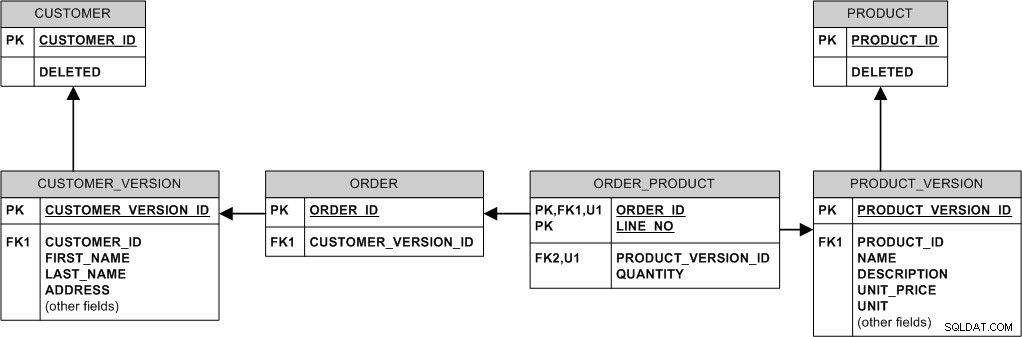
Esta es una forma de hacerlo:
Esencialmente, nunca modificamos ni eliminamos los datos existentes. Lo "modificamos" creando una nueva versión. Lo "eliminamos" configurando el indicador ELIMINADO.
Por ejemplo:
- Si el producto cambia el precio, insertamos una nueva fila en PRODUCT_VERSION mientras que los pedidos anteriores se mantienen conectados al antiguo PRODUCT_VERSION y al precio anterior.
- Cuando el comprador cambia la dirección, simplemente insertamos una nueva fila en CUSTOMER_VERSION y vinculamos nuevos pedidos a ella, mientras mantenemos los pedidos anteriores vinculados a la versión anterior.
- Si se elimina un producto, en realidad no lo eliminamos, simplemente configuramos el indicador PRODUCT.DELETED, de modo que todos los pedidos realizados históricamente para ese producto permanezcan en la base de datos.
- Si se elimina el cliente (p. ej., porque solicitó cancelar su registro), configure el indicador CLIENTE.ELIMINADO.
Advertencias:
- Si el nombre del producto debe ser único, no se puede aplicar mediante declaración en el modelo anterior. Deberá "promocionar" el NOMBRE de PRODUCT_VERSION a PRODUCT, convertirlo en una clave allí y renunciar a la capacidad de "evolucionar" el nombre del producto, o imponer la singularidad solo en el último PRODUCT_VER (probablemente a través de activadores).
- Existe un problema potencial con la privacidad del cliente. Si se elimina un cliente del sistema, puede ser deseable eliminar físicamente sus datos de la base de datos y simplemente configurar CLIENTE.ELIMINADO no lo hará. Si eso le preocupa, borre los datos sensibles a la privacidad en todas las versiones del cliente o, alternativamente, desconecte los pedidos existentes del cliente real y vuelva a conectarlos a un cliente especial "anónimo", luego elimine físicamente todas las versiones del cliente.
Este modelo utiliza muchas relaciones de identificación. Esto conduce a claves foráneas "gordas" y podría ser un problema de almacenamiento ya que MySQL no admite la compresión de índices de vanguardia (a diferencia, por ejemplo, de Oracle), pero por otro lado InnoDB siempre agrupa los datos en PK y este agrupamiento puede ser beneficioso para el rendimiento. Además, los JOIN son menos necesarios.
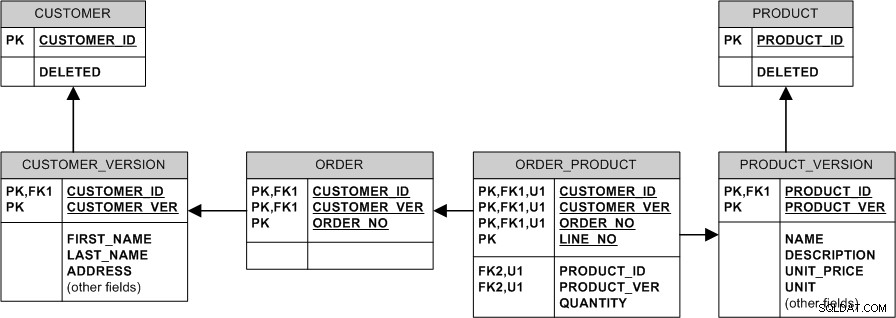
El modelo equivalente con relaciones no identificables y claves sustitutas se vería así: