- Resumen de las tablas dinámicas
- Pivotar datos mediante herramientas (dbForge Studio para MySQL)
- Dinamización de datos mediante SQL
- Ejemplo basado en T-SQL para SQL Server
- Ejemplo para MySQL
- Automatizar la rotación de datos, creando consultas dinámicamente
Resumen de las tablas dinámicas
Este artículo trata sobre la transformación de datos de tablas de filas a columnas. Tal transformación se llama tablas dinámicas. A menudo, el resultado del pivote es una tabla de resumen en la que los datos estadísticos se presentan en la forma adecuada o requerida para un informe.
Además, dicha transformación de datos puede ser útil si una base de datos no está normalizada y la información se almacena en ella de forma no óptima. Por lo tanto, al reorganizar la base de datos y transferir datos a nuevas tablas o generar una representación de datos requerida, el pivote de datos puede ser útil, es decir, mover valores de filas a columnas resultantes.
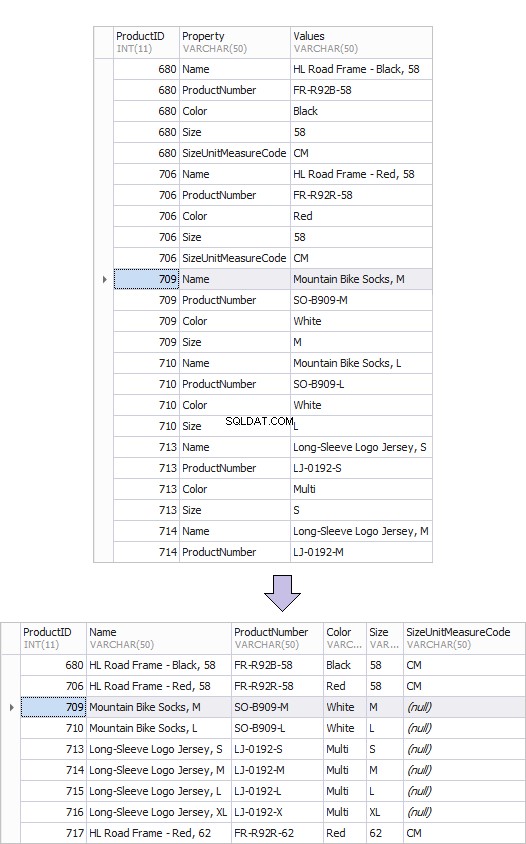
A continuación se muestra un ejemplo de la antigua tabla de productos:ProductsOld y la nueva:ProductsNew. Es a través de la transformación de filas a columnas que tal resultado puede lograrse fácilmente.
Aquí hay un ejemplo de tabla dinámica.
Pivotar datos mediante herramientas (dbForge Studio for MySQL)
Existen aplicaciones que cuentan con herramientas que permiten implementar pivote de datos en un entorno gráfico conveniente. Por ejemplo, dbForge Studio para MySQL incluye la funcionalidad de tablas dinámicas que proporciona el resultado deseado en solo unos pocos pasos.

Veamos el ejemplo con una tabla simplificada de pedidos:PurchaseOrderHeader .
CREATE TABLE PurchaseOrderHeader ( PurchaseOrderID INT(11) NOT NULL, EmployeeID INT(11) NOT NULL, VendorID INT(11) NOT NULL, PRIMARY KEY (PurchaseOrderID) ); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (1, 258, 1580); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (2, 254, 1496); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (3, 257, 1494); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (4, 261, 1650); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (5, 251, 1654); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (6, 253, 1664); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (7, 255, 1678); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (8, 256, 1616); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (9, 259, 1492); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (10, 250, 1602); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (11, 258, 1540); ...
Suponga que necesitamos hacer una selección de la tabla y determinar la cantidad de pedidos realizados por ciertos empleados de proveedores específicos. La lista de empleados, para los cuales se necesita información:250, 251, 252, 253, 254.
Una vista preferida para el informe es la siguiente.
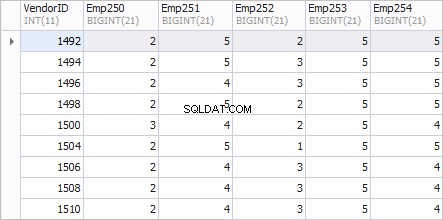
La columna de la izquierda VendorID muestra las identificaciones de los proveedores; columnas Emp250 , Emp251 , Emp252 , Emp253 y Emp254 mostrar el número de pedidos.
Para lograr esto en dbForge Studio para MySQL, necesita:
- Agregue la tabla como fuente de datos para la representación de "tabla dinámica" del documento. En el Explorador de bases de datos, haga clic con el botón derecho en PurchaseOrderHeader tabla y seleccione Enviar a y luego Tabla dinámica en el menú emergente.
- Especifique una columna cuyos valores serán filas. Arrastre el ID de proveedor columna en el cuadro 'Soltar campos de filas aquí'.
- Especifique una columna cuyos valores serán columnas. Arrastre el EmployeeID columna en el cuadro "Soltar campos de columna aquí". También puede establecer un filtro para los empleados requeridos (250, 251, 252, 253, 254).
- Especifique una columna, cuyos valores serán los datos. Arrastre el PurchaseOrderID columna en el cuadro "Soltar elementos de datos aquí".
- En las propiedades del PurchaseOrderID columna, especifique el tipo de agregación:recuento de valores .
Rápidamente obtuvimos el resultado que necesitamos.
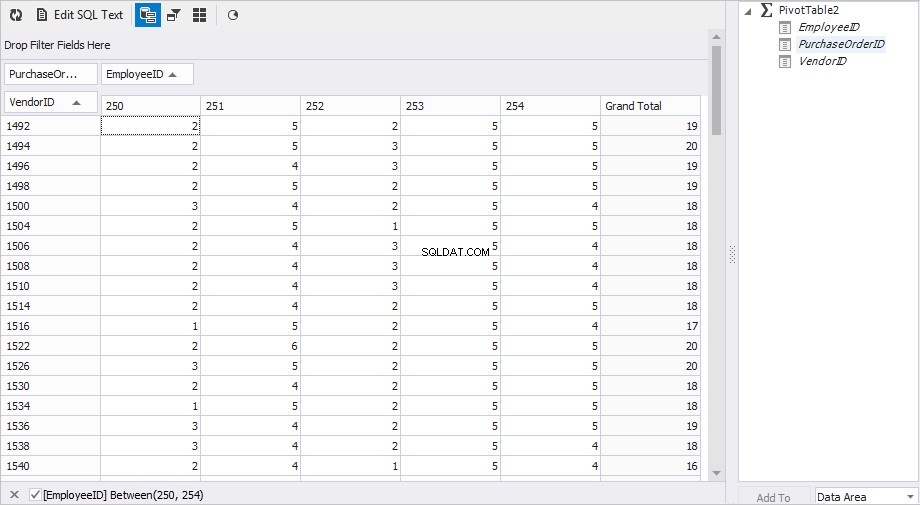
Pivotar datos mediante SQL
Por supuesto, la transformación de datos se puede realizar mediante una base de datos escribiendo una consulta SQL. Pero hay un ligero problema, MySQL no tiene una declaración específica que permita hacer esto.
Ejemplo basado en T-SQL para SQL Server
Por ejemplo, SqlServer y Oracle tienen el operador PIVOT que permite realizar dicha transformación de datos. Si trabajáramos con SqlServer, nuestra consulta se vería así.
SELECT
VendorID
,[250] AS Emp1
,[251] AS Emp2
,[252] AS Emp3
,[253] AS Emp4
,[254] AS Emp5
FROM (SELECT
PurchaseOrderID
,EmployeeID
,VendorID
FROM Purchasing.PurchaseOrderHeader) p
PIVOT
(
COUNT(PurchaseOrderID) FOR EmployeeID IN ([250], [251], [252], [253], [254])
) AS t
ORDER BY t.VendorID;
Ejemplo para MySQL
En MySQL, tendremos que usar los medios de SQL. Los datos deben agruparse por columna de proveedor:ID de proveedor y para cada empleado requerido (EmployeeID ), necesita crear una columna separada con una función agregada.
En nuestro caso, necesitamos calcular la cantidad de pedidos, por lo que usaremos la función agregada COUNT.
En la tabla de origen, la información sobre todos los empleados se almacena en una columna EmployeeID y necesitamos calcular la cantidad de pedidos para un empleado en particular, por lo que debemos enseñar a nuestra función agregada a procesar solo ciertas filas.
La función agregada no tiene en cuenta los valores NULL, y usamos esta peculiaridad para nuestros propósitos.
Puede usar el operador condicional IF o CASE que devolverá un valor específico para el empleado deseado; de lo contrario, simplemente devolverá NULL; como resultado, la función COUNT solo contará valores que no sean NULL.
La consulta resultante es la siguiente:
SELECT VendorID, COUNT(IF(EmployeeID = 250, PurchaseOrderID, NULL)) AS Emp250, COUNT(IF(EmployeeID = 251, PurchaseOrderID, NULL)) AS Emp251, COUNT(IF(EmployeeID = 252, PurchaseOrderID, NULL)) AS Emp252, COUNT(IF(EmployeeID = 253, PurchaseOrderID, NULL)) AS Emp253, COUNT(IF(EmployeeID = 254, PurchaseOrderID, NULL)) AS Emp254 FROM PurchaseOrderHeader p WHERE p.EmployeeID BETWEEN 250 AND 254 GROUP BY VendorID;
O incluso así:
VendorID, COUNT(IF(EmployeeID = 250, 1, NULL)) AS Emp250, COUNT(IF(EmployeeID = 251, 1, NULL)) AS Emp251, COUNT(IF(EmployeeID = 252, 1, NULL)) AS Emp252, COUNT(IF(EmployeeID = 253, 1, NULL)) AS Emp253, COUNT(IF(EmployeeID = 254, 1, NULL)) AS Emp254 FROM PurchaseOrderHeader p WHERE p.EmployeeID BETWEEN 250 AND 254 GROUP BY VendorID;
Cuando se ejecuta, se obtiene un resultado familiar.
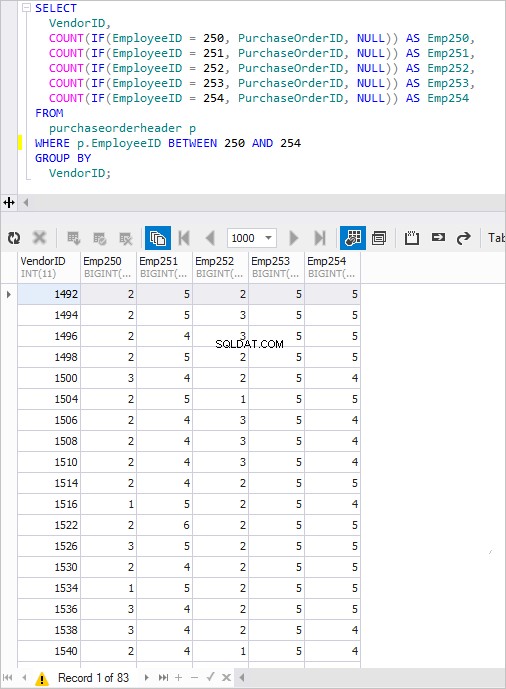
Automatización del pivote de datos, creación de consultas dinámicamente
Como se puede ver, la consulta tiene cierta consistencia, es decir, todas las columnas transformadas se forman de manera similar, y para escribir la consulta, necesita conocer los valores específicos de la tabla. Para formar una consulta dinámica, debe revisar todos los valores posibles y solo entonces debe escribir la consulta. Alternativamente, puede pasar esta tarea a un servidor haciendo que obtenga estos valores y realice dinámicamente la tarea de rutina.
Volvamos al primer ejemplo, en el que formamos la nueva tabla ProductsNew de los ProductosAntiguo mesa. Allí, los valores de las propiedades son limitados y ni siquiera podemos conocer todos los valores posibles; solo tenemos la información de dónde se almacenan los nombres de las propiedades y su valor. Estas son las Propiedades y Valor columnas, respectivamente.
Todo el algoritmo de creación de la consulta SQL se reduce a obtener los valores, a partir de los cuales se formarán nuevas columnas y concatenaciones de partes inalterables de la consulta.
SELECT
GROUP_CONCAT(
CONCAT(
' MAX(IF(Property = ''',
t.Property,
''', Value, NULL)) AS ',
t.Property
)
) INTO @PivotQuery
FROM
(SELECT
Property
FROM
ProductOld
GROUP BY
Property) t;
SET @PivotQuery = CONCAT('SELECT ProductID,', @PivotQuery, ' FROM ProductOld GROUP BY ProductID');
La variable @PivotQuery almacenará nuestra consulta, el texto se ha formateado para mayor claridad.
SELECT ProductID, MAX(IF(Property = 'Color', Value, NULL)) AS Color, MAX(IF(Property = 'Name', Value, NULL)) AS Name, MAX(IF(Property = 'ProductNumber', Value, NULL)) AS ProductNumber, MAX(IF(Property = 'Size', Value, NULL)) AS Size, MAX(IF(Property = 'SizeUnitMeasureCode', Value, NULL)) AS SizeUnitMeasureCode FROM ProductOld GROUP BY ProductID
Luego de ejecutarlo obtendremos el resultado deseado correspondiente al esquema de la tabla ProductsNew.
Además, la consulta de la variable @PivotQuery se puede ejecutar en el script usando la instrucción EXECUTE de MySQL.
PREPARE statement FROM @PivotQuery; EXECUTE statement; DEALLOCATE PREPARE statement;