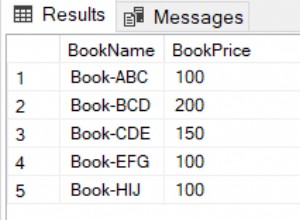
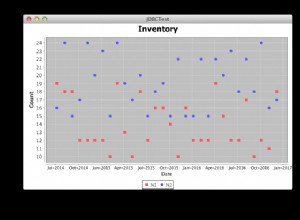
Parece ser una buena variante en caso de que haya un índice en al menos effective_start_date y effective_end_date campos de per_all_people_f mesa.
La variante ideal para esta consulta es
create index x_per_all_people_search on per_all_people_f(
effective_start_date,
effective_end_date,
person_id,
emp_flag
)
pero puede ser demasiado costoso de mantener (costo del disco, velocidad de inserción).
Además, el cursor en el cuerpo del paquete debe contener una subconsulta y reutilizar los resultados de la llamada a la función:
cursor cur_var
is
select
EMP_2012,
EMP_2013,
(EMP_2013 - EMP_2012) Diff
from (
select
function_name('01-MAR-2012','31-MAY-2012') EMP_2012,
function_name('01-MAR-2013','31-MAY-2013') EMP_2013
from dual
);
Por supuesto, la mejor solución es minimizar los cambios de contexto y obtener todos los valores de una sola consulta SQL. Además, puede proporcionar parámetros directamente al cursor:
cursor cur_var(
start_1 date, end_1 date,
start_2 date, end_2 date
)
is
select
EMP_2012,
EMP_2013,
(EMP_2013 - EMP_2012) Diff
from (
select
(
select
count(distinct papf.person_id)
from
per_all_people_f papf
where
papf.emp_flag = 'Y'
and
effective_start_date >= trunc(start_1)
and
effective_end_date <= trunc(end_1)
) EMP_2012,
(
select
count(distinct papf.person_id)
from
per_all_people_f papf
where
papf.emp_flag = 'Y'
and
effective_start_date >= trunc(start_2)
and
effective_end_date <= trunc(end_2)
) EMP_2013
from dual
);
Desde mi punto de vista, los parámetros de función/cursor son demasiado genéricos, puede ser mejor crear un contenedor que tome como parámetros de entrada un trimestre y dos años para comparar.
Y por último, si los resultados planeados para usarse en PL/SQL (supongo que debido a que devuelve una sola fila) no use el cursor en absoluto, solo devuelva los valores calculados a través de los parámetros de salida. Desde otro punto de vista, si necesita obtener datos trimestrales para todo el año en un solo cursor, puede ser más eficiente contar todos los trimestres y compararlos en una sola consulta.