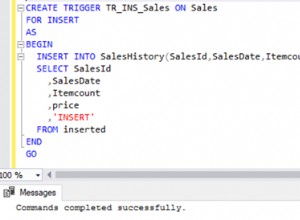
He tenido la oportunidad de jugar con esto, y mis comentarios anteriores sobre NOT IN son una pista falsa en este caso. La clave es la presencia de valores NULL, o más bien si las columnas indexadas tienen restricciones NOT NULL aplicadas.
Esto dependerá de la versión de la base de datos que esté utilizando, porque el optimizador se vuelve más inteligente con cada versión. Estoy usando 11gR1 y el optimizador usó el índice en todos los casos excepto en uno:cuando ambas columnas eran nulas y no incluí el NOT IN cláusula:
SQL> desc big_table
Name Null? Type
----------------------------------- ------ -------------------
ID NUMBER
COL1 NUMBER
COL2 VARCHAR2(30 CHAR)
COL3 DATE
COL4 NUMBER
Sin la cláusula NOT IN...
SQL> explain plan for
2 select col4, count(col1) from big_table
3 group by col4
4 /
Explained.
SQL> select * from table(dbms_xplan.display)
2 /
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------------------
Plan hash value: 1753714399
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 31964 | 280K| | 7574 (2)| 00:01:31 |
| 1 | HASH GROUP BY | | 31964 | 280K| 45M| 7574 (2)| 00:01:31 |
| 2 | TABLE ACCESS FULL| BIG_TABLE | 2340K| 20M| | 4284 (1)| 00:00:52 |
----------------------------------------------------------------------------------------
9 rows selected.
SQL>
Cuando doblé el NOT IN cláusula de nuevo, el optimizador optó por utilizar el índice. Extraño.
SQL> explain plan for
2 select col4, count(col1) from big_table
3 where col1 not in (12, 19)
4 group by col4
5 /
Explained.
SQL> select * from table(dbms_xplan.display)
2 /
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------------------
Plan hash value: 343952376
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 31964 | 280K| | 5057 (3)| 00:01:01 |
| 1 | HASH GROUP BY | | 31964 | 280K| 45M| 5057 (3)| 00:01:01 |
|* 2 | INDEX FAST FULL SCAN| BIG_I2 | 2340K| 20M| | 1767 (2)| 00:00:22 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------
2 - filter("COL1"<>12 AND "COL1"<>19)
14 rows selected.
SQL>
Solo para repetir, en todos los demás casos, siempre que una de las columnas indexadas se declarara no nula, el índice se usó para satisfacer la consulta. Puede que esto no sea cierto en versiones anteriores de Oracle, pero probablemente indique el camino a seguir.