Introducción a la recopilación masiva de PL/SQL
Una consulta bien estructurada, escrita hoy, podría salvarlo de eventos catastróficos en el futuro. El rendimiento de las consultas es algo que todos buscamos, pero muy pocos realmente lo encuentran. Aprender pequeños conceptos podría ayudarlo a adquirir experiencia, lo que podría conducir a una mejor habilidad para escribir consultas. Hoy en este blog vas a aprender uno de esos pequeños conceptos que es la “Recolección masiva ”.
La recopilación masiva se trata de reducir los cambios de contexto y mejorando el rendimiento de la consulta. Por lo tanto, para comprender qué es la recopilación masiva, primero debemos aprender qué es Cambio de contexto ?
¿Qué es el cambio de contexto?
Cada vez que escribe un bloque PL/SQL o dice un programa PL/SQL y lo ejecuta, el motor de tiempo de ejecución PL/SQL comienza a procesarlo línea por línea. Este motor procesa todas las sentencias PL/SQL por sí mismo, pero pasa todas las sentencias SQL que ha codificado en ese bloque PL/SQL al motor de tiempo de ejecución de SQL. Esas declaraciones SQL luego serán procesadas por separado por el motor SQL. Una vez que termina de procesarlos, el motor SQL devuelve el resultado al motor PL/SQL. De modo que este último pueda producir un resultado combinado. Este cambio de control de un lado a otro se denomina cambio de contexto.
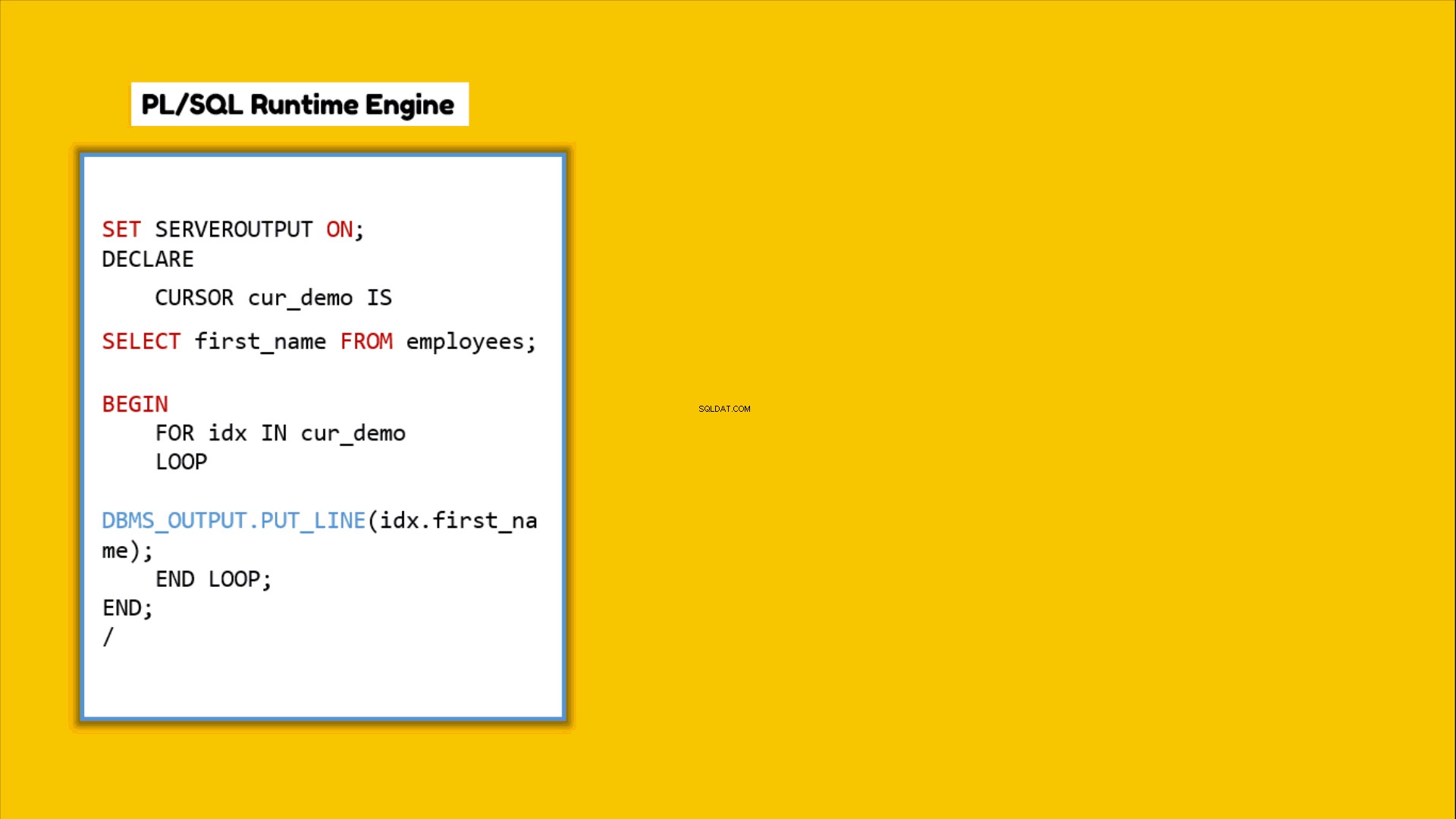
¿Cómo afecta el cambio de contexto al rendimiento de las consultas?
El cambio de contexto tiene un impacto directo en el rendimiento de la consulta. Cuanto mayor sea el salto de los controles, mayor será la sobrecarga que, a su vez, degradará el rendimiento. Esto significa que cuanto menor sea el cambio de contexto, mejor será el rendimiento de la consulta.
Ahora debes estar pensando "¿No podemos hacer algo al respecto?" ¿Podemos reducir esas transiciones de control? ¿Hay alguna forma de reducir los cambios de contexto? La respuesta a todas esas preguntas es sí, tenemos una opción que puede ayudarnos. Esa opción es la cláusula Bulk Collect .
¿Qué es la cláusula de cobro masivo?
La cláusula de recopilación masiva comprime varios conmutadores en un solo conmutador de contexto y aumenta la eficiencia y el rendimiento de un programa PL/SQL.
La cláusula de recopilación masiva reduce los saltos de control múltiples al recopilar todas las llamadas de instrucciones SQL del programa PL/SQL y enviarlas a SQL Engine de una sola vez y viceversa.
¿Dónde podemos usar la cláusula Bulk Collect?
La cláusula de recopilación masiva se puede utilizar con las cláusulas SELECT-INTO, FETCH-INTO y RETURN-INTO.
Con la ayuda de Bulk Collect Statement, podemos SELECCIONAR, INSERTAR, ACTUALIZAR o ELIMINAR grandes conjuntos de datos de objetos de la base de datos, como tablas o vistas.
¿Qué es el procesamiento masivo de datos?
El proceso de obtener lotes de datos del motor de tiempo de ejecución PL/SQL al motor SQL y viceversa se denomina Procesamiento de datos masivos.
¿Cuántas declaraciones de procesamiento masivo de datos tenemos?
Tenemos una cláusula de procesamiento masivo de datos que es Bulk Collect y una declaración de procesamiento masivo de datos que es FORALL en Oracle Database.
He oído que la cláusula de recopilación masiva utiliza cursores tanto implícitos como explícitos.
Sí, has escuchado bien. Podemos usar la cláusula de recopilación masiva dentro de una declaración SQL o con la declaración FETCH. Cuando usamos la cláusula de recopilación masiva con la instrucción SQL, es decir, SELECCIONAR EN, usa el cursor implícito. Mientras que si usamos la cláusula de recopilación masiva con la declaración FETCH, usa un cursor explícito.
Esta fue una introducción rápida a la primera cláusula de procesamiento de datos masivos de PL/SQL, que es BULK COLLECT. Aprenderemos sobre la segunda declaración de procesamiento de datos masivos una vez que hayamos terminado con la primera. Mientras tanto, asegúrese de suscribirse a nuestro canal de YouTube porque en el próximo tutorial aprenderemos cómo podemos mejorar la eficiencia de una instrucción SQL utilizando una cláusula de recopilación masiva.
¡Gracias y que tengas un gran día!