Primero, es importante saber por cuál de las columnas desea agrupar y cómo desea agruparlas. Necesitará saber eso para configurar la CASE STATEMENT vamos a escribir como una columna en nuestra declaración de selección. En nuestro caso, en un grupo de correos electrónicos que están accediendo a nuestro sitio, queremos saber cuántos clics está contabilizando cada proveedor de correo electrónico desde principios de agosto. También nos gustaría comparar un proveedor de servicios de correo electrónico individual con el resto. Para este ejemplo, vamos a utilizar Gmail como nuestro proveedor de servicios.
En nuestro SELECT declaración, necesitaremos el DATE , el PROVIDER y el SUM de los CLICKS a nuestro sitio. Podemos obtenerlos de TEST E MAILS tabla en nuestra fuente de datos.
La DATE la columna es bastante sencilla:
"Test E Mails"."Created_Date" AS "DATE
Y como estamos buscando el SUM de los CLICKS , tendremos que emitir un SUM función sobre los CLICKS columna.
SUM("Test E Mails"."Clicks") AS "CLICKS"
Eso nos lleva a nuestra CASE STATEMENT . Sabemos por la documentación de PostgreSQL que una DECLARACIÓN DE CASO, o una declaración condicional, debe organizarse de la siguiente manera:
CASE
WHEN condition THEN result
[WHEN ...]
[ELSE result]
END
Nuestra primera y única condición, en este caso, es que queremos saber todas las direcciones de correo electrónico proporcionadas por Gmail para separarlas de cualquier otro proveedor de correo electrónico. Así que el único WHEN es:
WHEN "Test E Mails"."Provider" = 'Gmail' THEN 'Gmail'
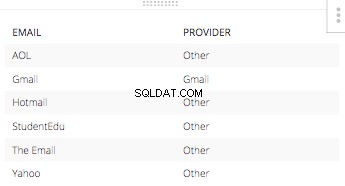
Y, la declaración else sería "Otro" para todos los demás proveedores de direcciones de correo electrónico. La tabla resultante de esta CASE STATEMENT con los correos electrónicos correspondientes solo. Se vería así:
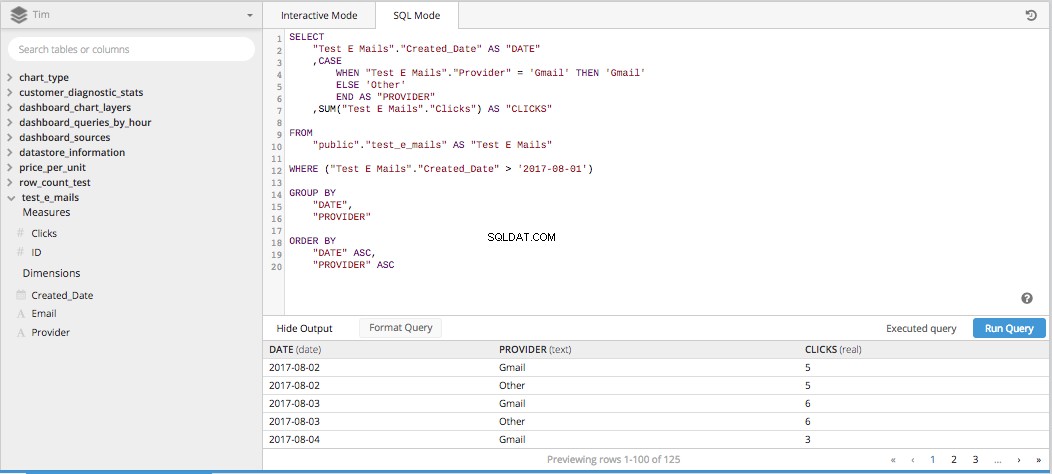
Cuando juntas las tres columnas para una SELECT STATEMENT y agregue el resto de las piezas necesarias para construir una consulta SQL, todo toma forma a continuación.
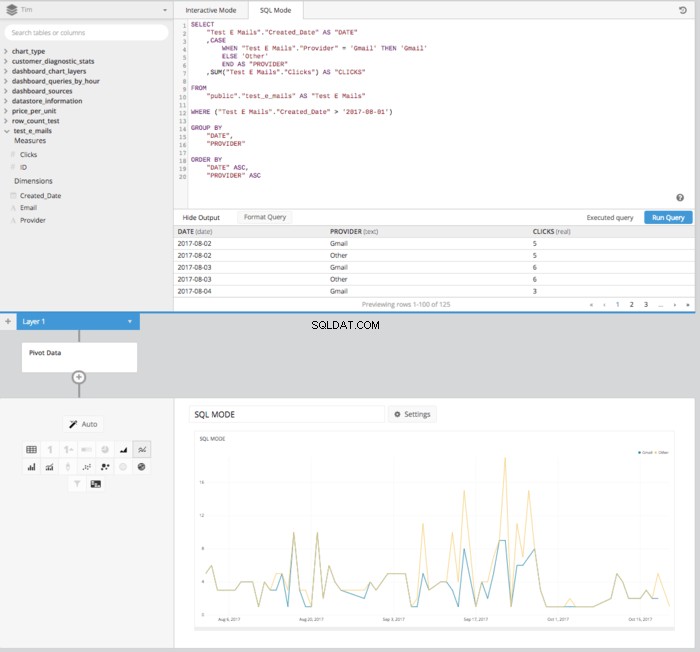
Luego, después de agregar un PIVOT DATA ingrese al canal de datos, obtendremos una tabla organizada correctamente en el formato adecuado para configurar un gráfico de líneas que muestre cómo se comparan los clics a lo largo del tiempo.
Al usar Chartio, podemos hacer todo lo anterior sin escribir ningún SQL pero aprovechando las funciones Data Explorer y Data Pipeline. Después de construir nuestra consulta subyacente para extraer todas las columnas, vamos a necesitar SUM OF CLICKS , DATE y EMAIL ADDRESS podemos usar Data Pipeline para manipular estos datos después de SQL. Primero, construyamos la consulta.
Arrastre la 'Columna de clics' al cuadro de medidas y agréguela por TOTAL SUM de la columna Clics, luego vuelva a etiquetarla como "CLICKS".
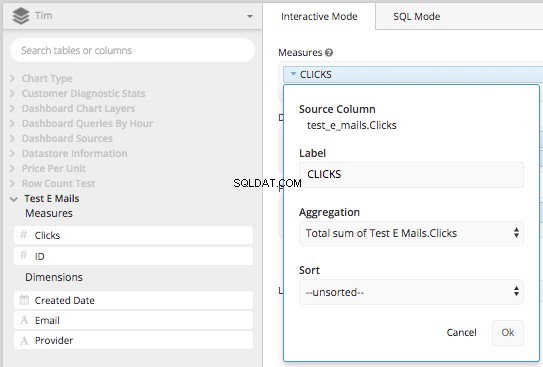
A continuación, arrastre 'Fecha de creación' y 'Proveedor' al cuadro de dimensiones y vuelva a etiquetarlos como 'Fecha' y 'Proveedor de correo electrónico'. Después de eso, utilizando la columna 'Fecha de creación' puede establecer el intervalo de fechas (o crear su WHERE cláusula) para ser todo después de 2017-08-01. Esto construirá efectivamente todo lo que necesitamos en una consulta subyacente para crear la CASE STATEMENT lo hicimos arriba, en Data Pipeline de Chartio.
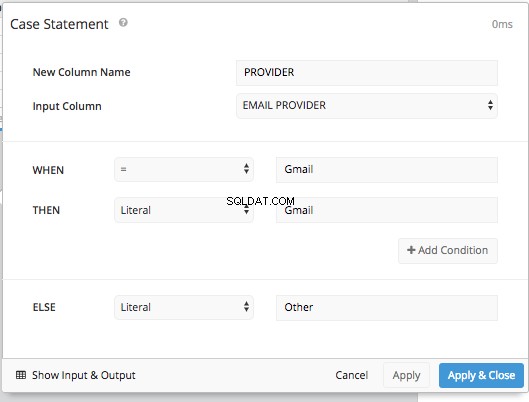
Agregar una CASE STATEMENT El paso de canalización nos permite establecer las condiciones para el WHEN y el ELSE tal como lo hicimos antes, sin tener que escribir toda la sintaxis SQL.
Luego, después de ocultar la columna 'Proveedor' original y usar un REORDER COLUMNS paso y un PIVOT DATA paso obtendremos el mismo arreglo de tablas que obtuvimos en modo SQL y podemos presentar la misma tabla que hicimos en modo SQL.
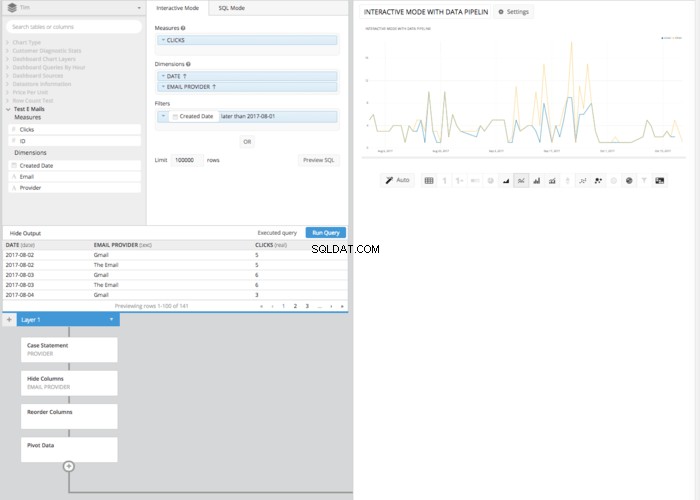
Si bien puede requerir algunos clics y pasos más que en el modo SQL, el gráfico de líneas resultante realizado en el modo interactivo no requiere conocimiento de la sintaxis SQL. En cambio, todo lo que se necesita es una comprensión básica de los principios involucrados. Este es otro ejemplo de cómo Chartio está ayudando a poner el poder de los datos en manos de todos, independientemente del conocimiento de SQL.