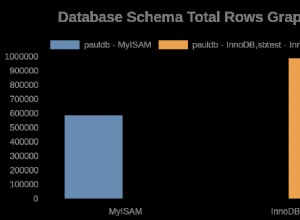
A partir de un cierto número de registros, el IN predicado sobre un SELECT se vuelve más rápido que eso en una lista de constantes.
Consulte este artículo en mi blog para comparar el rendimiento:
Si la columna utilizada en la consulta en IN cláusula está indexada, así:
SELECT *
FROM table1
WHERE unindexed_column IN
(
SELECT indexed_column
FROM table2
)
, entonces esta consulta solo está optimizada para EXISTS (que usa solo una entrada para cada registro de table1 )
Desafortunadamente, MySQL no es capaz de hacer HASH SEMI JOIN o MERGE SEMI JOIN que son aún más eficientes (especialmente si ambas columnas están indexadas).