¡Tener cuidado! La expresión regexp_substr del formato '[^,]+' no devolverá el valor esperado si hay un elemento nulo en la lista y desea ese elemento o uno posterior. Considere este ejemplo donde el cuarto elemento es NULL y quiero el quinto elemento y, por lo tanto, espero que se devuelva el '5':
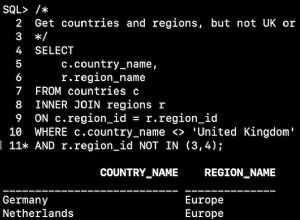
SQL> select regexp_substr('1,2,3,,5,6', '[^,]+', 1, 5) from dual;
R
-
6
¡Sorpresa! ¡Devuelve el quinto elemento NO NULO, no el quinto elemento real! Se devolvieron datos incorrectos y es posible que ni siquiera los detecte. Prueba esto en su lugar:
SQL> select regexp_substr('1,2,3,,5,6', '(.*?)(,|$)', 1, 5, NULL, 1) from dual;
R
-
5
Entonces, el REGEXP_SUBSTR corregido anteriormente dice que busque la quinta aparición de 0 o más caracteres delimitados por comas seguidos de una coma o el final de la línea (permite el siguiente separador, ya sea una coma o el final de la línea) y cuando se encuentra, devuelve el primer subgrupo (los datos NO incluyen la coma o el final de la línea).
El patrón de coincidencia de búsqueda '(.*?)(,|$)' explicó:
( = Start a group
. = match any character
* = 0 or more matches of the preceding character
? = Match 0 or 1 occurrences of the preceding pattern
) = End the 1st group
( = Start a new group (also used for logical OR)
, = comma
| = OR
$ = End of the line
) = End the 2nd group
EDITAR:se agregó más información y se simplificó la expresión regular.
Consulte esta publicación para obtener más información y una sugerencia para encapsular esto en una función para una fácil reutilización:REGEX para seleccionar el valor n de una lista, lo que permite valores nulos. Es la publicación donde descubrí el formato '[^,]+' tiene el problema Desafortunadamente, es el formato de expresiones regulares que verá con mayor frecuencia como la respuesta a las preguntas sobre cómo analizar una lista. Me estremezco al pensar en todos los datos incorrectos que devuelve '[^,]+' !