En este artículo, continúo explorando soluciones para el desafío de hacer coincidir la oferta con la demanda. Gracias a Luca, Kamil Kosno, Daniel Brown, Brian Walker, Joe Obbish, Rainer Hoffmann, Paul White, Charlie, Ian y Peter Larsson por enviar sus soluciones.
El mes pasado cubrí soluciones basadas en un enfoque de intersecciones de intervalo revisado en comparación con el clásico. La más rápida de esas soluciones combinó ideas de Kamil, Luca y Daniel. Unificó dos consultas con predicados sargables disjuntos. La solución tardó 1,34 segundos en completarse frente a una entrada de 400 000 filas. Eso no está nada mal si se tiene en cuenta que la solución basada en el enfoque clásico de intersecciones de intervalos tardó 931 segundos en completarse con la misma entrada. También recuerde que a Joe se le ocurrió una solución brillante que se basa en el enfoque clásico de intersección de intervalos, pero optimiza la lógica de coincidencia dividiendo los intervalos en cubos en función de la longitud de intervalo más grande. Con la misma entrada de 400 000 filas, la solución de Joe tardó 0,9 segundos en completarse. La parte complicada de esta solución es que su rendimiento se degrada a medida que aumenta la longitud del intervalo más grande.
Este mes exploro soluciones fascinantes que son más rápidas que la solución de intersecciones revisadas de Kamil/Luca/Daniel y son neutrales a la longitud del intervalo. Las soluciones de este artículo fueron creadas por Brian Walker, Ian, Peter Larsson, Paul White y yo.
Probé todas las soluciones de este artículo con la tabla de entrada Subastas con filas de 100 000, 200 000, 300 000 y 400 000, y con los siguientes índices:
-- Index to support solution CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity); -- Enable batch-mode Window Aggregate CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.Auctions(ID) WHERE ID = -1 AND ID = -2;
Al describir la lógica detrás de las soluciones, asumiré que la tabla Subastas se completa con el siguiente pequeño conjunto de datos de muestra:
ID Code Quantity ----------- ---- --------- 1 D 5.000000 2 D 3.000000 3 D 8.000000 5 D 2.000000 6 D 8.000000 7 D 4.000000 8 D 2.000000 1000 S 8.000000 2000 S 6.000000 3000 S 2.000000 4000 S 2.000000 5000 S 4.000000 6000 S 3.000000 7000 S 2.000000
El siguiente es el resultado deseado para estos datos de muestra:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
Solución de Brian Walker
Las uniones externas se usan con bastante frecuencia en las soluciones de consulta SQL, pero cuando las usa, usa las de un solo lado. Cuando enseño sobre uniones externas, a menudo recibo preguntas que piden ejemplos de casos de uso práctico de uniones externas completas, y no hay tantos. La solución de Brian es un hermoso ejemplo de un caso de uso práctico de uniones externas completas.
Aquí está el código completo de la solución de Brian:
DROP TABLE IF EXISTS #MyPairings;
CREATE TABLE #MyPairings
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19,06) NOT NULL
);
WITH D AS
(
SELECT A.ID,
SUM(A.Quantity) OVER (PARTITION BY A.Code
ORDER BY A.ID ROWS UNBOUNDED PRECEDING) AS Running
FROM dbo.Auctions AS A
WHERE A.Code = 'D'
),
S AS
(
SELECT A.ID,
SUM(A.Quantity) OVER (PARTITION BY A.Code
ORDER BY A.ID ROWS UNBOUNDED PRECEDING) AS Running
FROM dbo.Auctions AS A
WHERE A.Code = 'S'
),
W AS
(
SELECT D.ID AS DemandID, S.ID AS SupplyID, ISNULL(D.Running, S.Running) AS Running
FROM D
FULL JOIN S
ON D.Running = S.Running
),
Z AS
(
SELECT
CASE
WHEN W.DemandID IS NOT NULL THEN W.DemandID
ELSE MIN(W.DemandID) OVER (ORDER BY W.Running
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
END AS DemandID,
CASE
WHEN W.SupplyID IS NOT NULL THEN W.SupplyID
ELSE MIN(W.SupplyID) OVER (ORDER BY W.Running
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
END AS SupplyID,
W.Running
FROM W
)
INSERT #MyPairings( DemandID, SupplyID, TradeQuantity )
SELECT Z.DemandID, Z.SupplyID,
Z.Running - ISNULL(LAG(Z.Running) OVER (ORDER BY Z.Running), 0.0) AS TradeQuantity
FROM Z
WHERE Z.DemandID IS NOT NULL
AND Z.SupplyID IS NOT NULL; Revisé el uso original de Brian de tablas derivadas con CTE para mayor claridad.
El CTE D calcula las cantidades acumuladas de demanda total en una columna de resultados denominada D.En ejecución, y la CTE S calcula las cantidades acumuladas de oferta total en una columna de resultados denominada S.En ejecución. El CTE W luego realiza una combinación externa completa entre D y S, haciendo coincidir D.Running con S.Running, y devuelve el primer no NULL entre D.Running y S.Running como W.Running. Este es el resultado que obtiene si consulta todas las filas de W ordenadas por En ejecución:
DemandID SupplyID Running ----------- ----------- ---------- 1 NULL 5.000000 2 1000 8.000000 NULL 2000 14.000000 3 3000 16.000000 5 4000 18.000000 NULL 5000 22.000000 NULL 6000 25.000000 6 NULL 26.000000 NULL 7000 27.000000 7 NULL 30.000000 8 NULL 32.000000
¡La idea de usar una combinación externa completa basada en un predicado que compara los totales acumulados de la oferta y la demanda es genial! La mayoría de las filas en este resultado, las primeras 9 en nuestro caso, representan emparejamientos de resultados a los que les faltan algunos cálculos adicionales. Las filas con ID NULL finales de uno de los tipos representan entradas que no pueden coincidir. En nuestro caso, las últimas dos filas representan entradas de demanda que no pueden coincidir con entradas de oferta. Entonces, lo que queda aquí es calcular DemandID, SupplyID y TradeQuantity de los emparejamientos de resultados, y filtrar las entradas que no se pueden emparejar.
La lógica que calcula el resultado DemandID y SupplyID se realiza en el CTE Z de la siguiente manera (suponiendo que se ordene en W por Ejecución):
- DemandID:si DemandID no es NULL, entonces DemandID; de lo contrario, DemandID mínimo que comienza con la fila actual
- SupplyID:si SupplyID no es NULL, entonces SupplyID; de lo contrario, el SupplyID mínimo comienza con la fila actual
Este es el resultado que obtiene si consulta Z y ordena las filas por Ejecución:
DemandID SupplyID Running ----------- ----------- ---------- 1 1000 5.000000 2 1000 8.000000 3 2000 14.000000 3 3000 16.000000 5 4000 18.000000 6 5000 22.000000 6 6000 25.000000 6 7000 26.000000 7 7000 27.000000 7 NULL 30.000000 8 NULL 32.000000
La consulta externa filtra las filas de Z que representan entradas de un tipo que no pueden coincidir con entradas del otro tipo al garantizar que DemandID y SupplyID no sean NULL. La cantidad comercial de los emparejamientos de resultados se calcula como el valor corriente actual menos el valor corriente anterior usando una función LAG.
Esto es lo que se escribe en la tabla #MyPairings, que es el resultado deseado:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
El plan para esta solución se muestra en la Figura 1.
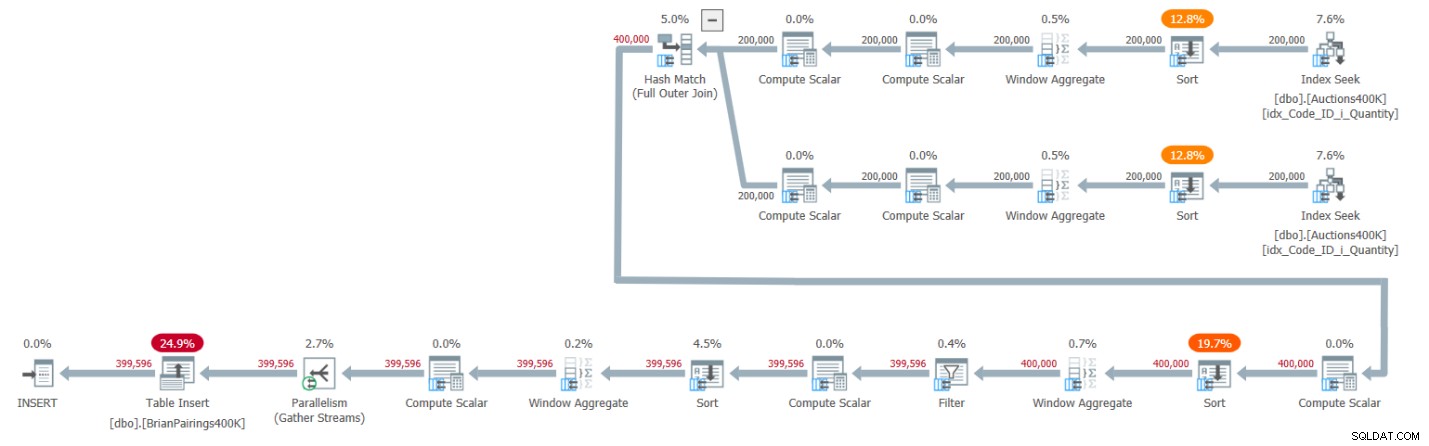 Figura 1:Plan de consulta para la solución de Brian
Figura 1:Plan de consulta para la solución de Brian
Las dos ramas superiores del plan calculan los totales acumulados de la oferta y la demanda utilizando un operador Agregado de ventana en modo por lotes, cada uno después de recuperar las entradas respectivas del índice de soporte. Como expliqué en artículos anteriores de la serie, dado que el índice ya tiene las filas ordenadas como los operadores de ventana agregada necesitan que estén, pensaría que los operadores de clasificación explícitos no deberían ser necesarios. Pero SQL Server actualmente no admite una combinación eficiente de operaciones de índice paralelas que conserven el orden antes de un operador agregado de ventanas en modo por lotes paralelo, por lo que, como resultado, un operador Ordenar paralelo explícito precede a cada uno de los operadores agregados de ventanas paralelos.
El plan utiliza una combinación hash en modo por lotes para manejar la combinación externa completa. El plan también utiliza dos operadores agregados de ventana en modo por lotes precedidos por operadores de clasificación explícitos para calcular las funciones de ventana MIN y LAG.
¡Ese es un plan bastante eficiente!
Estos son los tiempos de ejecución que obtuve para esta solución con tamaños de entrada que van desde 100 000 a 400 000 filas, en segundos:
100K: 0.368 200K: 0.845 300K: 1.255 400K: 1.315
Solución de Itzik
La próxima solución para el desafío es uno de mis intentos de resolverlo. Aquí está el código completo de la solución:
DROP TABLE IF EXISTS #MyPairings;
WITH C1 AS
(
SELECT *,
SUM(Quantity)
OVER(PARTITION BY Code
ORDER BY ID
ROWS UNBOUNDED PRECEDING) AS SumQty
FROM dbo.Auctions
),
C2 AS
(
SELECT *,
SUM(Quantity * CASE Code WHEN 'D' THEN -1 WHEN 'S' THEN 1 END)
OVER(ORDER BY SumQty, Code
ROWS UNBOUNDED PRECEDING) AS StockLevel,
LAG(SumQty, 1, 0.0) OVER(ORDER BY SumQty, Code) AS PrevSumQty,
MAX(CASE WHEN Code = 'D' THEN ID END)
OVER(ORDER BY SumQty, Code
ROWS UNBOUNDED PRECEDING) AS PrevDemandID,
MAX(CASE WHEN Code = 'S' THEN ID END)
OVER(ORDER BY SumQty, Code
ROWS UNBOUNDED PRECEDING) AS PrevSupplyID,
MIN(CASE WHEN Code = 'D' THEN ID END)
OVER(ORDER BY SumQty, Code
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS NextDemandID,
MIN(CASE WHEN Code = 'S' THEN ID END)
OVER(ORDER BY SumQty, Code
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS NextSupplyID
FROM C1
),
C3 AS
(
SELECT *,
CASE Code
WHEN 'D' THEN ID
WHEN 'S' THEN
CASE WHEN StockLevel > 0 THEN NextDemandID ELSE PrevDemandID END
END AS DemandID,
CASE Code
WHEN 'S' THEN ID
WHEN 'D' THEN
CASE WHEN StockLevel <= 0 THEN NextSupplyID ELSE PrevSupplyID END
END AS SupplyID,
SumQty - PrevSumQty AS TradeQuantity
FROM C2
)
SELECT DemandID, SupplyID, TradeQuantity
INTO #MyPairings
FROM C3
WHERE TradeQuantity > 0.0
AND DemandID IS NOT NULL
AND SupplyID IS NOT NULL; El CTE C1 consulta la tabla Subastas y utiliza una función de ventana para calcular las cantidades acumuladas de oferta y demanda totales, llamando a la columna de resultados SumQty.
El CTE C2 consulta a C1 y calcula una serie de atributos utilizando funciones de ventana basadas en la ordenación SumQty y Code:
- StockLevel:el nivel de existencias actual después de procesar cada entrada. Esto se calcula asignando un signo negativo a las cantidades de demanda y un signo positivo a las cantidades de suministro y sumando esas cantidades hasta la entrada actual incluida.
- PrevSumQty:valor SumQty de la fila anterior.
- PrevDemandID:último ID de demanda no NULL.
- PrevSupplyID:último ID de suministro no NULL.
- NextDemandID:siguiente ID de demanda no NULL.
- NextSupplyID:siguiente ID de suministro no NULL.
Aquí está el contenido de C2 ordenado por SumQty y Code:
ID Code Quantity SumQty StockLevel PrevSumQty PrevDemandID PrevSupplyID NextDemandID NextSupplyID ----- ---- --------- ---------- ----------- ----------- ------------ ------------ ------------ ------------ 1 D 5.000000 5.000000 -5.000000 0.000000 1 NULL 1 1000 2 D 3.000000 8.000000 -8.000000 5.000000 2 NULL 2 1000 1000 S 8.000000 8.000000 0.000000 8.000000 2 1000 3 1000 2000 S 6.000000 14.000000 6.000000 8.000000 2 2000 3 2000 3 D 8.000000 16.000000 -2.000000 14.000000 3 2000 3 3000 3000 S 2.000000 16.000000 0.000000 16.000000 3 3000 5 3000 5 D 2.000000 18.000000 -2.000000 16.000000 5 3000 5 4000 4000 S 2.000000 18.000000 0.000000 18.000000 5 4000 6 4000 5000 S 4.000000 22.000000 4.000000 18.000000 5 5000 6 5000 6000 S 3.000000 25.000000 7.000000 22.000000 5 6000 6 6000 6 D 8.000000 26.000000 -1.000000 25.000000 6 6000 6 7000 7000 S 2.000000 27.000000 1.000000 26.000000 6 7000 7 7000 7 D 4.000000 30.000000 -3.000000 27.000000 7 7000 7 NULL 8 D 2.000000 32.000000 -5.000000 30.000000 8 7000 8 NULL
El CTE C3 consulta a C2 y calcula los pares de resultados DemandID, SupplyID y TradeQuantity, antes de eliminar algunas filas superfluas.
El resultado de la columna C3.DemandID se calcula así:
- Si la entrada actual es una entrada de demanda, devuelve DemandID.
- Si la entrada actual es una entrada de suministro y el nivel de existencias actual es positivo, devuelve NextDemandID.
- Si la entrada actual es una entrada de suministro y el nivel de existencias actual no es positivo, devuelva PrevDemandID.
El resultado de la columna C3.SupplyID se calcula así:
- Si la entrada actual es una entrada de suministro, devuelve SupplyID.
- Si la entrada actual es una entrada de demanda y el nivel de existencias actual no es positivo, devuelve NextSupplyID.
- Si la entrada actual es una entrada de demanda y el nivel de existencias actual es positivo, devuelva PrevSupplyID.
El resultado TradeQuantity se calcula como SumQty de la fila actual menos PrevSumQty.
Estos son los contenidos de las columnas relevantes para el resultado de C3:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 2 1000 0.000000 3 2000 6.000000 3 3000 2.000000 3 3000 0.000000 5 4000 2.000000 5 4000 0.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000 7 NULL 3.000000 8 NULL 2.000000
Lo que le queda por hacer a la consulta externa es filtrar las filas superfluas de C3. Estos incluyen dos casos:
- Cuando los totales acumulados de ambos tipos son iguales, la entrada de suministro tiene una cantidad comercial de cero. Recuerde que el pedido se basa en SumQty y Code, por lo que cuando los totales acumulados son iguales, la entrada de demanda aparece antes que la entrada de suministro.
- Entradas finales de un tipo que no pueden coincidir con entradas del otro tipo. Tales entradas están representadas por filas en C3 donde DemandID es NULL o SupplyID es NULL.
El plan para esta solución se muestra en la Figura 2.
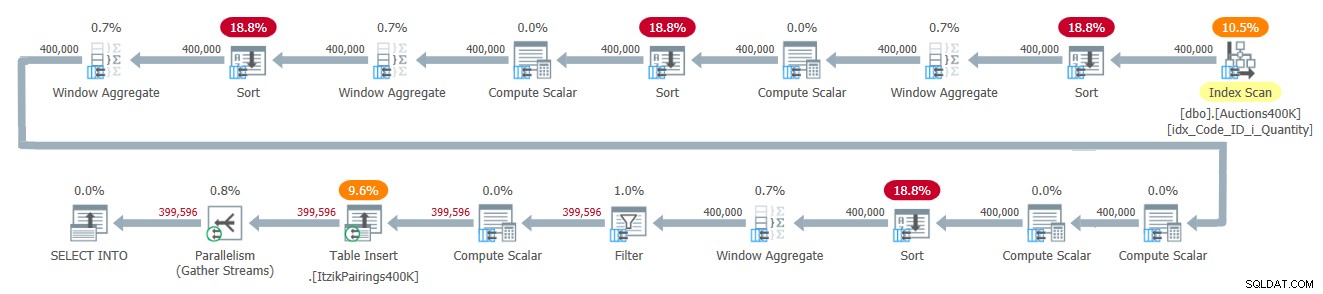 Figura 2:Plan de consulta para la solución de Itzik
Figura 2:Plan de consulta para la solución de Itzik
El plan aplica una pasada sobre los datos de entrada y utiliza cuatro operadores de ventana agregada en modo por lotes para manejar los diversos cálculos de ventana. Todos los operadores de ventana agregada están precedidos por operadores de clasificación explícitos, aunque solo dos de ellos son inevitables aquí. Los otros dos tienen que ver con la implementación actual del operador Agregado de ventanas en modo por lotes paralelo, que no puede depender de una entrada de conservación de orden paralela. Una forma sencilla de ver qué operadores de clasificación se deben a este motivo es forzar un plan en serie y ver qué operadores de clasificación desaparecen. Cuando fuerzo un plan en serie con esta solución, el primer y el tercer operador Ordenar desaparecen.
Estos son los tiempos de ejecución en segundos que obtuve para esta solución:
100K: 0.246 200K: 0.427 300K: 0.616 400K: 0.841>
Solución de Ian
La solución de Ian es corta y eficiente. Aquí está el código completo de la solución:
DROP TABLE IF EXISTS #MyPairings;
WITH A AS (
SELECT *,
SUM(Quantity) OVER (PARTITION BY Code
ORDER BY ID
ROWS UNBOUNDED PRECEDING) AS CumulativeQuantity
FROM dbo.Auctions
), B AS (
SELECT CumulativeQuantity,
CumulativeQuantity
- LAG(CumulativeQuantity, 1, 0)
OVER (ORDER BY CumulativeQuantity) AS TradeQuantity,
MAX(CASE WHEN Code = 'D' THEN ID END) AS DemandID,
MAX(CASE WHEN Code = 'S' THEN ID END) AS SupplyID
FROM A
GROUP BY CumulativeQuantity, ID/ID -- bogus grouping to improve row estimate
-- (rows count of Auctions instead of 2 rows)
), C AS (
-- fill in NULLs with next supply / demand
-- FIRST_VALUE(ID) IGNORE NULLS OVER ...
-- would be better, but this will work because the IDs are in CumulativeQuantity order
SELECT
MIN(DemandID) OVER (ORDER BY CumulativeQuantity
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS DemandID,
MIN(SupplyID) OVER (ORDER BY CumulativeQuantity
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS SupplyID,
TradeQuantity
FROM B
)
SELECT DemandID, SupplyID, TradeQuantity
INTO #MyPairings
FROM C
WHERE SupplyID IS NOT NULL -- trim unfulfilled demands
AND DemandID IS NOT NULL; -- trim unused supplies El código en el CTE A consulta la tabla Subastas y calcula las cantidades totales de oferta y demanda en ejecución usando una función de ventana, nombrando la columna de resultado CumulativeQuantity.
El código en CTE B consulta CTE A y agrupa las filas por CumulativeQuantity. Esta agrupación logra un efecto similar al de la unión externa de Brian en función de los totales acumulados de oferta y demanda. Ian también agregó la expresión ficticia ID/ID al conjunto de agrupación para mejorar la cardinalidad original de la agrupación bajo estimación. En mi máquina, esto también resultó en el uso de un plan paralelo en lugar de uno en serie.
En la lista SELECT, el código calcula DemandID y SupplyID recuperando el ID del tipo de entrada respectivo en el grupo usando el agregado MAX y una expresión CASE. Si el ID no está presente en el grupo, el resultado es NULL. El código también calcula una columna de resultados llamada TradeQuantity como la cantidad acumulada actual menos la anterior, recuperada mediante la función de ventana LAG.
Estos son los contenidos de B:
CumulativeQuantity TradeQuantity DemandId SupplyId ------------------- -------------- --------- --------- 5.000000 5.000000 1 NULL 8.000000 3.000000 2 1000 14.000000 6.000000 NULL 2000 16.000000 2.000000 3 3000 18.000000 2.000000 5 4000 22.000000 4.000000 NULL 5000 25.000000 3.000000 NULL 6000 26.000000 1.000000 6 NULL 27.000000 1.000000 NULL 7000 30.000000 3.000000 7 NULL 32.000000 2.000000 8 NULL
El código en el CTE C luego consulta el CTE B y completa los ID de oferta y demanda NULOS con los siguientes ID de oferta y demanda no NULOS, utilizando la función de ventana MIN con el marco FILAS ENTRE FILA ACTUAL Y SIGUIENTE ILIMITADO.
Estos son los contenidos de C:
DemandID SupplyID TradeQuantity --------- --------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000 7 NULL 3.000000 8 NULL 2.000000
El último paso manejado por la consulta externa contra C es eliminar las entradas de un tipo que no pueden coincidir con las entradas del otro tipo. Eso se hace filtrando las filas donde SupplyID es NULL o DemandID es NULL.
El plan para esta solución se muestra en la Figura 3.
 Figura 3:Plan de consulta para la solución de Ian
Figura 3:Plan de consulta para la solución de Ian
Este plan realiza un escaneo de los datos de entrada y utiliza tres operadores agregados de ventana en modo por lotes paralelos para calcular las diversas funciones de ventana, todos precedidos por operadores de clasificación paralelos. Dos de ellos son inevitables, como puede verificar forzando un plan en serie. El plan también usa un operador Hash Aggregate para manejar la agrupación y agregación en el CTE B.
Estos son los tiempos de ejecución en segundos que obtuve para esta solución:
100K: 0.214 200K: 0.363 300K: 0.546 400K: 0.701
Solución de Peter Larsson
La solución de Peter Larsson es sorprendentemente corta, dulce y altamente eficiente. Aquí está el código completo de la solución de Peter:
DROP TABLE IF EXISTS #MyPairings;
WITH cteSource(ID, Code, RunningQuantity)
AS
(
SELECT ID, Code,
SUM(Quantity) OVER (PARTITION BY Code ORDER BY ID) AS RunningQuantity
FROM dbo.Auctions
)
SELECT DemandID, SupplyID, TradeQuantity
INTO #MyPairings
FROM (
SELECT
MIN(CASE WHEN Code = 'D' THEN ID ELSE 2147483648 END)
OVER (ORDER BY RunningQuantity, Code
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS DemandID,
MIN(CASE WHEN Code = 'S' THEN ID ELSE 2147483648 END)
OVER (ORDER BY RunningQuantity, Code
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS SupplyID,
RunningQuantity
- COALESCE(LAG(RunningQuantity) OVER (ORDER BY RunningQuantity, Code), 0.0)
AS TradeQuantity
FROM cteSource
) AS d
WHERE DemandID < 2147483648
AND SupplyID < 2147483648
AND TradeQuantity > 0.0; CTE cteSource consulta la tabla Subastas y utiliza una función de ventana para calcular las cantidades acumuladas de oferta y demanda totales, llamando a la columna de resultados RunningQuantity.
El código que define la tabla derivada consulta cteSource y calcula los pares de resultados DemandID, SupplyID y TradeQuantity, antes de eliminar algunas filas superfluas. Todas las funciones de ventana utilizadas en esos cálculos se basan en el orden de Cantidad en ejecución y Código.
La columna de resultado d.DemandID se calcula como el ID de demanda mínimo que comienza con el actual o 2147483648 si no se encuentra ninguno.
La columna de resultado d.SupplyID se calcula como el ID de suministro mínimo que comienza con el actual o 2147483648 si no se encuentra ninguno.
El resultado TradeQuantity se calcula como el valor de RunningQuantity de la fila actual menos el valor de RunningQuantity de la fila anterior.
Aquí están los contenidos de d:
DemandID SupplyID TradeQuantity --------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 1000 0.000000 3 2000 6.000000 3 3000 2.000000 5 3000 0.000000 5 4000 2.000000 6 4000 0.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000 7 2147483648 3.000000 8 2147483648 2.000000
Lo que le queda por hacer a la consulta externa es filtrar las filas superfluas de d. Esos son casos en los que la cantidad de negociación es cero, o entradas de un tipo que no pueden coincidir con entradas del otro tipo (con ID 2147483648).
El plan para esta solución se muestra en la Figura 4.
 Figura 4:Plan de consulta para la solución de Peter
Figura 4:Plan de consulta para la solución de Peter
Al igual que el plan de Ian, el plan de Peter se basa en un escaneo de los datos de entrada y utiliza tres operadores agregados de ventana en modo por lotes paralelos para calcular las diversas funciones de ventana, todas precedidas por operadores de clasificación paralelos. Dos de ellos son inevitables, como puede verificar forzando un plan en serie. En el plan de Peter, no hay necesidad de un operador agregado agrupado como en el plan de Ian.
La idea crítica de Peter que permitió una solución tan corta fue darse cuenta de que para una entrada relevante de cualquiera de los tipos, el ID coincidente del otro tipo siempre aparecerá más tarde (según la cantidad en ejecución y el orden del código). ¡Después de ver la solución de Peter, sentí que había complicado demasiado las cosas en la mía!
Estos son los tiempos de ejecución en segundos que obtuve para esta solución:
100K: 0.197 200K: 0.412 300K: 0.558 400K: 0.696
Solución de Paul White
Nuestra última solución fue creada por Paul White. Aquí está el código completo de la solución:
DROP TABLE IF EXISTS #MyPairings;
CREATE TABLE #MyPairings
(
DemandID integer NOT NULL,
SupplyID integer NOT NULL,
TradeQuantity decimal(19, 6) NOT NULL
);
GO
INSERT #MyPairings
WITH (TABLOCK)
(
DemandID,
SupplyID,
TradeQuantity
)
SELECT
Q3.DemandID,
Q3.SupplyID,
Q3.TradeQuantity
FROM
(
SELECT
Q2.DemandID,
Q2.SupplyID,
TradeQuantity =
-- Interval overlap
CASE
WHEN Q2.Code = 'S' THEN
CASE
WHEN Q2.CumDemand >= Q2.IntEnd THEN Q2.IntLength
WHEN Q2.CumDemand > Q2.IntStart THEN Q2.CumDemand - Q2.IntStart
ELSE 0.0
END
WHEN Q2.Code = 'D' THEN
CASE
WHEN Q2.CumSupply >= Q2.IntEnd THEN Q2.IntLength
WHEN Q2.CumSupply > Q2.IntStart THEN Q2.CumSupply - Q2.IntStart
ELSE 0.0
END
END
FROM
(
SELECT
Q1.Code,
Q1.IntStart,
Q1.IntEnd,
Q1.IntLength,
DemandID = MAX(IIF(Q1.Code = 'D', Q1.ID, 0)) OVER (
ORDER BY Q1.IntStart, Q1.ID
ROWS UNBOUNDED PRECEDING),
SupplyID = MAX(IIF(Q1.Code = 'S', Q1.ID, 0)) OVER (
ORDER BY Q1.IntStart, Q1.ID
ROWS UNBOUNDED PRECEDING),
CumSupply = SUM(IIF(Q1.Code = 'S', Q1.IntLength, 0)) OVER (
ORDER BY Q1.IntStart, Q1.ID
ROWS UNBOUNDED PRECEDING),
CumDemand = SUM(IIF(Q1.Code = 'D', Q1.IntLength, 0)) OVER (
ORDER BY Q1.IntStart, Q1.ID
ROWS UNBOUNDED PRECEDING)
FROM
(
-- Demand intervals
SELECT
A.ID,
A.Code,
IntStart = SUM(A.Quantity) OVER (
ORDER BY A.ID
ROWS UNBOUNDED PRECEDING) - A.Quantity,
IntEnd = SUM(A.Quantity) OVER (
ORDER BY A.ID
ROWS UNBOUNDED PRECEDING),
IntLength = A.Quantity
FROM dbo.Auctions AS A
WHERE
A.Code = 'D'
UNION ALL
-- Supply intervals
SELECT
A.ID,
A.Code,
IntStart = SUM(A.Quantity) OVER (
ORDER BY A.ID
ROWS UNBOUNDED PRECEDING) - A.Quantity,
IntEnd = SUM(A.Quantity) OVER (
ORDER BY A.ID
ROWS UNBOUNDED PRECEDING),
IntLength = A.Quantity
FROM dbo.Auctions AS A
WHERE
A.Code = 'S'
) AS Q1
) AS Q2
) AS Q3
WHERE
Q3.TradeQuantity > 0; El código que define la tabla derivada Q1 usa dos consultas separadas para calcular los intervalos de oferta y demanda en función de los totales acumulados y los unifica. Para cada intervalo, el código calcula su inicio (IntStart), final (IntEnd) y longitud (IntLength). Estos son los contenidos de Q1 ordenados por IntStart e ID:
ID Code IntStart IntEnd IntLength ----- ---- ---------- ---------- ---------- 1 D 0.000000 5.000000 5.000000 1000 S 0.000000 8.000000 8.000000 2 D 5.000000 8.000000 3.000000 3 D 8.000000 16.000000 8.000000 2000 S 8.000000 14.000000 6.000000 3000 S 14.000000 16.000000 2.000000 5 D 16.000000 18.000000 2.000000 4000 S 16.000000 18.000000 2.000000 6 D 18.000000 26.000000 8.000000 5000 S 18.000000 22.000000 4.000000 6000 S 22.000000 25.000000 3.000000 7000 S 25.000000 27.000000 2.000000 7 D 26.000000 30.000000 4.000000 8 D 30.000000 32.000000 2.000000
El código que define la tabla derivada Q2 consulta Q1 y calcula las columnas de resultados denominadas DemandID, SupplyID, CumSupply y CumDemand. Todas las funciones de ventana utilizadas por este código se basan en el orden IntStart e ID y el marco FILAS SIN LÍMITES PRECEDENTES (todas las filas hasta la actual).
DemandID es el ID de demanda máxima hasta la fila actual, o 0 si no existe.
SupplyID es el ID de suministro máximo hasta la fila actual, o 0 si no existe ninguno.
CumSupply son las cantidades de suministro acumuladas (longitudes de intervalo de suministro) hasta la fila actual.
CumDemand son las cantidades de demanda acumulada (longitudes de intervalo de demanda) hasta la fila actual.
Estos son los contenidos de Q2:
Code IntStart IntEnd IntLength DemandID SupplyID CumSupply CumDemand ---- ---------- ---------- ---------- --------- --------- ---------- ---------- D 0.000000 5.000000 5.000000 1 0 0.000000 5.000000 S 0.000000 8.000000 8.000000 1 1000 8.000000 5.000000 D 5.000000 8.000000 3.000000 2 1000 8.000000 8.000000 D 8.000000 16.000000 8.000000 3 1000 8.000000 16.000000 S 8.000000 14.000000 6.000000 3 2000 14.000000 16.000000 S 14.000000 16.000000 2.000000 3 3000 16.000000 16.000000 D 16.000000 18.000000 2.000000 5 3000 16.000000 18.000000 S 16.000000 18.000000 2.000000 5 4000 18.000000 18.000000 D 18.000000 26.000000 8.000000 6 4000 18.000000 26.000000 S 18.000000 22.000000 4.000000 6 5000 22.000000 26.000000 S 22.000000 25.000000 3.000000 6 6000 25.000000 26.000000 S 25.000000 27.000000 2.000000 6 7000 27.000000 26.000000 D 26.000000 30.000000 4.000000 7 7000 27.000000 30.000000 D 30.000000 32.000000 2.000000 8 7000 27.000000 32.000000
Q2 already has the final result pairings’ correct DemandID and SupplyID values. The code defining the derived table Q3 queries Q2 and computes the result pairings’ TradeQuantity values as the overlapping segments of the demand and supply intervals. Finally, the outer query against Q3 filters only the relevant pairings where TradeQuantity is positive.
The plan for this solution is shown in Figure 5.
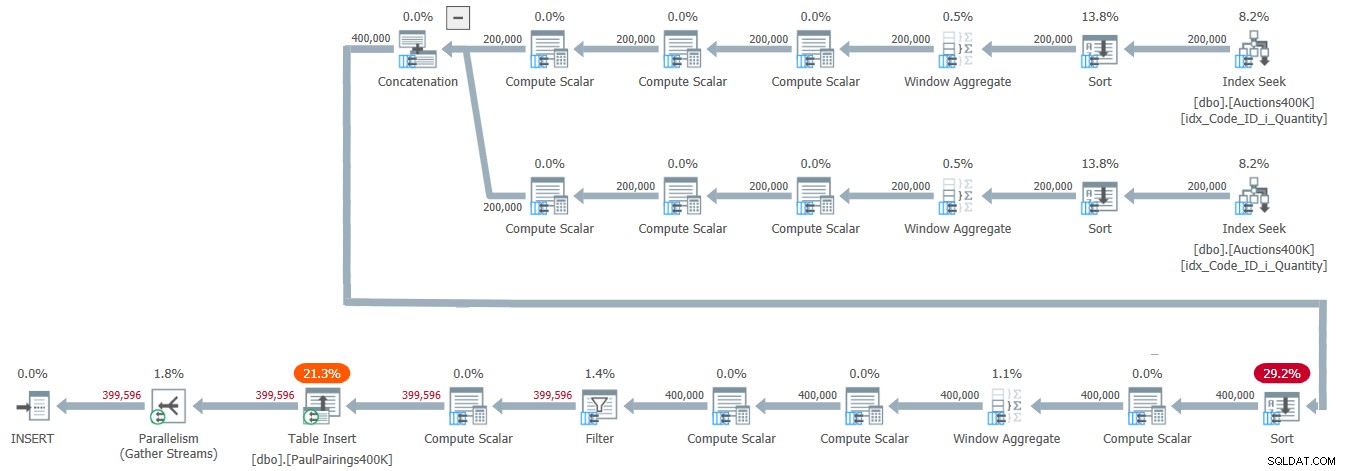 Figure 5:Query plan for Paul’s solution
Figure 5:Query plan for Paul’s solution
The top two branches of the plan are responsible for computing the demand and supply intervals. Both rely on Index Seek operators to get the relevant rows based on index order, and then use parallel batch-mode Window Aggregate operators, preceded by Sort operators that theoretically could have been avoided. The plan concatenates the two inputs, sorts the rows by IntStart and ID to support the subsequent remaining Window Aggregate operator. Only this Sort operator is unavoidable in this plan. The rest of the plan handles the needed scalar computations and the final filter. That’s a very efficient plan!
Here are the run times in seconds I got for this solution:
100K: 0.187 200K: 0.331 300K: 0.369 400K: 0.425
These numbers are pretty impressive!
Performance Comparison
Figure 6 has a performance comparison between all solutions covered in this article.
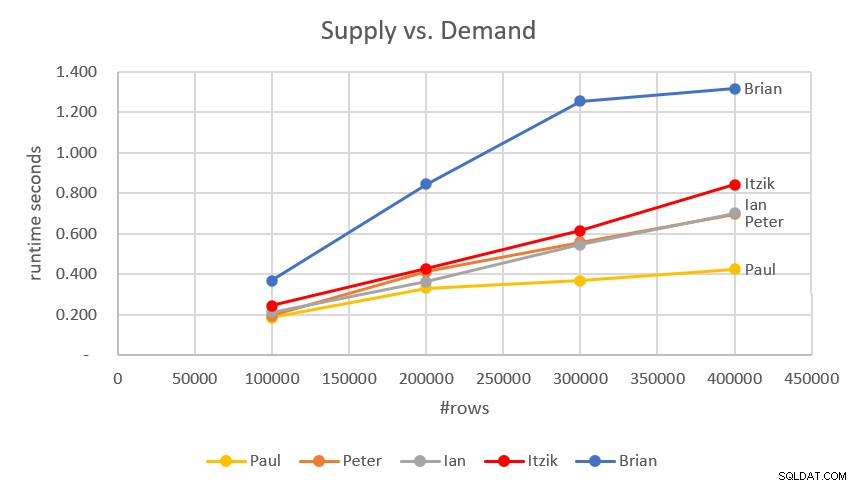 Figure 6:Performance comparison
Figure 6:Performance comparison
At this point, we can add the fastest solutions I covered in previous articles. Those are Joe’s and Kamil/Luca/Daniel’s solutions. The complete comparison is shown in Figure 7.
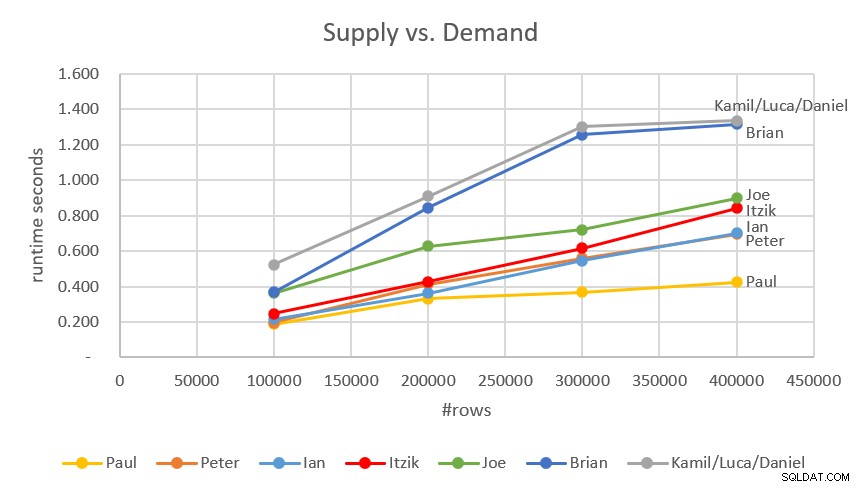 Figure 7:Performance comparison including earlier solutions
Figure 7:Performance comparison including earlier solutions
These are all impressively fast solutions, with the fastest being Paul’s and Peter’s.
Conclusión
When I originally introduced Peter’s puzzle, I showed a straightforward cursor-based solution that took 11.81 seconds to complete against a 400K-row input. The challenge was to come up with an efficient set-based solution. It’s so inspiring to see all the solutions people sent. I always learn so much from such puzzles both from my own attempts and by analyzing others’ solutions. It’s impressive to see several sub-second solutions, with Paul’s being less than half a second!
It's great to have multiple efficient techniques to handle such a classic need of matching supply with demand. Well done everyone!
[ Jump to:Original challenge | Solutions:Part 1 | Part 2 | Part 3 ]


