Parece que tienes varias preguntas, así que intentemos desglosarlas.
Importación en HDFS
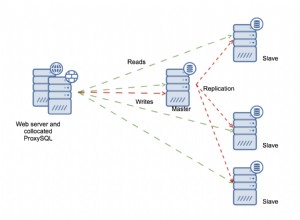
Parece que estás buscando Sqoop . Sqoop es una herramienta que le permite transferir fácilmente datos dentro y fuera de HDFS y puede conectarse a varias bases de datos, incluido Oracle de forma nativa. Sqoop es compatible con el controlador delgado Oracle JDBC. Así es como se transferiría de Oracle a HDFS:
sqoop import --connect jdbc:oracle:example@sqldat.com:1521/db --username xxx --password yyy --table tbl --target-dir /path/to/dir
Para más información:aquí y aquí . Tenga en cuenta que también puede importar directamente a una tabla de Hive con Sqoop, lo que podría ser conveniente para realizar su análisis.
Procesamiento
Como notó, dado que sus datos inicialmente son relacionales, es una buena idea usar Hive para hacer su análisis, ya que es posible que esté más familiarizado con la sintaxis similar a SQL. Pig es más álgebra relacional pura y la sintaxis NO es similar a SQL, es más una cuestión de preferencia, pero ambos enfoques deberían funcionar bien.
Dado que puede importar datos a Hive directamente con Sqoop, sus datos deberían estar listos para ser procesados directamente después de importarlos.
En Hive, puede ejecutar su consulta y decirle que escriba los resultados en HDFS:
hive -e "insert overwrite directory '/path/to/output' select * from mytable ..."
Exportación a TeraData
Cloudera lanzó el año pasado un conector para Teradata para Sqoop como se describe aquí , por lo que debería echar un vistazo, ya que parece exactamente lo que desea. Así es como lo haría:
sqoop export --connect jdbc:teradata://localhost/DATABASE=MY_BASE --username sqooptest --password xxxxx --table MY_DATA --export-dir /path/to/hive/output
Definitivamente, todo es factible en cualquier período de tiempo que desee, al final, lo que importará es el tamaño de su clúster, si lo desea rápido, amplíe su clúster según sea necesario. Lo bueno de Hive y Sqoop es que el procesamiento se distribuirá en su clúster, por lo que tiene control total sobre la programación.