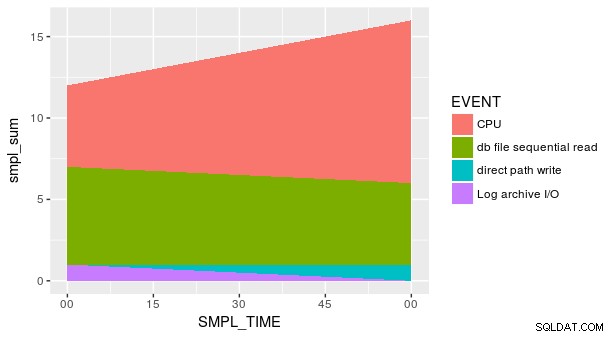
Comenzaré con la segunda pregunta, que es más fácil. Usando el dplyr paquete, puede usar top_n para obtener las n filas más grandes para una columna dada. Por ejemplo:
> top_n(p_ash_r_100a, 3, SMPL_CNT) %>% arrange(desc(SMPL_CNT))
# A tibble: 3 × 5
SMPL_TIME SQL_ID MODULE EVENT SMPL_CNT
<dttm> <chr> <chr> <chr> <int>
1 2017-04-11 09:01:00 NO_SQL GoldenGate CPU 7
2 2017-04-11 09:00:00 dgzp3at57cagd GoldenGate db file sequential read 2
3 2017-04-11 09:01:00 37cspa0acgqxp GoldenGate db file sequential read 2
Tenga en cuenta que obtendrá más de n filas si hay empates en el enésimo lugar. Así top_n(p_ash_r_100, 10, SMPL_CNT) devolverá el conjunto completo de datos de muestra debido al empate de 17 vías para el cuarto.
En cuanto a la primera pregunta, la documentación para geom_area proporciona una pista:
Esto sugiere que geom_area espera que la columna asignada a x sea numérica. Basado en la lista de p_ash_r_100 , SMPL_TIME parece ser un vector de caracteres. Con el lubridate paquete, podemos convertir SMPL_TIME a una fecha-hora con dmy_hm :
p_ash_r_100a <- p_ash_r_100 %>%
mutate_at(vars(SMPL_TIME), dmy_hm)
Sin embargo, esto no es suficiente para obtener el gráfico que desea, ya que hay múltiples valores de y para cada combinación de x y fill (que es la estética correcta para geom_area , no "col "). Necesitamos resumir los datos antes de trazar:
p_ash_r_100a %>%
group_by(SMPL_TIME, EVENT) %>%
summarise(total = sum(SMPL_CNT)) %>%
ggplot(aes(SMPL_TIME, total, fill = EVENT)) +
geom_area()
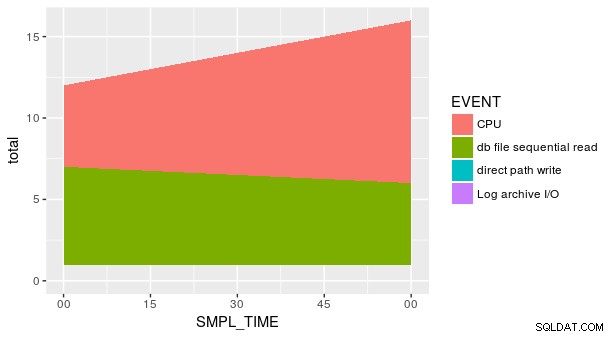
Sin embargo, la trama sigue sin ser correcta. Esto se debe a que cada combinación de SMPL_TIME y EVENT no está representado en el conjunto de datos. Necesitamos decirle explícitamente a geom_area que y es igual a cero para las filas que faltan. Una forma es usar el útil fill argumento en tidyr::spread .
group_by(p_ash_r_100a, SMPL_TIME, EVENT) %>%
summarise(smpl_sum = sum(SMPL_CNT)) %>%
spread(EVENT, smpl_sum, fill = 0) %>%
gather(EVENT, smpl_sum, CPU, `db file sequential read`,
`direct path write`,
`Log archive I/O`) %>%
ggplot(aes(x = SMPL_TIME, y = smpl_sum, fill = EVENT)) +
geom_area()