En un blog anterior, habíamos discutido cómo migrar una configuración independiente de Moodle a una configuración escalable basada en una base de datos agrupada. El siguiente paso en el que deberá pensar es el mecanismo de conmutación por error:¿qué hacer si el servicio de la base de datos falla?
Un servidor de base de datos fallido no es inusual si tiene la replicación de MySQL como su base de datos Moodle backend, y si sucede, deberá encontrar una manera de recuperar su topología, por ejemplo, promoviendo un servidor en espera para convertirse en un nuevo servidor principal. Tener una conmutación por error automática para su base de datos MySQL de Moodle ayuda al tiempo de actividad de la aplicación. Explicaremos cómo funcionan los mecanismos de conmutación por error y cómo incorporar una conmutación por error automática en su configuración.
Arquitectura de alta disponibilidad para base de datos MySQL
La arquitectura de alta disponibilidad se puede lograr agrupando su base de datos MySQL en un par de formas diferentes. Puede usar la replicación de MySQL, configurar múltiples réplicas que sigan de cerca su base de datos principal. Además de eso, puede colocar un balanceador de carga de base de datos para dividir el tráfico de lectura/escritura y distribuir el tráfico entre nodos de lectura-escritura y de solo lectura. La arquitectura de alta disponibilidad de la base de datos que utiliza la replicación de MySQL se puede describir a continuación:
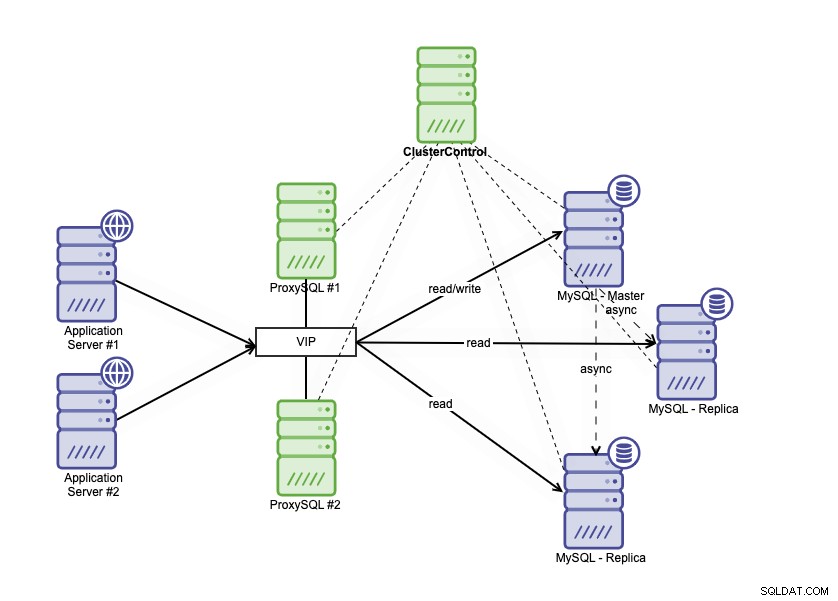
Consta de una base de datos principal, dos réplicas de bases de datos y balanceadores de carga de bases de datos (en este blog, usamos ProxySQL como balanceadores de carga de base de datos) y keepalived como un servicio para monitorear los procesos de ProxySQL. Usamos la dirección IP virtual como una única conexión desde la aplicación. El tráfico se distribuirá al balanceador de carga activo según el indicador de rol en keepalived.
ProxySQL puede analizar el tráfico y comprender si una solicitud es de lectura o escritura. Luego reenviará la solicitud a los hosts apropiados.
Conmutación por error en la replicación de MySQL
Replicación de MySQL utiliza registros binarios para replicar datos desde el principal a las réplicas. Las réplicas se conectan al nodo principal y cada cambio se replica y se escribe en los registros de retransmisión de los nodos de réplica a través de IO_THREAD. Después de que los cambios se almacenen en el registro de retransmisión, el proceso SQL_THREAD continuará con la aplicación de datos en la base de datos de réplica.
La configuración predeterminada para el parámetro read_only en una réplica está activada. Se utiliza para proteger la propia réplica de cualquier escritura directa, por lo que los cambios siempre procederán de la base de datos principal. Esto es importante ya que no queremos que la réplica se separe del servidor principal. El escenario de conmutación por error en la replicación de MySQL ocurre cuando no se puede acceder al primario. Pueden haber muchas razones para esto; por ejemplo, caídas del servidor o problemas de red.
Debe promocionar una de las réplicas a principal, deshabilite el parámetro de solo lectura en la réplica promocionada para que se pueda escribir. También debe cambiar la otra réplica para conectarse a la nueva principal. En el modo GTID, no necesita anotar el nombre del registro binario y la posición desde donde reanudar la replicación. Sin embargo, en la replicación tradicional basada en binlog, definitivamente necesita saber el último nombre de registro binario y la posición desde la cual continuar. La conmutación por error en la replicación basada en binlog es un proceso bastante complejo, pero incluso la conmutación por error en la replicación basada en GTID tampoco es trivial, ya que debe buscar cosas como transacciones erráticas. Detectar una falla es una cosa, y luego reaccionar ante la falla dentro de un breve retraso probablemente no sea posible sin la automatización.
Cómo habilita ClusterControl la conmutación por error automática
ClusterControl tiene la capacidad de realizar una conmutación por error automática para su base de datos MySQL de Moodle. Existe una función de Recuperación automática para clústeres y nodos que activará el proceso de conmutación por error cuando la base de datos principal falle.
Simularemos cómo ocurre la conmutación por error automática en ClusterControl. Haremos que la base de datos principal se bloquee y solo la veremos en el panel de control de ClusterControl. A continuación se muestra la topología actual del clúster:
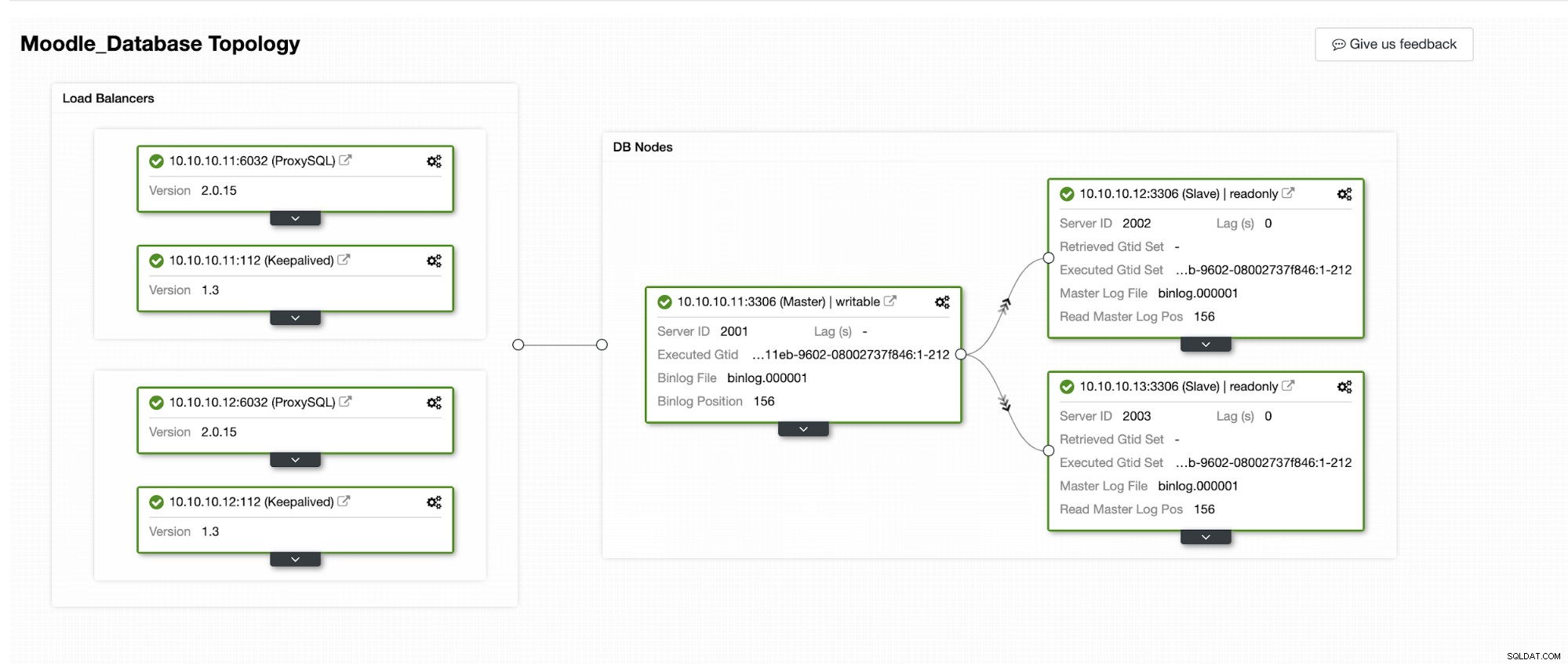
La base de datos primaria usa la dirección IP 10.10.10.11 y las réplicas son:10.10.10.12 y 10.10.10.13. Cuando ocurre el bloqueo en el principal, ClusterControl activa una alerta y se inicia una conmutación por error como se muestra en la siguiente imagen:
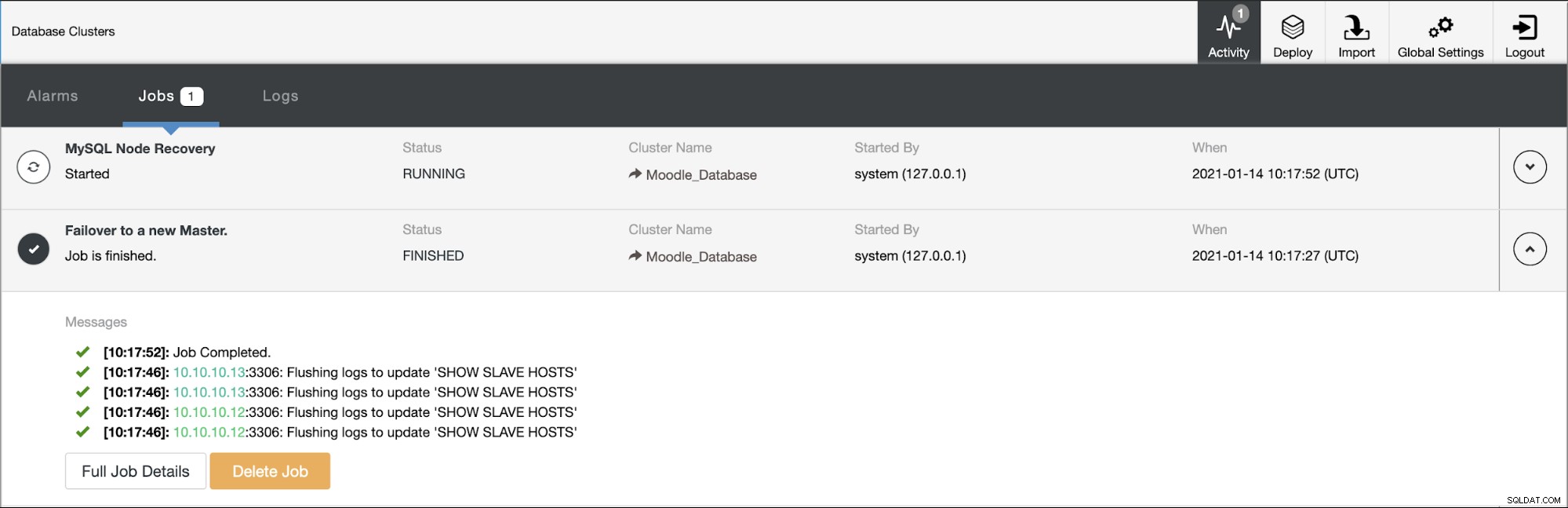
Una de las réplicas se promoverá a principal, lo que dará como resultado la topología como en la siguiente imagen:
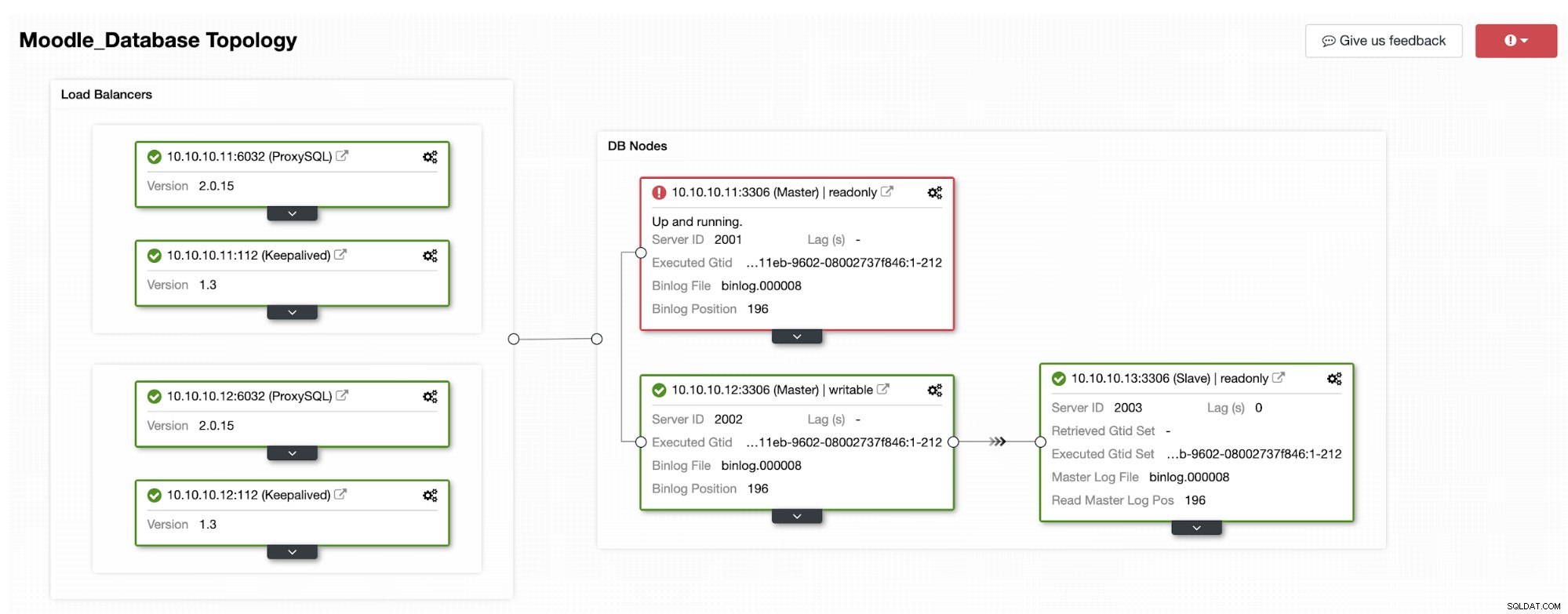
La dirección IP 10.10.10.12 ahora sirve el tráfico de escritura como principal, y también nos quedamos con una sola réplica que tiene la dirección IP 10.10.10.13. En el lado de ProxySQL, el proxy detectará el nuevo primario automáticamente. Hostgroup (HG10) aún atiende el tráfico de escritura que tiene el miembro 10.10.10.12 como se muestra a continuación:

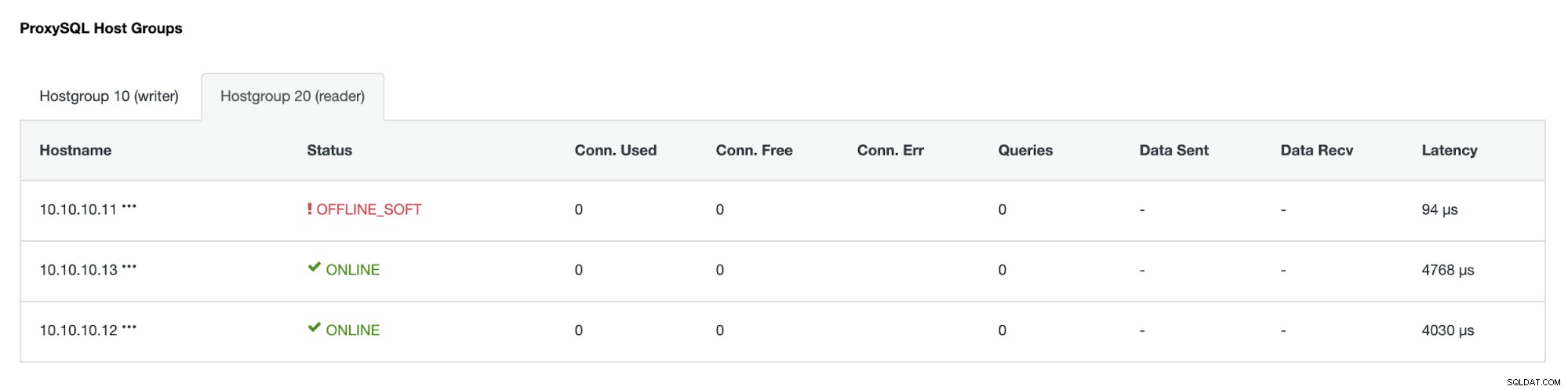
Hostgroup (HG20) todavía puede servir tráfico de lectura, pero como puede ver el nodo 10.10.10.11 está fuera de línea debido al bloqueo:
Una vez que el servidor fallido principal vuelve a estar en línea, no se restablecerá automáticamente -introducido en la topología de la base de datos. Esto es para evitar perder información de solución de problemas, ya que volver a introducir el nodo como una réplica puede requerir sobrescribir algunos registros u otra información. Pero es posible configurar la reincorporación automática del nodo fallido.