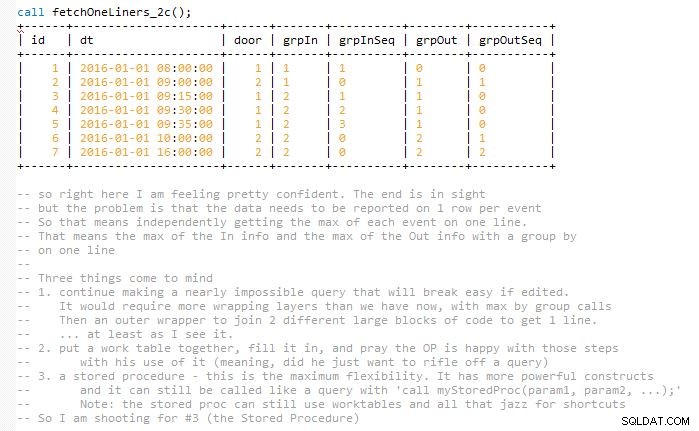
Esto se esfuerza por mantener la solución fácilmente mantenible sin terminar la consulta final de una sola vez, lo que casi habría duplicado su tamaño (en mi opinión). Esto se debe a que los resultados deben coincidir y representarse en una fila con eventos de entrada y salida coincidentes. Entonces, al final, uso algunas mesas de trabajo. Se implementa en un procedimiento almacenado.
El procedimiento almacenado utiliza varias variables que se incorporan con una cross join . Piense en la unión cruzada solo como un mecanismo para inicializar variables. Las variables se mantienen de forma segura, por lo que creo, en el espíritu de este documento
a menudo se hace referencia en las consultas de variables. Las partes importantes de la referencia son el manejo seguro de las variables en una línea, lo que obliga a establecerlas antes de que las usen otras columnas. Esto se logra a través del greatest() y least() funciones que tienen mayor precedencia que las variables que se establecen sin el uso de esas funciones. Tenga en cuenta, también, que coalesce() se utiliza a menudo para el mismo propósito. Si su uso parece extraño, como tomar el mayor de un número que se sabe que es mayor que 0 o 0, eso es deliberado. Deliberado al forzar el orden de precedencia de las variables que se establecen.
Las columnas en la consulta nombraban cosas como dummy2 etc. son columnas en las que no se usó la salida, pero se usaron para establecer variables dentro de, por ejemplo, el greatest() u otro. Esto fue mencionado anteriormente. La salida como 7777 era un marcador de posición en la tercera ranura, ya que se necesitaba algún valor para el if() que fue usado Así que ignora todo eso.
He incluido varias capturas de pantalla del código a medida que avanzaba capa por capa para ayudarlo a visualizar el resultado. Y cómo estas iteraciones de desarrollo se incorporan lentamente a la siguiente fase para expandir la anterior.
Estoy seguro de que mis compañeros podrían mejorar esto en una consulta. Podría haberlo terminado de esa manera. Pero creo que habría resultado en un desastre confuso que se rompería si se tocara.
Esquema:
create table attendance2(Id int, DateTime datetime, Door char(20), Active_door char(20));
INSERT INTO attendance2 VALUES
( 1, '2016-01-01 08:00:00', 'In', ''),
( 2, '2016-01-01 09:00:00', 'Out', ''),
( 3, '2016-01-01 09:15:00', 'In', ''),
( 4, '2016-01-01 09:30:00', 'In', ''),
( 5, '2016-01-01 09:35:00', '', 'On'),
( 6, '2016-01-01 10:00:00', 'Out', ''),
( 7, '2016-01-01 16:00:00', '', 'Off');
drop table if exists oneLinersDetail;
create table oneLinersDetail
( -- architect this depending on multi-user concurrency
id int not null,
dt datetime not null,
door int not null,
grpIn int not null,
grpInSeq int not null,
grpOut int not null,
grpOutSeq int not null
);
drop table if exists oneLinersSummary;
create table oneLinersSummary
( -- architect this depending on multi-user concurrency
id int not null,
grpInSeq int null,
grpOutSeq int null,
checkIn datetime null, -- we are hoping in the end it is not null
checkOut datetime null -- ditto
);
Procedimiento almacenado:
DROP PROCEDURE IF EXISTS fetchOneLiners;
DELIMITER $$
CREATE PROCEDURE fetchOneLiners()
BEGIN
truncate table oneLinersDetail; -- architect this depending on multi-user concurrency
insert oneLinersDetail(id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq)
select id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq
from
( select id,dt,door,
if(@lastEvt!=door and door=1,
greatest(@grpIn:example@sqldat.com+1,0),
7777) as dummy2, -- this output column we don't care about (we care about the variable being set)
if(@lastEvt!=door and door=2,
greatest(@grpOut:example@sqldat.com+1,0),
7777) as dummy3, -- this output column we don't care about (we care about the variable being set)
if (@lastEvt!=door,greatest(@flip:=1,0),least(@flip:=0,1)) as flip,
if (door=1 and @flip=1,least(@grpOutSeq:=0,1),7777) as dummy4,
if (door=1 and @flip=1,greatest(@grpInSeq:=1,0),7777) as dummy5,
if (door=1 and @flip!=1,greatest(@grpInSeq:example@sqldat.comnSeq+1,0),7777) as dummy6,
if (door=2 and @flip=1,least(@grpInSeq:=0,1),7777) as dummy7,
if (door=2 and @flip=1,greatest(@grpOutSeq:=1,0),7777) as dummy8,
if (door=2 and @flip!=1,greatest(@grpOutSeq:example@sqldat.com+1,0),7777) as dummy9,
@grpIn as grpIn,
@grpInSeq as grpInSeq,
@grpOut as grpOut,
@grpOutSeq as grpOutSeq,
@lastEvt:=door as lastEvt
from
( select id,`datetime` as dt,
CASE
WHEN Door='in' or Active_door='on' THEN 1
ELSE 2
END as door
from attendance2
order by id
) xD1 -- derived table #1
cross join (select @grpIn:=0,@grpInSeq:=0,@grpOut:=0,@grpOutSeq:=0,@lastEvt:=-1,@flip:=0) xParams
order by id
) xD2 -- derived table #2
order by id;
-- select * from oneLinersDetail;
truncate table oneLinersSummary; -- architect this depending on multi-user concurrency
insert oneLinersSummary (id,grpInSeq,grpOutSeq,checkIn,checkOut)
select distinct grpIn,null,null,null,null
from oneLinersDetail
order by grpIn;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpIn,max(grpInSeq) m
from oneLinersDetail
where door=1
group by grpIn
) d1
on d1.grpIn=ols.id
set ols.grpInSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpOut,max(grpOutSeq) m
from oneLinersDetail
where door=2
group by grpOut
) d1
on d1.grpOut=ols.id
set ols.grpOutSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=1 and old.grpIn=ols.id and old.grpInSeq=ols.grpInSeq
set ols.checkIn=old.dt;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=2 and old.grpOut=ols.id and old.grpOutSeq=ols.grpOutSeq
set ols.checkOut=old.dt;
-- select * from oneLinersSummary;
-- dump out the results
select id,checkIn,checkOut
from oneLinersSummary
order by id;
-- rows are left in those two tables (oneLinersDetail,oneLinersSummary)
END$$
DELIMITER ;
call fetchOneLiners();
+----+---------------------+---------------------+
| id | checkIn | checkOut |
+----+---------------------+---------------------+
| 1 | 2016-01-01 08:00:00 | 2016-01-01 09:00:00 |
| 2 | 2016-01-01 09:35:00 | 2016-01-01 16:00:00 |
+----+---------------------+---------------------+
Este es el final de la Respuesta. Lo siguiente es para la visualización de un desarrollador de los pasos que llevaron a finalizar el procedimiento almacenado.
Versiones de desarrollo que llevaron hasta el final. Esperemos que esto ayude en la visualización en lugar de simplemente dejar caer un fragmento de código confuso de tamaño mediano.
Paso A
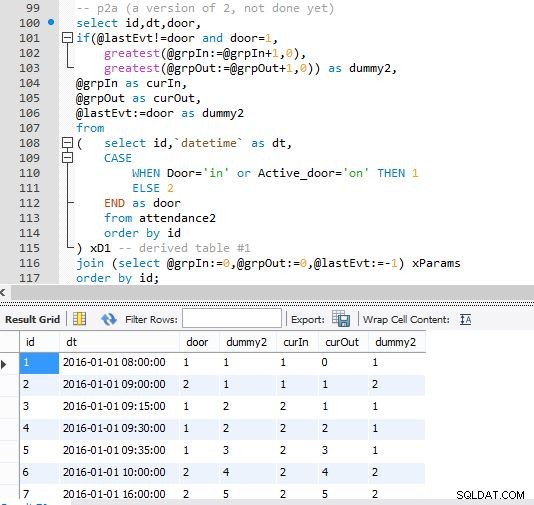
Paso B
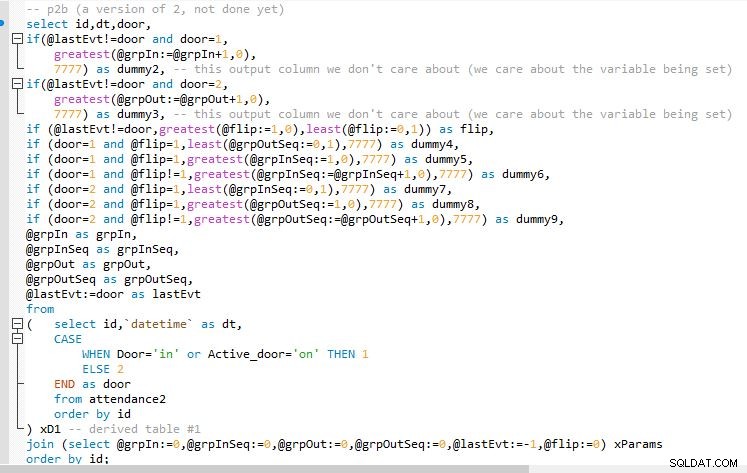
Salida del paso B

Paso C
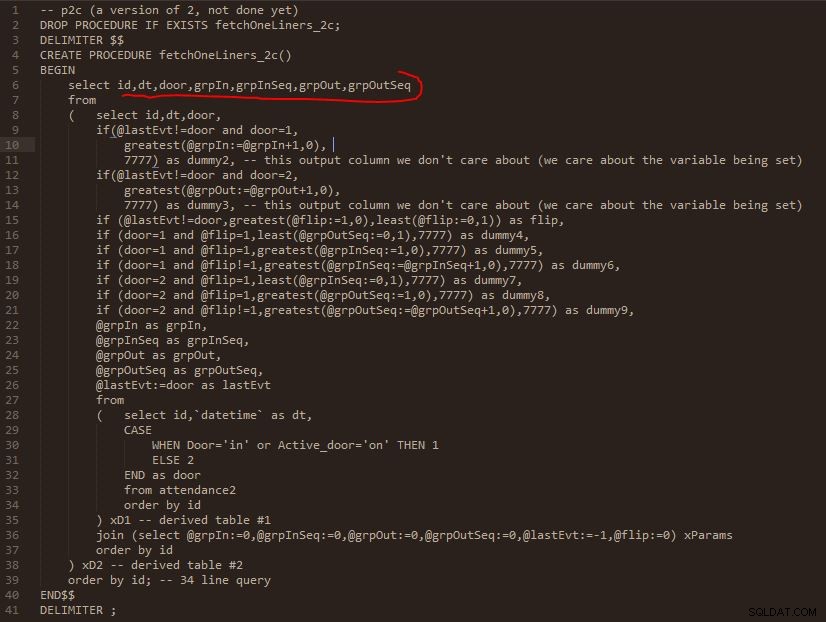
Salida del paso C