas pruebas de rendimiento con conjuntos grandes en mi segunda consulta anterior. No tengo un registro en este momento de la versión del servidor utilizada. Aquí están mis datos de prueba:
DECLARE
@k int,
@n int;
DECLARE @set TABLE (value varchar(24));
INSERT @set VALUES ('A'),('B'),('C'),('D'),('E'),('F'),('G'),('H'),('I'),('J'),('K'),('L'),('M'),('N'),('O'),('P'),('Q');
SET @n = @@RowCount;
SET @k = 5;
DECLARE @combinations bigint = dbo.Factorial(@n) / (dbo.Factorial(@k) * dbo.Factorial(@n - @k));
SELECT CAST(@combinations as varchar(max)) + ' combinations', MaxNumUsedFromNumbersTable = POWER(2, @n);
Peter demostró que esta "unión cruzada vertical" no funciona tan bien como simplemente escribir SQL dinámico para hacer las UNIONES CRUZADAS que evita. Al costo trivial de algunas lecturas más, su solución tiene métricas entre 10 y 17 veces mejores. El rendimiento de su consulta disminuye más rápido que el mío a medida que aumenta la cantidad de trabajo, pero no lo suficientemente rápido como para evitar que alguien la use.
El segundo conjunto de números a continuación es el factor dividido por la primera fila de la tabla, solo para mostrar cómo se escala.
Erik
Items CPU Writes Reads Duration | CPU Writes Reads Duration
----- ------ ------ ------- -------- | ----- ------ ------ --------
17•5 7344 0 3861 8531 |
18•9 17141 0 7748 18536 | 2.3 2.0 2.2
20•10 76657 0 34078 84614 | 10.4 8.8 9.9
21•11 163859 0 73426 176969 | 22.3 19.0 20.7
21•20 142172 0 71198 154441 | 19.4 18.4 18.1
Pedro
Items CPU Writes Reads Duration | CPU Writes Reads Duration
----- ------ ------ ------- -------- | ----- ------ ------ --------
17•5 422 70 10263 794 |
18•9 6046 980 219180 11148 | 14.3 14.0 21.4 14.0
20•10 24422 4126 901172 46106 | 57.9 58.9 87.8 58.1
21•11 58266 8560 2295116 104210 | 138.1 122.3 223.6 131.3
21•20 51391 5 6291273 55169 | 121.8 0.1 613.0 69.5
Extrapolando, eventualmente mi consulta será más barata (aunque es desde el principio en lecturas), pero no por mucho tiempo. Para usar 21 elementos en el conjunto ya se requiere una tabla de números hasta 2097152...
Aquí hay un comentario que hice originalmente antes de darme cuenta de que mi solución funcionaría mucho mejor con una tabla de números sobre la marcha:
Resultados de rendimiento con una tabla de números sobre la marcha
Cuando originalmente escribí esta respuesta, dije:
Bueno, lo probé, ¡y los resultados fueron que funcionó mucho mejor! Esta es la consulta que utilicé:
DECLARE @N int = 16, @K int = 12;
CREATE TABLE #Set (Value char(1) PRIMARY KEY CLUSTERED);
CREATE TABLE #Items (Num int);
INSERT #Items VALUES (@K);
INSERT #Set
SELECT TOP (@N) V
FROM
(VALUES ('A'),('B'),('C'),('D'),('E'),('F'),('G'),('H'),('I'),('J'),('K'),('L'),('M'),('N'),('O'),('P'),('Q'),('R'),('S'),('T'),('U'),('V'),('W'),('X'),('Y'),('Z')) X (V);
GO
DECLARE
@N int = (SELECT Count(*) FROM #Set),
@K int = (SELECT TOP 1 Num FROM #Items);
DECLARE @combination int, @value char(1);
WITH L0 AS (SELECT 1 N UNION ALL SELECT 1),
L1 AS (SELECT 1 N FROM L0, L0 B),
L2 AS (SELECT 1 N FROM L1, L1 B),
L3 AS (SELECT 1 N FROM L2, L2 B),
L4 AS (SELECT 1 N FROM L3, L3 B),
L5 AS (SELECT 1 N FROM L4, L4 B),
Nums AS (SELECT Row_Number() OVER(ORDER BY (SELECT 1)) Num FROM L5),
Nums1 AS (
SELECT Num, P1 = (Num & 0x55555555) + ((Num / 2) & 0x55555555)
FROM Nums
WHERE Num BETWEEN 0 AND Power(2, @N) - 1
), Nums2 AS (
SELECT Num, P2 = (P1 & 0x33333333) + ((P1 / 4) & 0x33333333)
FROM Nums1
), Nums3 AS (
SELECT Num, P3 = (P2 & 0x0F0F0F0F) + ((P2 / 16) & 0x0F0F0F0F)
FROM Nums2
), BaseSet AS (
SELECT Ind = Power(2, Row_Number() OVER (ORDER BY Value) - 1), *
FROM #Set
)
SELECT
@Combination = N.Num,
@Value = S.Value
FROM
Nums3 N
INNER JOIN BaseSet S
ON N.Num & S.Ind <> 0
WHERE P3 % 255 = @K;
Tenga en cuenta que seleccioné los valores en variables para reducir el tiempo y la memoria necesarios para probar todo. El servidor todavía hace todo el mismo trabajo. Modifiqué la versión de Peter para que fuera similar y eliminé los extras innecesarios para que ambos fueran lo más reducidos posible. La versión del servidor utilizada para estas pruebas es Microsoft SQL Server 2008 (RTM) - 10.0.1600.22 (Intel X86) Standard Edition on Windows NT 5.2 <X86> (Build 3790: Service Pack 2) (VM) ejecutándose en una máquina virtual.
A continuación se muestran gráficos que muestran las curvas de rendimiento para valores de N y K hasta 21. Los datos básicos para ellos se encuentran en otra respuesta en esta página . Los valores son el resultado de 5 ejecuciones de cada consulta en cada valor K y N, seguidas de descartar los mejores y peores valores para cada métrica y promediar los 3 restantes.
Básicamente, mi versión tiene un "hombro" (en la esquina más a la izquierda del gráfico) con valores altos de N y valores bajos de K que hacen que funcione peor allí que la versión de SQL dinámico. Sin embargo, se mantiene bastante bajo y constante, y el pico central alrededor de N =21 y K =11 es mucho más bajo para la duración, la CPU y las lecturas que la versión de SQL dinámico.
Incluí un gráfico de la cantidad de filas que se espera que devuelva cada elemento para que pueda ver el rendimiento de la consulta comparado con el trabajo que tiene que hacer.
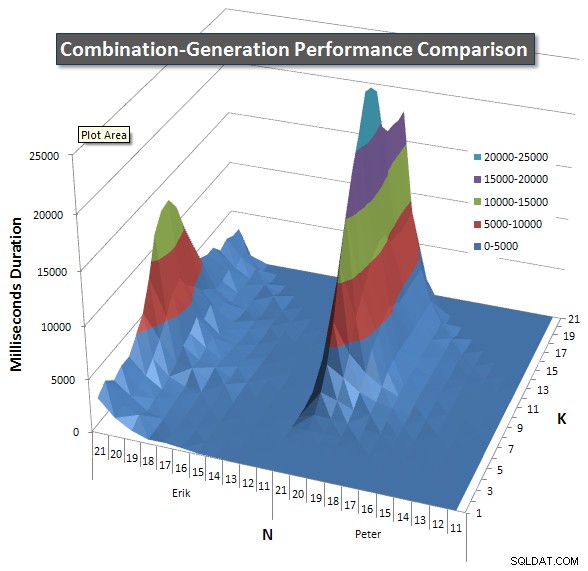
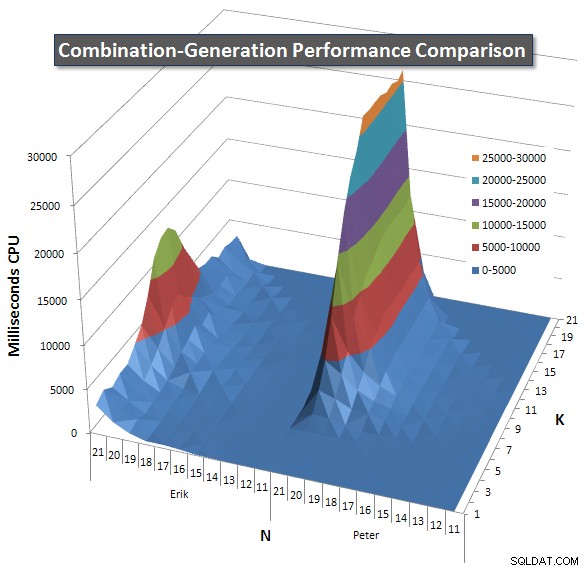
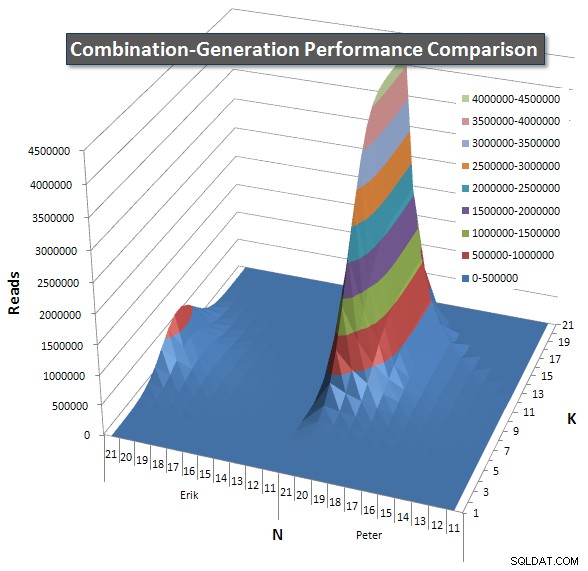
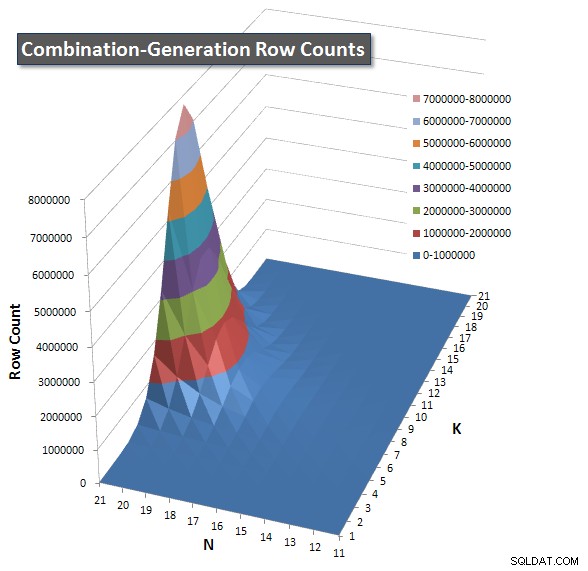
Consulte mi respuesta adicional en esta página para obtener los resultados de rendimiento completos. Alcancé el límite de caracteres de la publicación y no pude incluirlo aquí. (¿Alguna idea de dónde más ponerlo?) Para poner las cosas en perspectiva con respecto a los resultados de rendimiento de mi primera versión, este es el mismo formato que antes:
Erik
Items CPU Duration Reads Writes | CPU Duration Reads
----- ----- -------- ------- ------ | ----- -------- -------
17•5 354 378 12382 0 |
18•9 1849 1893 97246 0 | 5.2 5.0 7.9
20•10 7119 7357 369518 0 | 20.1 19.5 29.8
21•11 13531 13807 705438 0 | 38.2 36.5 57.0
21•20 3234 3295 48 0 | 9.1 8.7 0.0
Pedro
Items CPU Duration Reads Writes | CPU Duration Reads
----- ----- -------- ------- ------ | ----- -------- -------
17•5 41 45 6433 0 |
18•9 2051 1522 214021 0 | 50.0 33.8 33.3
20•10 8271 6685 864455 0 | 201.7 148.6 134.4
21•11 18823 15502 2097909 0 | 459.1 344.5 326.1
21•20 25688 17653 4195863 0 | 626.5 392.3 652.2
Conclusiones
- Las tablas de números sobre la marcha son mejores que una tabla real que contiene filas, ya que leer una con un gran número de filas requiere mucha E/S. Es mejor usar un poco de CPU.
- Mis pruebas iniciales no fueron lo suficientemente amplias como para mostrar realmente las características de rendimiento de las dos versiones.
- La versión de Peter podría mejorarse al hacer que cada JOIN no solo sea mayor que el elemento anterior, sino que también restrinja el valor máximo en función de cuántos elementos más deben caber en el conjunto. Por ejemplo, en 21 elementos tomados 21 a la vez, solo hay una respuesta de 21 filas (los 21 elementos, una vez), pero los conjuntos de filas intermedios en la versión SQL dinámica, al principio del plan de ejecución, contienen combinaciones como " AU" en el paso 2, aunque se descartará en la siguiente combinación, ya que no hay ningún valor superior a "U" disponible. De manera similar, un conjunto de filas intermedio en el paso 5 contendrá "ARSTU", pero el único combo válido en este punto es "ABCDE". Esta versión mejorada no tendría un pico más bajo en el centro, por lo que posiblemente no lo mejoraría lo suficiente como para convertirse en el claro ganador, pero al menos se volvería simétrico para que los gráficos no se mantuvieran al máximo más allá de la mitad de la región, sino que retrocederían. cerca de 0 como lo hace mi versión (vea la esquina superior de los picos para cada consulta).
Análisis de duración
- No hay una diferencia realmente significativa entre las versiones en duración (>100 ms) hasta 14 elementos tomados 12 a la vez. Hasta este punto, mi versión gana 30 veces y la versión SQL dinámica gana 43 veces.
- A partir de 14•12, mi versión fue 65 veces más rápida (59>100 ms), la versión SQL dinámica 64 veces (60>100 ms). Sin embargo, todas las veces que mi versión fue más rápida, ahorró una duración promedio total de 256,5 segundos, y cuando la versión SQL dinámica fue más rápida, ahorró 80,2 segundos.
- La duración promedio total de todas las pruebas fue Erik 270,3 segundos, Peter 446,2 segundos.
- Si se creara una tabla de búsqueda para determinar qué versión usar (seleccionando la más rápida para las entradas), todos los resultados podrían obtenerse en 188,7 segundos. Usar el más lento cada vez tomaría 527.7 segundos.
Análisis de lecturas
El análisis de duración mostró que mi consulta ganó por una cantidad significativa pero no demasiado grande. Cuando la métrica se cambia a lecturas, surge una imagen muy diferente:mi consulta usa en promedio 1/10 de las lecturas.
- No hay una diferencia realmente significativa entre las versiones en lecturas (>1000) hasta 9 elementos tomados 9 a la vez. Hasta este punto, mi versión gana 30 veces y la versión SQL dinámica gana 17 veces.
- A partir de 9•9, mi versión usó menos lecturas 118 veces (113>1000), la versión SQL dinámica 69 veces (31>1000). Sin embargo, todas las veces que mi versión utilizó menos lecturas, ahorró un promedio total de 75,9 millones de lecturas y, cuando la versión de SQL dinámico fue más rápida, ahorró 380 000 lecturas.
- El promedio total de lecturas para todas las pruebas fue Erik 8.4M, Peter 84M.
- Si se creara una tabla de búsqueda para determinar qué versión usar (elegir la mejor para las entradas), todos los resultados podrían obtenerse en 8 millones de lecturas. Usar el peor cada vez requeriría 84,3 millones de lecturas.
Estaría muy interesado en ver los resultados de una versión actualizada de SQL dinámico que pone el límite superior adicional en los elementos elegidos en cada paso como describí anteriormente.
Anexo
La siguiente versión de mi consulta logra una mejora de alrededor del 2,25 % con respecto a los resultados de rendimiento enumerados anteriormente. Usé el método de conteo de bits HAKMEM de MIT y agregué Convert(int) en el resultado de row_number() ya que devuelve un bigint. Por supuesto, desearía que esta sea la versión que usé para todas las pruebas de rendimiento, gráficos y datos anteriores, pero es poco probable que vuelva a hacerlo, ya que requería mucha mano de obra.
WITH L0 AS (SELECT 1 N UNION ALL SELECT 1),
L1 AS (SELECT 1 N FROM L0, L0 B),
L2 AS (SELECT 1 N FROM L1, L1 B),
L3 AS (SELECT 1 N FROM L2, L2 B),
L4 AS (SELECT 1 N FROM L3, L3 B),
L5 AS (SELECT 1 N FROM L4, L4 B),
Nums AS (SELECT Row_Number() OVER(ORDER BY (SELECT 1)) Num FROM L5),
Nums1 AS (
SELECT Convert(int, Num) Num
FROM Nums
WHERE Num BETWEEN 1 AND Power(2, @N) - 1
), Nums2 AS (
SELECT
Num,
P1 = Num - ((Num / 2) & 0xDB6DB6DB) - ((Num / 4) & 0x49249249)
FROM Nums1
),
Nums3 AS (SELECT Num, Bits = ((P1 + P1 / 8) & 0xC71C71C7) % 63 FROM Nums2),
BaseSet AS (SELECT Ind = Power(2, Row_Number() OVER (ORDER BY Value) - 1), * FROM #Set)
SELECT
N.Num,
S.Value
FROM
Nums3 N
INNER JOIN BaseSet S
ON N.Num & S.Ind <> 0
WHERE
Bits = @K
Y no pude resistirme a mostrar una versión más que hace una búsqueda para obtener el conteo de bits. Incluso puede ser más rápido que otras versiones:
DECLARE @BitCounts binary(255) =
0x01010201020203010202030203030401020203020303040203030403040405
+ 0x0102020302030304020303040304040502030304030404050304040504050506
+ 0x0102020302030304020303040304040502030304030404050304040504050506
+ 0x0203030403040405030404050405050603040405040505060405050605060607
+ 0x0102020302030304020303040304040502030304030404050304040504050506
+ 0x0203030403040405030404050405050603040405040505060405050605060607
+ 0x0203030403040405030404050405050603040405040505060405050605060607
+ 0x0304040504050506040505060506060704050506050606070506060706070708;
WITH L0 AS (SELECT 1 N UNION ALL SELECT 1),
L1 AS (SELECT 1 N FROM L0, L0 B),
L2 AS (SELECT 1 N FROM L1, L1 B),
L3 AS (SELECT 1 N FROM L2, L2 B),
L4 AS (SELECT 1 N FROM L3, L3 B),
L5 AS (SELECT 1 N FROM L4, L4 B),
Nums AS (SELECT Row_Number() OVER(ORDER BY (SELECT 1)) Num FROM L5),
Nums1 AS (SELECT Convert(int, Num) Num FROM Nums WHERE Num BETWEEN 1 AND Power(2, @N) - 1),
BaseSet AS (SELECT Ind = Power(2, Row_Number() OVER (ORDER BY Value) - 1), * FROM ComboSet)
SELECT
@Combination = N.Num,
@Value = S.Value
FROM
Nums1 N
INNER JOIN BaseSet S
ON N.Num & S.Ind <> 0
WHERE
@K =
Convert(int, Substring(@BitCounts, N.Num & 0xFF, 1))
+ Convert(int, Substring(@BitCounts, N.Num / 256 & 0xFF, 1))
+ Convert(int, Substring(@BitCounts, N.Num / 65536 & 0xFF, 1))
+ Convert(int, Substring(@BitCounts, N.Num / 16777216, 1))