Probablemente ya hayas encontrado una respuesta a tu pregunta. Esta respuesta es para ayudar a otros que puedan tropezar con esta pregunta. Aquí hay una opción posible que se puede usar para resolver la transferencia de datos usando SSIS. Supuse que aún puede crear cadenas de conexión que apunten a sus servidores A y B desde el paquete SSIS. Si esa suposición es incorrecta, hágamelo saber para que pueda eliminar esta respuesta. En este ejemplo, estoy usando SQL Server 2008 R2 como back-end. Como no tengo dos servidores, he creado dos tablas idénticas en diferentes Schemas ServidorA y ServidorB .
Proceso paso a paso:
-
En el
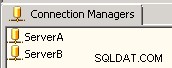
Connection managersección del SSIS, cree dos conexiones OLE DB, a saber, ServerA y ServidorB . Este ejemplo apunta al mismo servidor, pero en su escenario, las conexiones deberán apuntar a sus dos servidores diferentes. Consulte la captura de pantalla n.°1 . -
Cree dos esquemas
ServerAyServerB. Crea la tabladbo.ItemInfoen ambos esquemas. Los scripts para crear estas tablas se encuentran en Scripts. sección. Nuevamente, estos objetos son solo para este ejemplo. -
He llenado ambas tablas con algunos datos de muestra. Tabla
ServerA.ItemInfocontiene2,222 rowsy tablaServerB.ItemInfocontiene10,000 rows. Según la pregunta, los 7778 faltantes las filas deben transferirse desdeServerBaServerA. Consulte la captura de pantalla n.º 2 . -
En la pestaña de flujo de control del paquete SSIS, coloque una tarea de flujo de datos como se muestra en la captura de pantalla #3 .
-
Haga doble clic en la tarea de flujo de datos para navegar a la pestaña de flujo de datos y configurar la tarea de flujo de datos como se describe a continuación. Servidor B es un
OLE DB Source; Buscar registro en el Servidor A es unaLookup transformation tasky Servidor A es unOLE DB Destination. -
Configurar
OLE DB SourceServidor B como se muestra en las capturas de pantalla #4 y #5 . -
Configurar
Lookup transformation taskBuscar registro en el Servidor A como se muestra en las capturas de pantalla #6 - #8 . En este ejemplo, ItemId es la clave única. Por lo tanto, esa es la columna utilizada para buscar registros faltantes entre las dos tablas. Dado que solo necesitamos las filas que no existen en Servidor A , debemos seleccionar la opciónRedirect rows to no match output. -
Coloque un
OLE DB Destinationen la tarea de flujo de datos. Cuando conecte la tarea de transformación de búsqueda con el destino OLE DB, se le solicitaráInput Output Selectiondiálogo. SeleccioneLookup No Match Outputdesde el cuadro de diálogo como se muestra en la captura de pantalla #9 . Configure elOLE DB DestinationServidor A como se muestra en las capturas de pantalla #10 y #11 . -
Una vez que la tarea de flujo de datos esté configurada, debería verse como se muestra en la captura de pantalla #12 .
-
La ejecución de muestra del paquete se muestra en la captura de pantalla #13 . Como puede notar, las
7,778 rowsfaltantes han sido transferidos desdeServer BalServer A. Consulte la captura de pantalla #14 para ver el recuento de registros de la tabla después de la ejecución del paquete. -
Dado que el requisito era simplemente insertar los registros faltantes, se ha utilizado este enfoque. Si desea actualizar los registros existentes y eliminar los registros que ya no son válidos, consulte el ejemplo que proporcioné en este enlace. SQL Integration Services para cargar el archivo delimitado por tabulaciones? El ejemplo en el enlace muestra cómo transferir un archivo sin formato a SQL, pero actualiza los registros existentes y elimina los registros no válidos. Además, el ejemplo está ajustado para manejar una gran cantidad de filas.
Espero que ayude.
Guiones
.
CREATE SCHEMA [ServerA] AUTHORIZATION [dbo]
GO
CREATE SCHEMA [ServerB] AUTHORIZATION [dbo]
GO
CREATE TABLE [ServerA].[ItemInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemId] [varchar](255) NOT NULL,
[ItemName] [varchar](255) NOT NULL,
[ItemType] [varchar](255) NOT NULL,
CONSTRAINT [PK_ItemInfo] PRIMARY KEY CLUSTERED ([Id] ASC),
CONSTRAINT [UK_ItemInfo_ItemId] UNIQUE NONCLUSTERED ([ItemId] ASC)
) ON [PRIMARY]
GO
CREATE TABLE [ServerB].[ItemInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemId] [varchar](255) NOT NULL,
[ItemName] [varchar](255) NOT NULL,
[ItemType] [varchar](255) NOT NULL,
CONSTRAINT [PK_ItemInfo] PRIMARY KEY CLUSTERED ([Id] ASC),
CONSTRAINT [UK_ItemInfo_ItemId] UNIQUE NONCLUSTERED ([ItemId] ASC)
) ON [PRIMARY]
GO
Captura de pantalla n.º 1:
Captura de pantalla n.º 2:

Captura de pantalla n.º 3:

Captura de pantalla n.º 4:

Captura de pantalla n.º 5:

Captura de pantalla n.º 6:

Captura de pantalla n.º 7:

Captura de pantalla n.º 8:

Captura de pantalla n.º 9:

Captura de pantalla n.º 10:

Captura de pantalla n.º 11:

Captura de pantalla n.º 12:
Captura de pantalla n.º 13:

Captura de pantalla n.º 14: