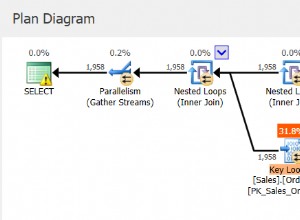
Si la tabla en sí está agrupada , todos los índices secundarios contienen una copia de la clave de agrupación (una clave que determina el orden físico de las filas en la tabla agrupada).
La razón:las filas en una tabla agrupada se almacenan físicamente dentro de un árbol B (no en un montón de tablas) y, por lo tanto, pueden mover cuando los nodos del árbol B se dividen o fusionan, por lo que el índice secundario no puede contener simplemente el "puntero" de fila (ya que estaría en peligro de "colgarse" después de que la fila se mueva).
A menudo, eso tiene un efecto perjudicial en el rendimiento:la consulta a través del índice secundario puede requerir una búsqueda doble :
- Primero, busque en el índice secundario y obtenga la clave de agrupación.
- En segundo lugar, en función de la clave de agrupamiento recuperada anteriormente, busque en la tabla agrupada en sí (que es el árbol B).
Sin embargo, si todo lo que desea son los campos de la clave de agrupación, solo se necesita la primera búsqueda.
También conocido como "índice agrupado" en MS SQL Server.
Por lo general, pero no necesariamente, una CLAVE PRINCIPAL en MS SQL Server.
Es lamentable que la agrupación en clústeres esté activada de forma predeterminada en MS SQL Server:la gente a menudo simplemente deja el valor predeterminado sin considerar completamente sus efectos. Cuando la agrupación en clústeres no sea adecuada, debe especificar la palabra clave NONCLUSTERED explícitamente para desactivarla.