Supervisar los cambios en el esquema de su base de datos en MySQL/MariaDB brinda una gran ayuda, ya que ahorra tiempo al analizar el crecimiento de su base de datos, los cambios en la definición de la tabla, el tamaño de los datos, el tamaño del índice o el tamaño de las filas. Para MySQL/MariaDB, ejecutar una consulta que haga referencia a information_schema junto con performance_schema le brinda resultados colectivos para un análisis más detallado. El esquema del sistema le proporciona vistas que sirven como métricas colectivas que son muy útiles para realizar un seguimiento de los cambios o la actividad de la base de datos.
Si tiene muchos servidores de bases de datos, sería tedioso ejecutar una consulta todo el tiempo. También tiene que digerir ese resultado en una forma más legible y fácil de entender.
En este blog, crearemos una automatización que sería útil como su herramienta de utilidad para monitorear su base de datos existente y recopilar métricas con respecto a los cambios en la base de datos o las operaciones de cambio de esquema.
Creación de automatización para la comprobación de objetos de esquema de base de datos
En este ejercicio, monitorearemos las siguientes métricas:
-
Sin tablas de claves principales
-
Índices duplicados
-
Generar un gráfico para el número total de filas en nuestros esquemas de base de datos
-
Generar un gráfico para el tamaño total de nuestros esquemas de base de datos
Este ejercicio le dará una idea y puede modificarse para recopilar métricas más avanzadas de su base de datos MySQL/MariaDB.
Uso de Puppet para nuestro IaC y automatización
Este ejercicio usará Puppet para proporcionar automatización y generar los resultados esperados en función de las métricas que queremos monitorear. No cubriremos la instalación y configuración de Puppet, incluidos el servidor y el cliente, así que espero que sepa cómo usar Puppet. Es posible que desee visitar nuestro antiguo blog Implementación automatizada de MySQL Galera Cluster en Amazon AWS con Puppet, que cubre la configuración e instalación de Puppet.
Usaremos la última versión de Puppet en este ejercicio, pero dado que nuestro código consiste en una sintaxis básica, se ejecutaría para versiones anteriores de Puppet.
Servidor de base de datos MySQL preferido
En este ejercicio, usaremos Percona Server 8.0.22-13, ya que prefiero Percona Server principalmente para pruebas y algunas implementaciones menores, ya sea para uso comercial o personal.
Herramienta de gráficos
Hay toneladas de opciones para usar, especialmente en el entorno Linux. En este blog, usaré la herramienta más fácil que encontré y de código abierto https://quickchart.io/.
Juguemos con marionetas
La suposición que he hecho aquí es que ha configurado un servidor maestro con un cliente registrado que está listo para comunicarse con el servidor maestro para recibir implementaciones automáticas.
Antes de continuar, aquí está la información de mi servidor:
Servidor maestro:192.168.40.200
Cliente/Agente Servidor:192.168.40.160
En este blog, nuestro servidor de cliente/agente es donde se ejecuta nuestro servidor de base de datos. En un escenario del mundo real, no tiene que ser especialmente para monitoreo. Siempre que pueda comunicarse con el nodo de destino de forma segura, también es una configuración perfecta.
Configurar el Módulo y el Código
-
Vaya al servidor maestro y en la ruta /etc/puppetlabs/code/environments/production/module, creemos los directorios requeridos para este ejercicio:
mkdir schema_change_mon/{files,manifests}
-
Crea los archivos que necesitamos
touch schema_change_mon/files/graphing_gen.sh
touch schema_change_mon/manifests/init.pp
-
Rellene el script init.pp con el siguiente contenido:
class schema_change_mon (
$db_provider = "mysql",
$db_user = "root",
$db_pwd = "example@sqldat.com",
$db_schema = []
) {
$dbs = ['pauldb', 'sbtest']
service { $db_provider :
ensure => running,
enable => true,
hasrestart => true,
hasstatus => true
}
exec { "mysql-without-primary-key" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"select concat(tables.table_schema,'.',tables.table_name,', ', tables.engine) from information_schema.tables left join ( select table_schema , table_name from information_schema.statistics group by table_schema , table_name , index_name having sum( case when non_unique = 0 and nullable != 'YES' then 1 else 0 end ) = count(*) ) puks on tables.table_schema = puks.table_schema and tables.table_name = puks.table_name where puks.table_name is null and tables.table_type = 'BASE TABLE' and tables.table_schema not in ('performance_schema', 'information_schema', 'mysql');\" >> /opt/schema_change_mon/assets/no-pk.log"
}
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"SELECT concat(t.table_schema,'.', t.table_name, '.', t.index_name, '(', t.idx_cols,')') FROM ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='${db}' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) t JOIN ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='pauldb' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) u where t.table_schema = u.table_schema AND t.table_name = u.table_name AND t.index_name<>u.index_name AND locate(t.idx_cols,u.idx_cols);\" information_schema >> /opt/schema_change_mon/assets/dupe-indexes.log"
}
}
$genscript = "/tmp/graphing_gen.sh"
file { "${genscript}" :
ensure => present,
owner => root,
group => root,
mode => '0655',
source => 'puppet:///modules/schema_change_mon/graphing_gen.sh'
}
exec { "generate-graph-total-rows" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_rows"
}
exec { "generate-graph-total-len" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_len"
}
}
-
Rellene el archivo graphing_gen.sh. Este script se ejecutará en el nodo de destino y generará gráficos para el número total de filas en nuestra base de datos y también el tamaño total de nuestra base de datos. Para este script, hagámoslo más simple y permitamos solo el tipo de bases de datos MyISAM o InnoDB.
#!/bin/bash
graph_ident="${1:-total_rows}"
unset json myisam innodb nmyisam ninnodb; json='' myisam='' innodb='' nmyisam='' ninnodb='' url=''; json=$(MYSQL_PWD="example@sqldat.com" mysql -uroot -Nse "select json_object('dbschema', concat(table_schema,' - ', engine), 'total_rows', sum(table_rows), 'total_len', sum(data_length+data_length), 'fragment', sum(data_free)) from information_schema.tables where table_schema not in ('performance_schema', 'sys', 'mysql', 'information_schema') and engine in ('myisam','innodb') group by table_schema, engine;" | jq . | sed ':a;N;$!ba;s/\n//g' | sed 's|}{|},{|g' | sed 's/^/[/g'| sed 's/$/]/g' | jq '.' ); innodb=""; myisam=""; for r in $(echo $json | jq 'keys | .[]'); do if [[ $(echo $json| jq .[$r].'dbschema') == *"MyISAM"* ]]; then nmyisam=$(echo $nmyisam || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; myisam=$(echo $myisam || echo '')$(echo $json| jq .[$r].'dbschema')','; else ninnodb=$(echo $ninnodb || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; innodb=$(echo $innodb || echo '')$(echo $json| jq .[$r].'dbschema')','; fi; done; myisam=$(echo $myisam|sed 's/,$//g'); nmyisam=$(echo $nmyisam|sed 's/,$//g'); innodb=$(echo $innodb|sed 's/,$//g');ninnodb=$(echo $ninnodb|sed 's/,$//g'); echo $myisam "|" $nmyisam; echo $innodb "|" $ninnodb; url=$(echo "{type:'bar',data:{labels:['MyISAM','InnoDB'],datasets:[{label:[$myisam],data:[$nmyisam]},{label:[$innodb],data:[$ninnodb]}]},options:{title:{display:true,text:'Database Schema Total Rows Graph',fontSize:20,}}}"); curl -L -o /vagrant/schema_change_mon/assets/db-${graph_ident}.png -g https://quickchart.io/chart?c=$(python -c "import urllib,os,sys; print urllib.quote(os.environ['url'])")
-
Por último, vaya al directorio de ruta del módulo o /etc/puppetlabs/code/environments /producción en mi configuración. Vamos a crear el archivo manifests/schema_change_mon.pp.
touch manifests/schema_change_mon.pp-
Luego llene el archivo manifests/schema_change_mon.pp con los siguientes contenidos,
node 'pupnode16.puppet.local' { # Applies only to mentioned node. If nothing mentioned, applies to all.
class { 'schema_change_mon':
}
}
Si ha terminado, debería tener la siguiente estructura de árbol como la mía,
example@sqldat.com:/etc/puppetlabs/code/environments/production/modules# tree schema_change_mon
schema_change_mon
├── files
│ └── graphing_gen.sh
└── manifests
└── init.pp¿Qué hace nuestro módulo?
Nuestro módulo, que se llama schema_change_mon, recopila lo siguiente,
exec { "mysql-without-primary-key" :Que ejecuta un comando mysql y ejecuta una consulta para recuperar tablas sin claves primarias. Entonces,
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :que recopila índices duplicados que existen en las tablas de la base de datos.
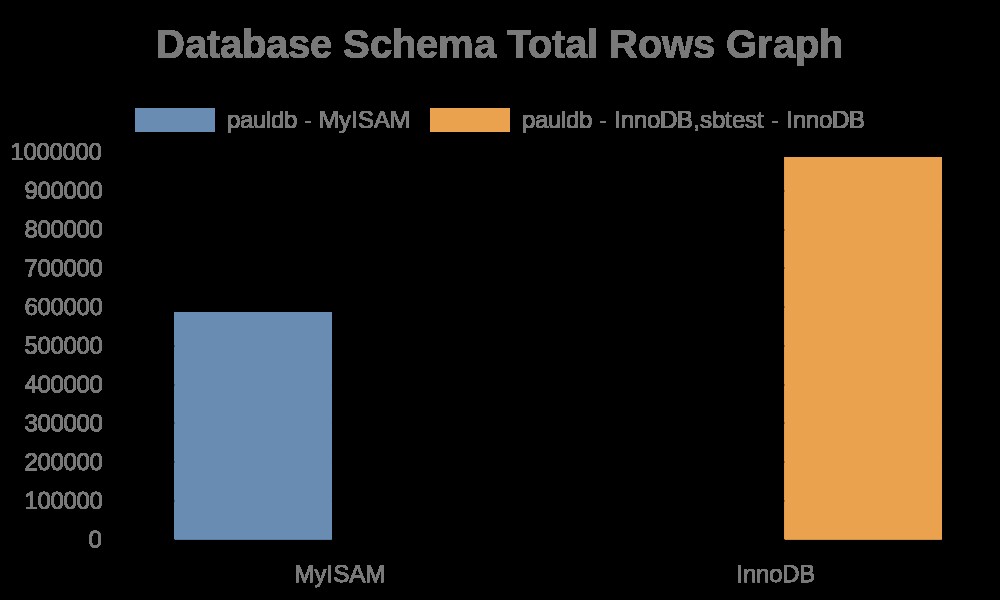
Luego, las líneas generan gráficos basados en las métricas recolectadas. Estas son las siguientes líneas,
exec { "generate-graph-total-rows" :
...
exec { "generate-graph-total-len" :
…Una vez que la consulta se ejecuta correctamente, genera el gráfico, que depende de la API proporcionada por https://quickchart.io/.
Aquí están los siguientes resultados del gráfico:
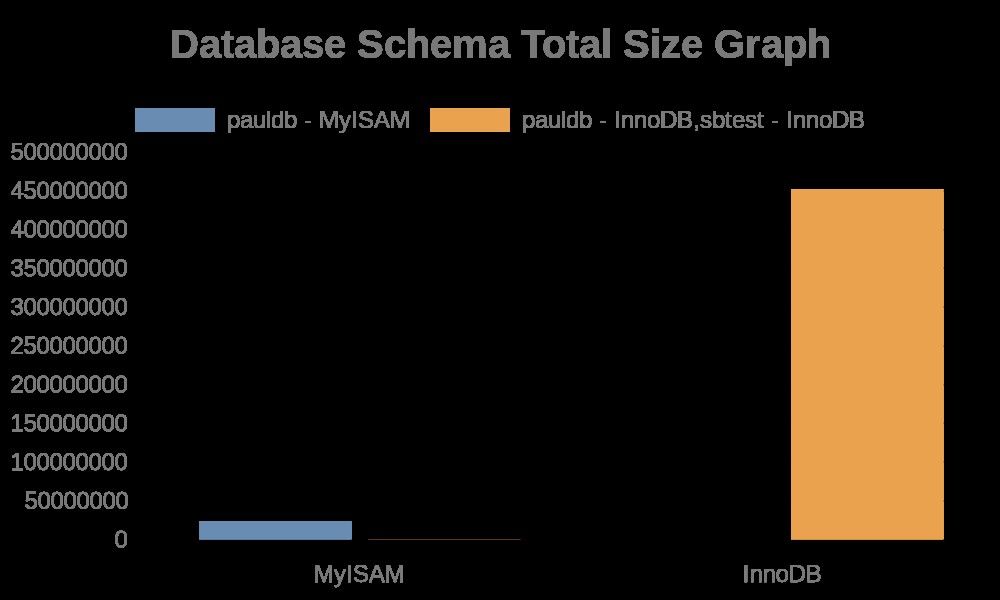
Mientras que los registros de archivo simplemente contienen cadenas con sus nombres de tabla, nombres de índice. Vea el resultado a continuación,
example@sqldat.com:~# tail -n+1 /opt/schema_change_mon/assets/*.log
==> /opt/schema_change_mon/assets/dupe-indexes.log <==
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
==> /opt/schema_change_mon/assets/no-pk.log <==
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDB
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDB¿Por qué no usar ClusterControl?
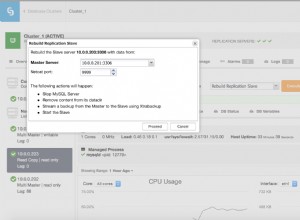
Como nuestro ejercicio muestra la automatización y la obtención de estadísticas del esquema de la base de datos, como cambios u operaciones, ClusterControl también proporciona esto. Hay otras características además de esto y no es necesario reinventar la rueda. ClusterControl puede proporcionar los registros de transacciones, como interbloqueos, como se muestra arriba, o consultas de ejecución prolongada, como se muestra a continuación:
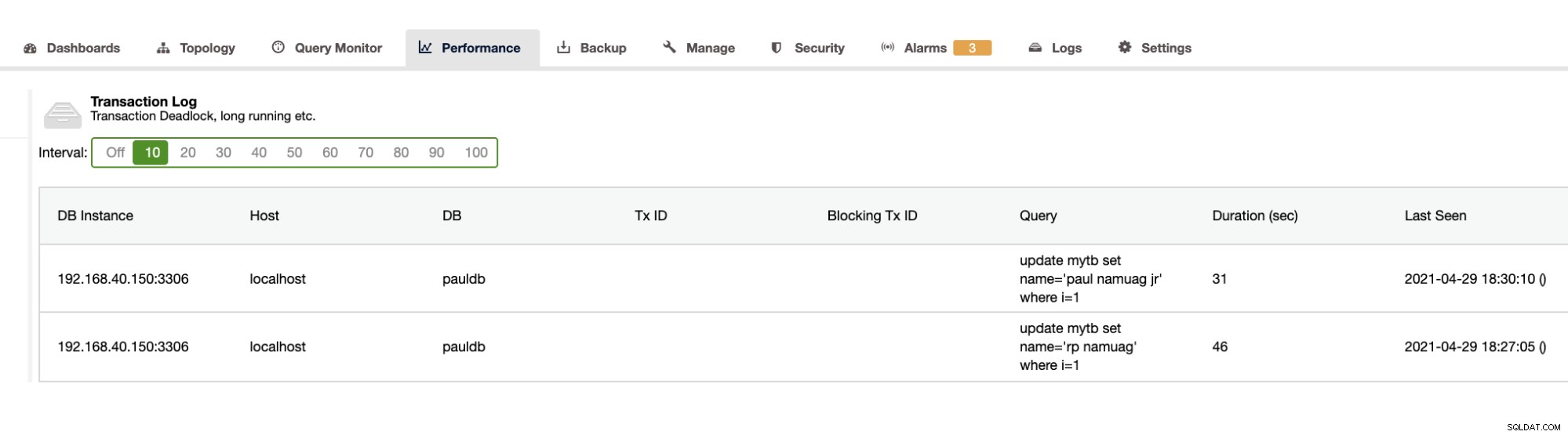
ClusterControl también muestra el crecimiento de la base de datos como se muestra a continuación,
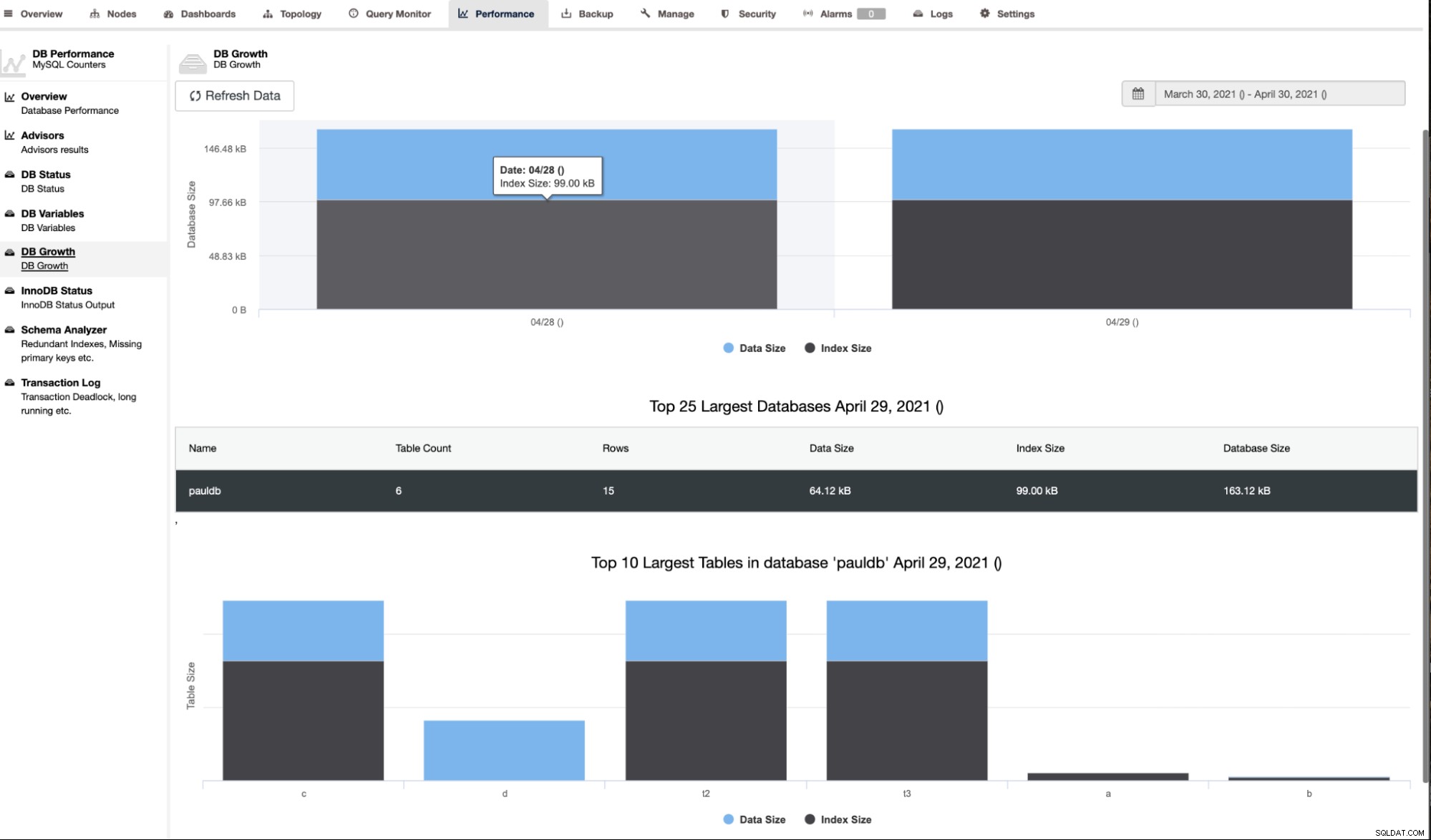
ClusterControl también brinda información adicional, como el número de filas, el tamaño del disco, el tamaño del índice y el tamaño total.
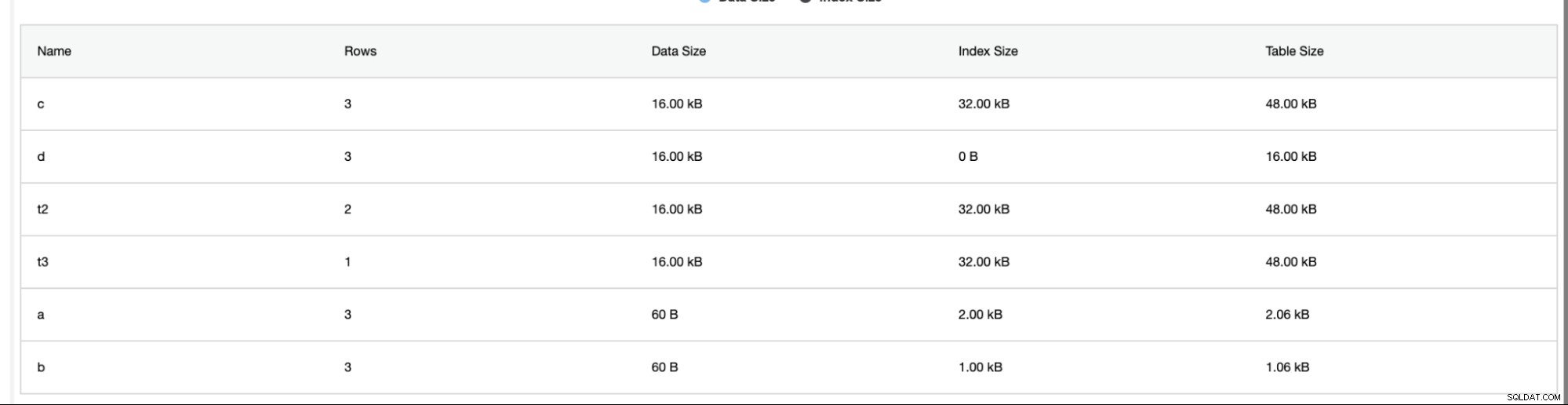
El analizador de esquemas en la pestaña Rendimiento -> Analizador de esquemas es muy útil. Proporciona tablas sin claves primarias, tablas MyISAM e índices duplicados,

También proporciona alarmas en caso de que se detecten índices duplicados o tablas sin primario teclas como las siguientes,

Puede consultar más información sobre ClusterControl y sus otras características en la página de nuestro Producto.
Conclusión
Ofrecer automatización para monitorear los cambios de su base de datos o cualquier estadística de esquema como escrituras, índices duplicados, actualizaciones de operaciones como cambios de DDL y muchas actividades de la base de datos es muy beneficioso para los administradores de bases de datos. Ayuda a identificar rápidamente los enlaces débiles y las consultas problemáticas que le brindarían una descripción general de una posible causa de consultas incorrectas que bloquearían su base de datos o la dejarían obsoleta.