La consulta 2 usa una variable.
En el momento en que se compila el lote, SQL Server no conoce el valor de la variable, por lo que recurre a una heurística muy similar a OPTIMIZE FOR (UNKNOWN)
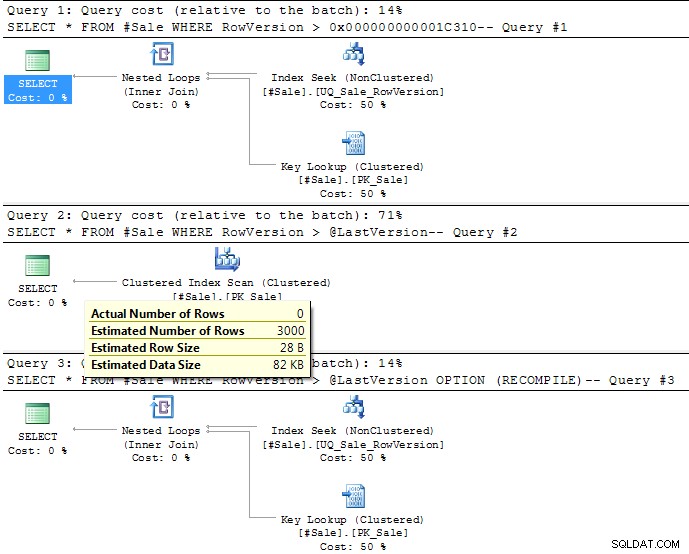
Para > asumirá que el 30% de las filas terminarán coincidiendo (o 3000 filas en sus datos de ejemplo). Esto se puede ver en la imagen del plan de ejecución como se muestra a continuación. Esto está significativamente por encima de las 12 filas (0,12 %), que es el punto de inflexión
para esta consulta si utiliza un análisis de índice agrupado o una búsqueda de índice no agrupado y búsquedas clave.
Tendrías que usar OPTION (RECOMPILE) para que tenga en cuenta el valor de la variable real, como se muestra en el tercer plan a continuación.
Guión
CREATE TABLE #Sale
(
SaleId INT IDENTITY(1, 1)
CONSTRAINT PK_Sale PRIMARY KEY,
Test1 VARCHAR(10) NULL,
RowVersion rowversion NOT NULL
CONSTRAINT UQ_Sale_RowVersion UNIQUE
)
/*A better way of populating the table!*/
INSERT INTO #Sale (Test1)
SELECT TOP 10000 NULL
FROM master..spt_values v1, master..spt_values v2
GO
SELECT *
FROM #Sale
WHERE RowVersion > 0x000000000001C310-- Query #1
DECLARE @LastVersion rowversion = 0x000000000001C310
SELECT *
FROM #Sale
WHERE RowVersion > @LastVersion-- Query #2
SELECT *
FROM #Sale
WHERE RowVersion > @LastVersion
OPTION (RECOMPILE)-- Query #3
DROP TABLE #Sale