El rendimiento es extremadamente importante en muchos productos de consumo como el comercio electrónico, los sistemas de pago, los juegos, las aplicaciones de transporte, etc. Aunque las bases de datos se optimizan internamente a través de múltiples mecanismos para cumplir con sus requisitos de rendimiento en el mundo moderno, mucho depende también del desarrollador de la aplicación; después de todo, solo un desarrollador sabe qué consultas debe realizar la aplicación.
Los desarrolladores que trabajan con bases de datos relacionales han usado o al menos han oído hablar de la indexación, y es un concepto muy común en el mundo de las bases de datos. Sin embargo, la parte más importante es comprender qué indexar y cómo la indexación aumentará el tiempo de respuesta de la consulta. Para hacerlo, debe comprender cómo consultará las tablas de su base de datos. Solo se puede crear un índice adecuado cuando sabe exactamente cómo son sus consultas y patrones de acceso a datos.
En terminología simple, un índice asigna claves de búsqueda a los datos correspondientes en el disco mediante diferentes estructuras de datos en memoria y en disco. El índice se usa para acelerar la búsqueda al reducir el número de registros a buscar.
En su mayoría, se crea un índice en las columnas especificadas en WHERE cláusula de una consulta a medida que la base de datos recupera y filtra datos de las tablas en función de esas columnas. Si no crea un índice, la base de datos escanea todas las filas, filtra las filas coincidentes y devuelve el resultado. Con millones de registros, esta operación de escaneo puede demorar muchos segundos y este alto tiempo de respuesta hace que las API y las aplicaciones sean más lentas e inutilizables. Veamos un ejemplo —
Usaremos MySQL con un motor de base de datos InnoDB predeterminado, aunque los conceptos explicados en este artículo son más o menos los mismos en otros servidores de bases de datos como Oracle, MSSQL, etc.
Crea una tabla llamada index_demo con el siguiente esquema:
CREATE TABLE index_demo (
name VARCHAR(20) NOT NULL,
age INT,
pan_no VARCHAR(20),
phone_no VARCHAR(20)
);¿Cómo verificamos que estamos usando el motor InnoDB?
Ejecute el siguiente comando:
SHOW TABLE STATUS WHERE name = 'index_demo' \G;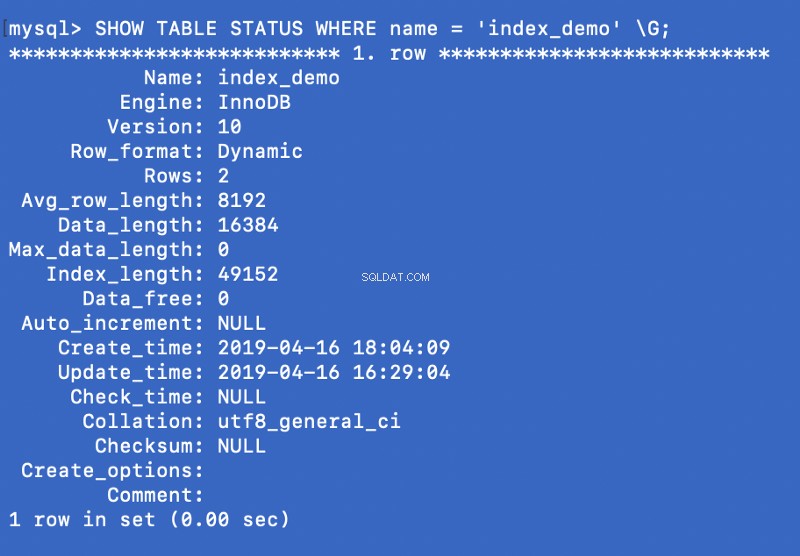
El Engine La columna de la captura de pantalla anterior representa el motor que se utiliza para crear la tabla. Aquí InnoDB se utiliza.
Ahora inserte algunos datos aleatorios en la tabla, mi tabla con 5 filas se ve así:
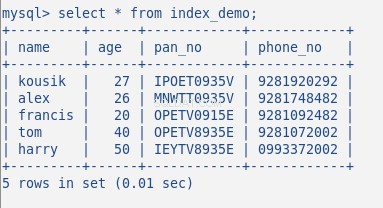
No he creado ningún índice hasta ahora en esta tabla. Verifiquemos esto con el comando:SHOW INDEX . Devuelve 0 resultados.

En este momento, si ejecutamos un simple SELECT consulta, dado que no hay un índice definido por el usuario, la consulta escaneará toda la tabla para encontrar el resultado:
EXPLAIN SELECT * FROM index_demo WHERE name = 'alex';
EXPLAIN muestra cómo el motor de consultas planea ejecutar la consulta. En la captura de pantalla anterior, puede ver que las rows columna devuelve 5 &possible_keys devuelve null . possible_keys representa todos los índices disponibles que se pueden usar en esta consulta. La key columna representa qué índice se utilizará realmente de todos los índices posibles en esta consulta.
Clave principal:
La consulta anterior es muy ineficiente. Optimicemos esta consulta. Haremos el phone_no columna a PRIMARY KEY suponiendo que no pueden existir dos usuarios en nuestro sistema con el mismo número de teléfono. Tenga en cuenta lo siguiente al crear una clave principal:
- Una clave principal debe ser parte de muchas consultas vitales en su aplicación.
- La clave principal es una restricción que identifica de manera única cada fila en una tabla. Si varias columnas forman parte de la clave principal, esa combinación debe ser única para cada fila.
- La clave principal debe ser no nula. Nunca haga de los campos nulos su clave principal. Según los estándares ANSI SQL, las claves principales deben ser comparables entre sí, y definitivamente debería poder saber si el valor de la columna de la clave principal para una fila en particular es mayor, menor o igual que el mismo de otra fila. Desde
NULLsignifica un valor indefinido en los estándares SQL, no puede comparar de forma deterministaNULLcon cualquier otro valor, por lo que lógicamenteNULLno está permitido. - El tipo de clave principal ideal debería ser un número como
INToBIGINTporque las comparaciones de enteros son más rápidas, por lo que atravesar el índice será muy rápido.
A menudo definimos un id campo como AUTO INCREMENT en las tablas y utilícelo como clave principal, pero la elección de una clave principal depende de los desarrolladores.
¿Qué pasa si no creas ninguna clave principal tú mismo?
No es obligatorio crear una clave principal usted mismo. Si no ha definido ninguna clave principal, InnoDB implícitamente crea una para usted porque, por diseño, InnoDB debe tener una clave principal en cada tabla. Entonces, una vez que crea una clave principal más adelante para esa tabla, InnoDB elimina la clave principal previamente definida automáticamente.
Como no tenemos ninguna clave principal definida a partir de ahora, veamos qué creó InnoDB por defecto para nosotros:
SHOW EXTENDED INDEX FROM index_demo;
EXTENDED muestra todos los índices que no son utilizables por el usuario pero administrados completamente por MySQL.
Aquí vemos que MySQL ha definido un índice compuesto (hablaremos de los índices compuestos más adelante) en DB_ROW_ID , DB_TRX_ID , DB_ROLL_PTR y todas las columnas definidas en la tabla. En ausencia de una clave principal definida por el usuario, este índice se utiliza para buscar registros de forma única.
¿Cuál es la diferencia entre clave e índice?
Aunque los términos key &index se usan indistintamente, key significa una restricción impuesta sobre el comportamiento de la columna. En este caso, la restricción es que la clave principal es un campo no nulo que identifica de forma única cada fila. Por otro lado, index es una estructura de datos especial que facilita la búsqueda de datos en la tabla.
Ahora vamos a crear el índice principal en phone_no &examinar el índice creado:
ALTER TABLE index_demo ADD PRIMARY KEY (phone_no);
SHOW INDEXES FROM index_demo;
Tenga en cuenta que CREATE INDEX no se puede usar para crear un índice principal, pero ALTER TABLE se utiliza.

En la captura de pantalla anterior, vemos que se crea un índice principal en la columna phone_no . Las columnas de las siguientes imágenes se describen a continuación:
Table :La tabla en la que se crea el índice.
Non_unique :Si el valor es 1, el índice no es único, si el valor es 0, el índice es único.
Key_name :El nombre del índice creado. El nombre del índice principal siempre es PRIMARY en MySQL, independientemente de si proporcionó algún nombre de índice o no al crear el índice.
Seq_in_index :El número de secuencia de la columna en el índice. Si varias columnas forman parte del índice, el número de secuencia se asignará en función de cómo se ordenaron las columnas durante el tiempo de creación del índice. El número de secuencia comienza desde 1.
Collation :cómo se ordena la columna en el índice. A significa ascendente, D significa descender, NULL significa no ordenado.
Cardinality :el número estimado de valores únicos en el índice. Más cardinalidad significa mayores posibilidades de que el optimizador de consultas elija el índice para las consultas.
Sub_part :El prefijo del índice. Es NULL si toda la columna está indexada. De lo contrario, muestra el número de bytes indexados en caso de que la columna esté parcialmente indexada. Definiremos el índice parcial más adelante.
Packed :Indica cómo se empaqueta la llave; NULL si no lo es.
Null :YES si la columna puede contener NULL valores y en blanco si no es así.
Index_type :indica qué estructura de datos de indexación se utiliza para este índice. Algunos posibles candidatos son:BTREE , HASH , RTREE o FULLTEXT .
Comment :La información sobre el índice no descrita en su propia columna.
Index_comment :El comentario para el índice especificado cuando creó el índice con COMMENT atributo.
Ahora veamos si este índice reduce el número de filas que se buscarán para un determinado phone_no en el WHERE cláusula de una consulta.
EXPLAIN SELECT * FROM index_demo WHERE phone_no = '9281072002';
En esta instantánea, observe que las rows la columna ha devuelto 1 solo, las possible_keys &key ambos devuelven PRIMARY . Entonces, esencialmente significa que usar el índice principal llamado PRIMARY (el nombre se asigna automáticamente cuando crea la clave principal), el optimizador de consultas simplemente va directamente al registro y lo obtiene. Es muy eficiente. Esto es exactamente para lo que sirve un índice:minimizar el alcance de la búsqueda a costa de espacio adicional.
Índice agrupado:
Un clustered index se coloca con los datos en el mismo espacio de tablas o en el mismo archivo de disco. Puede considerar que un índice agrupado es un B-Tree índice cuyos nodos hoja son los bloques de datos reales en el disco, ya que el índice y los datos residen juntos. Este tipo de índice organiza físicamente los datos en el disco según el orden lógico de la clave de índice.
¿Qué significa organización de datos físicos?
Físicamente, los datos se organizan en el disco en miles o millones de discos/bloques de datos. Para un índice agrupado, no es obligatorio que todos los bloques de disco se almacenen de forma contagiosa. Los bloques de datos físicos se mueven todo el tiempo aquí y allá por el sistema operativo cuando es necesario. Un sistema de base de datos no tiene ningún control absoluto sobre cómo se administra el espacio de datos físicos, pero dentro de un bloque de datos, los registros se pueden almacenar o administrar en el orden lógico de la clave de índice. El siguiente diagrama simplificado lo explica:
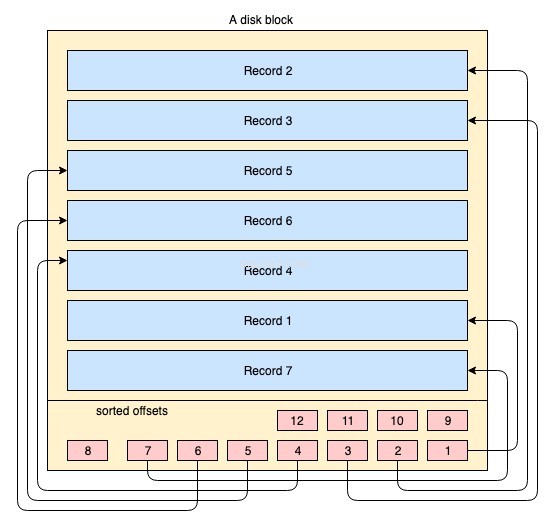
- El rectángulo grande de color amarillo representa un bloque de disco/bloque de datos
- los rectángulos de color azul representan datos almacenados como filas dentro de ese bloque
- el área de pie de página representa el índice del bloque donde residen pequeños rectángulos de color rojo en el orden ordenado de una clave en particular. Estos pequeños bloques no son más que una especie de punteros que apuntan a las compensaciones de los registros.
Los registros se almacenan en el bloque de disco en cualquier orden arbitrario. Cada vez que se agregan nuevos registros, se agregan en el siguiente espacio disponible. Cada vez que se actualiza un registro existente, el sistema operativo decide si ese registro aún puede caber en la misma posición o se debe asignar una nueva posición para ese registro.
Por lo tanto, la posición de los registros es manejada completamente por el sistema operativo y no existe una relación definida entre el orden de dos registros. Para recuperar los registros en el orden lógico de la clave, las páginas del disco contienen una sección de índice en el pie de página, el índice contiene una lista de punteros de desplazamiento en el orden de la clave. Cada vez que se modifica o crea un registro, se ajusta el índice.
De esta manera, realmente no necesita preocuparse por organizar el registro físico en un orden determinado, sino que se mantiene una pequeña sección de índice en ese orden y obtener o mantener registros se vuelve muy fácil.
Ventaja del índice agrupado:
Esta ordenación o ubicación conjunta de datos relacionados en realidad hace que un índice agrupado sea más rápido. Cuando se obtienen datos del disco, el sistema lee el bloque completo que contiene los datos, ya que nuestro sistema de E/S del disco escribe y lee datos en bloques. Entonces, en el caso de consultas de rango, es muy posible que los datos colocados se almacenen en la memoria. Digamos que activa la siguiente consulta:
SELECT * FROM index_demo WHERE phone_no > '9010000000' AND phone_no < '9020000000'
Un bloque de datos se recupera en la memoria cuando se ejecuta la consulta. Digamos que el bloque de datos contiene phone_no en el rango de 9010000000 a 9030000000 . Entonces, cualquier rango que haya solicitado en la consulta es solo un subconjunto de los datos presentes en el bloque. Si ahora lanza la siguiente consulta para obtener todos los números de teléfono en el rango, digamos desde 9015000000 al 9019000000 , no necesita obtener más bloques del disco. Los datos completos se pueden encontrar en el bloque de datos actual, por lo tanto clustered_index reduce la cantidad de E/S de disco colocando datos relacionados tanto como sea posible en el mismo bloque de datos. Esta E/S de disco reducida provoca una mejora en el rendimiento.
Entonces, si tiene una buena idea de la clave principal y sus consultas se basan en la clave principal, el rendimiento será súper rápido.
Restricciones del índice agrupado:
Dado que un índice agrupado afecta la organización física de los datos, solo puede haber un índice agrupado por tabla.
Relación entre la clave principal y el índice agrupado:
No puede crear un índice agrupado manualmente usando InnoDB en MySQL. MySQL lo elige por ti. Pero, ¿cómo elige? Los siguientes extractos son de la documentación de MySQL:
Cuando defines unaPRIMARY KEYen tu mesa,InnoDBlo usa como el índice agrupado. Defina una clave principal para cada tabla que cree. Si no hay una columna lógica única y no nula o un conjunto de columnas, agregue una nueva columna de incremento automático, cuyos valores se completan automáticamente.
Si no define unaPRIMARY KEYpara su tabla, MySQL localiza el primerUNIQUEíndice donde todas las columnas clave sonNOT NULLyInnoDBlo usa como el índice agrupado.
Si la tabla no tienePRIMARY KEYo adecuadoUNIQUEíndice,InnoDBgenera internamente un índice agrupado oculto llamadoGEN_CLUST_INDEXen una columna sintética que contiene valores de ID de fila. Las filas están ordenadas por el ID queInnoDBasigna a las filas de dicha tabla. El ID de fila es un campo de 6 bytes que aumenta de forma monótona a medida que se insertan nuevas filas. Por lo tanto, las filas ordenadas por ID de fila están físicamente en orden de inserción.
En resumen, el motor MySQL InnoDB en realidad administra el índice principal como un índice agrupado para mejorar el rendimiento, por lo que la clave principal y el registro real en el disco se agrupan juntos.
Estructura del índice de clave principal (agrupado):
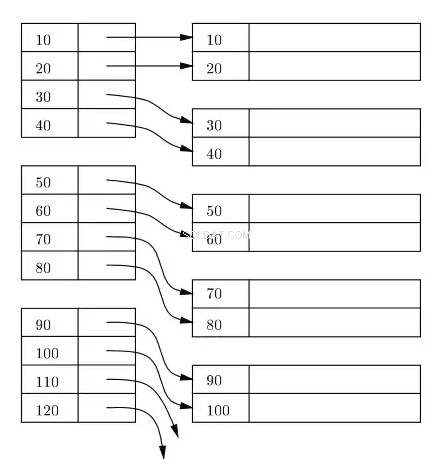
Un índice generalmente se mantiene como un árbol B+ en el disco y en la memoria, y cualquier índice se almacena en bloques en el disco. Estos bloques se denominan bloques de índice. Las entradas en el bloque de índice siempre se ordenan en la clave de índice/búsqueda. El bloque de índice de hoja del índice contiene un localizador de filas. Para el índice principal, el localizador de filas se refiere a la dirección virtual de la ubicación física correspondiente de los bloques de datos en el disco donde residen las filas que se ordenan según la clave de índice.
En el siguiente diagrama, los rectángulos del lado izquierdo representan bloques de índice de nivel de hoja y los rectángulos del lado derecho representan los bloques de datos. Lógicamente, los bloques de datos parecen estar alineados en un orden ordenado, pero como ya se describió anteriormente, las ubicaciones físicas reales pueden estar dispersas aquí y allá.
¿Es posible crear un índice primario en una clave no primaria?
En MySQL, un índice principal se crea automáticamente y ya hemos descrito anteriormente cómo MySQL elige el índice principal. Pero en el mundo de las bases de datos, en realidad no es necesario crear un índice en la columna de clave principal; el índice principal también se puede crear en cualquier columna de clave no principal. Pero cuando se crea en la clave principal, todas las entradas de clave son únicas en el índice, mientras que en el otro caso, el índice principal también puede tener una clave duplicada.
¿Es posible eliminar una clave principal?
Es posible eliminar una clave principal. Cuando elimina una clave principal, el índice agrupado relacionado y la propiedad de unicidad de esa columna se pierden.
ALTER TABLE `index_demo` DROP PRIMARY KEY;
- If the primary key does not exist, you get the following error:
"ERROR 1091 (42000): Can't DROP 'PRIMARY'; check that column/key exists"Ventajas del índice primario:
- Las consultas de rango basadas en el índice primario son muy eficientes. Puede existir la posibilidad de que el bloque de disco que la base de datos ha leído del disco contenga todos los datos que pertenecen a la consulta, ya que el índice principal está agrupado y los registros están ordenados físicamente. Entonces, la localidad de los datos puede ser proporcionada por el índice principal.
- Cualquier consulta que aproveche la clave principal es muy rápida.
Desventajas del índice primario:
- Dado que el índice principal contiene una referencia directa a la dirección del bloque de datos a través del espacio de direcciones virtuales y los bloques de disco están organizados físicamente en el orden de la clave de índice, cada vez que el sistema operativo realiza alguna división de página de disco debido a
DMLoperaciones comoINSERT/UPDATE/DELETE, el índice principal también debe actualizarse. EntoncesDMLlas operaciones ejercen cierta presión sobre el rendimiento del índice principal.
Índice secundario:
Cualquier índice que no sea un índice agrupado se denomina índice secundario. Los índices secundarios no afectan las ubicaciones de almacenamiento físico a diferencia de los índices primarios.
¿Cuándo necesita un índice secundario?
Es posible que tenga varios casos de uso en su aplicación en los que no consulta la base de datos con una clave principal. En nuestro ejemplo phone_no es la clave principal, pero es posible que necesitemos consultar la base de datos con pan_no , o name . En tales casos, necesita índices secundarios en estas columnas si la frecuencia de tales consultas es muy alta.
¿Cómo crear un índice secundario en MySQL?
El siguiente comando crea un índice secundario en el name columna en el index_demo mesa.
CREATE INDEX secondary_idx_1 ON index_demo (name);
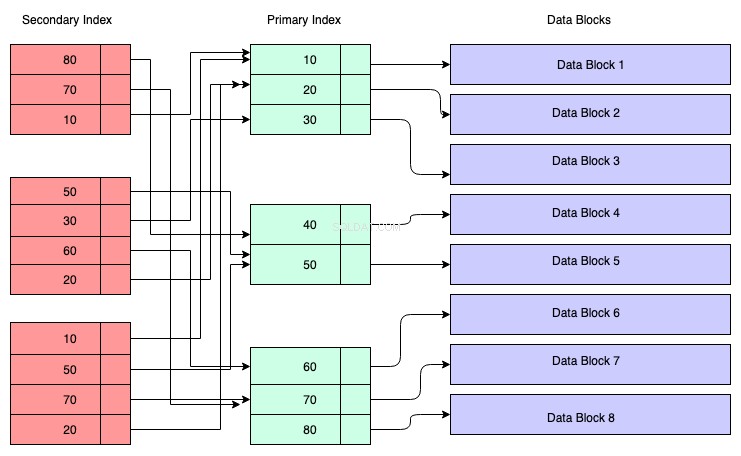
Estructura del índice secundario:
En el siguiente diagrama, los rectángulos de color rojo representan bloques de índice secundarios. El índice secundario también se mantiene en el Árbol B+ y se ordena según la clave en la que se creó el índice. Los nodos hoja contienen una copia de la clave de los datos correspondientes en el índice principal.
Entonces, para entender, puede suponer que el índice secundario tiene una referencia a la dirección de la clave principal, aunque no es el caso. La recuperación de datos a través del índice secundario significa que tiene que atravesar dos árboles B+:uno es el árbol B+ del índice secundario y el otro es el árbol B+ del índice primario.
Ventajas de un índice secundario:
Lógicamente puedes crear tantos índices secundarios como quieras. Pero, en realidad, cuántos índices realmente se requieren requiere un proceso de reflexión serio, ya que cada índice tiene su propia penalización.
Desventajas de un índice secundario:
Con DML operaciones como DELETE / INSERT , el índice secundario también debe actualizarse para que la copia de la columna de la clave principal se pueda eliminar/insertar. En tales casos, la existencia de muchos índices secundarios puede crear problemas.
Además, si una clave principal es muy grande como una URL , dado que los índices secundarios contienen una copia del valor de la columna de clave principal, puede ser ineficaz en términos de almacenamiento. Más claves secundarias significan una mayor cantidad de copias duplicadas del valor de la columna de la clave principal, por lo tanto, más almacenamiento en el caso de una clave principal grande. Además, la clave principal en sí misma almacena las claves, por lo que el efecto combinado en el almacenamiento será muy alto.
Consideraciones antes de eliminar un índice principal:
En MySQL, puede eliminar un índice principal eliminando la clave principal. Ya hemos visto que un índice secundario depende de un índice primario. Entonces, si elimina un índice principal, todos los índices secundarios deben actualizarse para que contengan una copia de la nueva clave de índice principal que MySQL ajusta automáticamente.
Este proceso es costoso cuando existen varios índices secundarios. Además, otras tablas pueden tener una referencia de clave externa a la clave principal, por lo que debe eliminar esas referencias de clave externa antes de eliminar la clave principal.
Cuando se elimina una clave principal, MySQL crea automáticamente otra clave principal internamente, y esa es una operación costosa.
Índice de clave ÚNICA:
Al igual que las claves primarias, las claves únicas también pueden identificar registros de forma única con una diferencia:la columna de clave única puede contener null valores.
A diferencia de otros servidores de bases de datos, en MySQL una columna de clave única puede tener tantos null valores como sea posible. En el estándar SQL, null significa un valor indefinido. Entonces, si MySQL tiene que contener solo un null valor en una columna de clave única, tiene que asumir que todos los valores nulos son iguales.
Pero lógicamente esto no es correcto ya que null significa indefinido, y los valores indefinidos no se pueden comparar entre sí, es la naturaleza de null . Como MySQL no puede afirmar si todo null significa lo mismo, permite múltiples null valores en la columna.
El siguiente comando muestra cómo crear un índice de clave único en MySQL:
CREATE UNIQUE INDEX unique_idx_1 ON index_demo (pan_no);
Índice compuesto:
MySQL le permite definir índices en múltiples columnas, hasta 16 columnas. Este índice se denomina índice multicolumna/compuesto/compuesto.
Digamos que tenemos un índice definido en 4 columnas:col1 , col2 , col3 , col4 . Con un índice compuesto, tenemos capacidad de búsqueda en col1 , (col1, col2) , (col1, col2, col3) , (col1, col2, col3, col4) . Entonces podemos usar cualquier prefijo del lado izquierdo de las columnas indexadas, pero no podemos omitir una columna del medio y usar eso como - (col1, col3) o (col1, col2, col4) o col3 o col4 etc. Estas son combinaciones no válidas.
Los siguientes comandos crean 2 índices compuestos en nuestra tabla:
CREATE INDEX composite_index_1 ON index_demo (phone_no, name, age);
CREATE INDEX composite_index_2 ON index_demo (pan_no, name, age);
Si tiene consultas que contienen un WHERE cláusula en varias columnas, escriba la cláusula en el orden de las columnas del índice compuesto. El índice beneficiará esa consulta. De hecho, mientras decide las columnas para un índice compuesto, puede analizar diferentes casos de uso de su sistema e intentar determinar el orden de las columnas que beneficiará a la mayoría de sus casos de uso.
Los índices compuestos pueden ayudarte en JOIN &SELECT consultas también. Ejemplo:en el siguiente SELECT * consulta, composite_index_2 se utiliza.

Cuando se definen varios índices, el optimizador de consultas de MySQL elige el índice que elimina la mayor cantidad de filas o escanea la menor cantidad de filas posible para una mayor eficiencia.
Por que usamos indices compuestos ? ¿Por qué no definir múltiples índices secundarios en las columnas que nos interesan?
MySQL usa solo un índice por tabla por consulta excepto UNION. (En UNION, cada consulta lógica se ejecuta por separado y los resultados se fusionan). Por lo tanto, definir varios índices en varias columnas no garantiza que esos índices se utilizarán incluso si son parte de la consulta.
MySQL mantiene algo llamado estadísticas de índice que ayuda a MySQL a inferir cómo se ven los datos en el sistema. Sin embargo, las estadísticas de índice son una generalización, pero en función de estos metadatos, MySQL decide qué índice es apropiado para la consulta actual.
¿Cómo funciona el índice compuesto?
Las columnas utilizadas en los índices compuestos se concatenan juntas y esas claves concatenadas se almacenan ordenadas mediante un árbol B+. Cuando realiza una búsqueda, la concatenación de sus claves de búsqueda se compara con las del índice compuesto. Luego, si hay alguna discrepancia entre el orden de las claves de búsqueda y el orden de las columnas del índice compuesto, no se puede usar el índice.
En nuestro ejemplo, para el siguiente registro, se forma una clave de índice compuesto concatenando pan_no , name , age — HJKXS9086Wkousik28 .
+--------+------+------------+------------+
name
age
pan_no
phone_no
+--------+------+------------+------------+
kousik
28
HJKXS9086W
9090909090Cómo identificar si necesita un índice compuesto:
- Analice sus consultas primero de acuerdo con sus casos de uso. Si ve que ciertos campos aparecen juntos en muchas consultas, puede considerar crear un índice compuesto.
- Si está creando un índice en
col1&un índice compuesto en (col1,col2), entonces solo el índice compuesto debería estar bien.col1solo puede ser atendido por el índice compuesto en sí mismo, ya que es un prefijo del lado izquierdo del índice. - Considere la cardinalidad. Si las columnas utilizadas en el índice compuesto terminan teniendo una alta cardinalidad juntas, son buenas candidatas para el índice compuesto.
Índice de cobertura:
Un índice de cobertura es un tipo especial de índice compuesto donde todas las columnas especificadas en la consulta existen en alguna parte del índice. Por lo tanto, el optimizador de consultas no necesita acceder a la base de datos para obtener los datos, sino que obtiene el resultado del índice mismo. Ejemplo:ya hemos definido un índice compuesto en (pan_no, name, age) , así que ahora considere la siguiente consulta:
SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = 'kousik'
Las columnas mencionadas en SELECT &WHERE Las cláusulas son parte del índice compuesto. Entonces, en este caso, podemos obtener el valor de age columna del propio índice compuesto. Veamos lo que EXPLAIN el comando muestra para esta consulta:
EXPLAIN FORMAT=JSON SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = '111kousik1';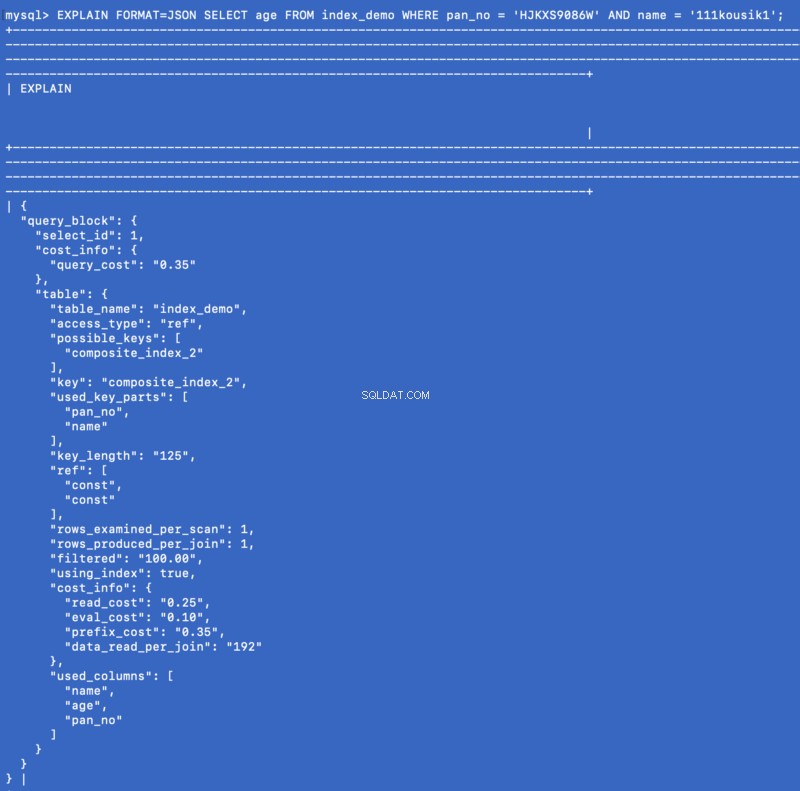
En la respuesta anterior, tenga en cuenta que hay una clave:using_index que se establece en true lo que significa que se ha utilizado el índice de cobertura para responder a la consulta.
No sé cuánto se aprecian los índices de cobertura en entornos de producción, pero aparentemente parece ser una buena optimización en caso de que la consulta cumpla con los requisitos.
Índice parcial:
Ya sabemos que los Índices agilizan nuestras consultas a costa del espacio. Cuantos más índices tenga, mayor será el requisito de almacenamiento. Ya hemos creado un índice llamado secondary_idx_1 en la columna name . La columna name puede contener valores grandes de cualquier longitud. También en el índice, los metadatos de los localizadores de fila o punteros de fila tienen su propio tamaño. Entonces, en general, un índice puede tener una alta carga de memoria y almacenamiento.
En MySQL, también es posible crear un índice en los primeros bytes de datos. Ejemplo:el siguiente comando crea un índice en los primeros 4 bytes del nombre. Aunque este método reduce la sobrecarga de memoria en cierta cantidad, el índice no puede eliminar muchas filas, ya que en este ejemplo los primeros 4 bytes pueden ser comunes a muchos nombres. Por lo general, este tipo de indexación de prefijos se admite en CHAR ,VARCHAR , BINARY , VARBINARY tipo de columnas.
CREATE INDEX secondary_index_1 ON index_demo (name(4));¿Qué sucede bajo el capó cuando definimos un índice?
Ejecutemos SHOW EXTENDED comando de nuevo:
SHOW EXTENDED INDEXES FROM index_demo;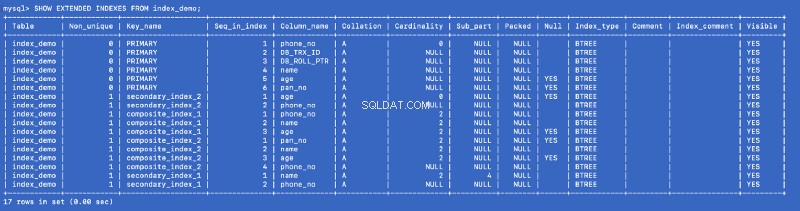
Definimos secondary_index_1 en name , pero MySQL ha creado un índice compuesto en (name , phone_no ) donde phone_no es la columna de clave principal. Creamos secondary_index_2 en age &MySQL creó un índice compuesto en (age , phone_no ). Creamos composite_index_2 en (pan_no , name , age ) &MySQL ha creado un índice compuesto en (pan_no , name , age , phone_no ). El índice compuesto composite_index_1 ya tiene phone_no como parte de ella.
Entonces, sea cual sea el índice que creemos, MySQL en segundo plano crea un índice compuesto de respaldo que, a su vez, apunta a la clave principal. Esto significa que la clave principal es un ciudadano de primera clase en el mundo de la indexación de MySQL. It also proves that all the indexes are backed by a copy of the primary index —but I am not sure whether a single copy of the primary index is shared or different copies are used for different indexes.
There are many other indices as well like Spatial index and Full Text Search index offered by MySQL. I have not yet experimented with those indices, so I’m not discussing them in this post.
General Indexing guidelines:
- Since indices consume extra memory, carefully decide how many &what type of index will suffice your need.
- With
DMLoperations, indices are updated, so write operations are quite costly with indexes. The more indices you have, the greater the cost. Indexes are used to make read operations faster. So if you have a system that is write heavy but not read heavy, think hard about whether you need an index or not. - Cardinality is important — cardinality means the number of distinct values in a column. If you create an index in a column that has low cardinality, that’s not going to be beneficial since the index should reduce search space. Low cardinality does not significantly reduce search space.
Example:if you create an index on a boolean (int1or0only ) type column, the index will be very skewed since cardinality is less (cardinality is 2 here). But if this boolean field can be combined with other columns to produce high cardinality, go for that index when necessary. - Indices might need some maintenance as well if old data still remains in the index. They need to be deleted otherwise memory will be hogged, so try to have a monitoring plan for your indices.
In the end, it’s extremely important to understand the different aspects of database indexing. It will help while doing low level system designing. Many real-life optimizations of our applications depend on knowledge of such intricate details. A carefully chosen index will surely help you boost up your application’s performance.
Please do clap &share with your friends &on social media if you like this article. :)
References:
- https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
- https://www.quora.com/What-is-difference-between-primary-index-and-secondary-index-exactly-And-whats-advantage-of-one-over-another
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html
- https://www.oreilly.com/library/view/high-performance-mysql/0596003064/ch04.html
- https://www.unofficialmysqlguide.com/covering-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/multiple-column-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/show-index.html
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html



